6 min to read
BERT, Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
양방향 Encoder Representation인 Transformer에 기반한 새로운 모델 BERT를 소개합니다. BERT는 라벨이 없는 텍스트에서 양방향 Representation을 사전 학습 하도록 설계되었습니다. 이를 통해 특정 Task에 맞게 fine-tuning하여, 레이어를 추가하면서 모델을 만들 수 있습니다.
1. Introduction
사전 학습된 언어 모델들이 NLP task의 성능을 향상시키는데에 탁월한 효과가 있다고 증명되었습니다.
추론 등의 sentence-level tasks와 개체명 인식과 같은 token-level tasks에서 말입니다.
사전 학습된 language representations을 적용을 위해서는 2가지의 방법이 있습니다.
하나는 feature-based 방법이고, 나머지는 fine-tuning 방법입니다.
우선 feature-based 방법의 경우 ELMo와 같이 사전 학습된 representation를 사용하지만,
task에 적합한 새로운 아키텍쳐를 추가로 사용해서 task를 해결합니다.
즉 사전 학습을 통해 language representations feature만 사용합니다.
그와 다르게 OpenAI의 GPT같은 fine-tuning 방법의 경우, task에 맞게 새로운 task-specific한 parameter를 사용합니다.
이 parameter들은 각 task를 학습하기 위해, 사전 학습한 parameter를 사용해 fine-tuning 하는 방법입니다.
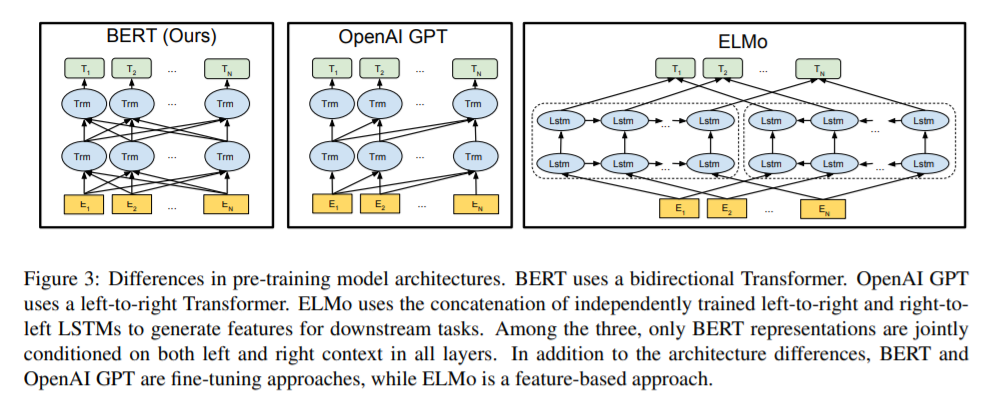
이러한 두 방법 모두 같은 목적 함수를 사용해 사전 학습하지만, 모두 단방향의 language model을 사용해서 language representations을 학습합니다. 하지만 이러한 기존의 ELMo와 GPT 같은 모델의 경우, 모델의 방향이 단방향이기 떄문에 사전학습 중 사용될 수 있는 아키텍쳐의 선택을 제한한다는 단점이 있습니다.
예를 들어 GPT의 경우 텍스트에서 왼쪽에서 오른쪽으로만 참고할 수 있는 구조를 취하고 있습니다.

그림처럼 ELMo의 경우, 양쪽 방향의 언어 모델을 둘 다 활용하여 biLM(Bidirectional Language Model)인 줄 알았습니다. 하지만 논문에서 단방향 모델로 소개가 되었는데, 이는 단순히 각각의 방향의 언어 모델을 순차적으로 학습시킨 후, concatenate 하기 때문에 단방향 모델로 소개되어진 듯 합니다.
따라서 fine-tuning 기반의 BERT는 기존과 다르게 임베딩 과정에서 어떻게 양방향으로 사전 학습을 시키는지가 핵심입니다.
BERT는 단뱡향의 문제점을 해결하기 위해 MLM(masked language-model) 통해 사전학습을 진행하게 됩니다.
MLM은 랜덤하게 input token의 일부를 mask시키고, left와 right의 문맥들을 모두 이용하여 masking된 token들을 예측하는 방향으로 학습하게 됩니다. GPT도 이와 유사하게 학습하지만, left 문맥들만 참고하여 예측합니다. (left-to-right)
이러한 기존의 left-to-right 의 방향으로 가는 단방향 모델들과 달리, MLM은 deep bidirectional Transformer를 학습시킬 수 있습니다. 또한 next sentence prediction task를 사전학습 과정에서 같이 사용합니다.
next sentence prediction: Next 문장이 Previous 문장 다음에 오는 것이 맞는지 예측하는 문제입니다.
논문이 기여하는 바는 아래와 같습니다.
- language representations을 위해 양방향으로 사전 학습하는 것의 중요성을 증명
- 사전학습 되어진 representations들을 통해, 고수준의 engeering이 요구되는 아키텍쳐를 사용할 필요성을 감소
- NLP 내 11개의 task들에서 SOTA성능을 향상
2. Related Work
기존의 사전학습 되어진 language representation들을 살펴보고, 많이 사용되는 방법이 어떤 것인지 간단히 소개합니다. Feature-based Approaches, Fine-tuning Approaches, Transfer Learning from Supervised Data의 방법들을 소개합니다. 예시로는 ELMo, GPT와 같은 모델이 존재하고, 앞에서 충분히 소개하였기 때문에 생략하도록 하겠습니다.
3. BERT
3.0.1 Model Architecture
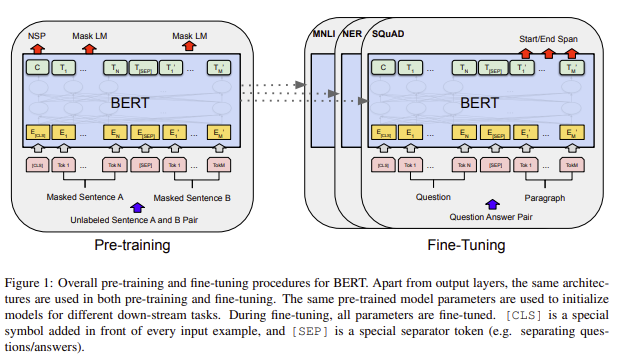
BERT에는 pre-training, fine-tuning을 과정을 거치는 두 단계가 있습니다.
pre-training 과정에는 라벨이 없는 데이터로부터 사전학습을 진행합니다.
다음 fine-tunning 과정에서는 먼저 사전학습 시킨 파라미터로 초기화 시킨 후에, supervised-learning task에 맞도록 fine-tunning을 진행하는 downstram task가 진행되어집니다.
BERT의 모델 구조는 multi layer의 양방향 Transformer Encoder를 기반으로 한 구조입니다. 자세한 내용은 tensor2tensor의 transformer를 참고 바랍니다.
BERT는 모델의 크기에 따라 base 모델과 large 모델을 제공합니다.
- $BERT_{base}$ : L=12, H=768, A=12, Total Parameters = 110M
- $BERT_{large}$ : L=24, H=1024, A=16, Total Parameters = 340M
L: Transformer block의 layer의 수
H: hidden size
A: self-attention의 head 수
4H: Transformer의 feed-forward layer의 첫번째 layer의 unit 수
$BERT_{base}$의 경우, 비교를 위해 GPT 모델과 같은 크기로 설정되었는데, 차이점을 다시 한번 언급하면 BERT Transformer는 양방향 에서 self-attention이 이루어지고, GPT Transformer는 left 방향에서만 self-attention이 이루어집니다.
3.0.2 Input/Output Representations
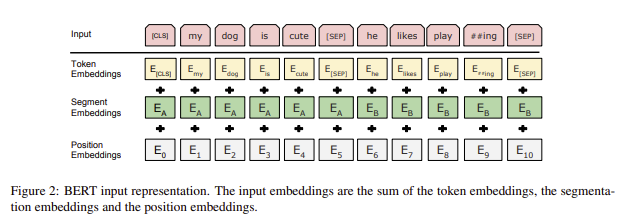
다양한 downstream task를 처리하기 위해서는 입력의 형태가 명확해야 합니다. sequence 란 BERT에 대한 입력 token sequence를 나타내며, 단일 문장이나 또는 두 문장이 함께 나올 수 있습니다.(e.g. QA)
BERT의 입력값들은 아래와 같은 특징을 갖습니다.
- 30,000개의 token vocabulary를 가지는 WordPiece 임베딩 값을 사용하였습니다.
-
모든 sequence의 첫 번쨰 token은
special classification token([CLS])입니다. 해당 token의 마지막 hidden state값은 분류 task에 사용되며, 분류 task가 아닐 경우 무시합니다. - Sentence pairs들은 하나의 sequence로 나타내어 집니다. 따라서 sentences를 구분하기 위해 두가지의 단계를 수행합니다.
- 먼저 sequence를
special token ([SEP])으로 구분합니다. - 각 token들이 어느 sentence에 속하였는지 나타내기 위해 Segment Embedding 을 추가해줍니다.
- 먼저 sequence를
3.1 Pre-training BERT
BERT는 기존의 left-to-right, right-to-left 기반의 모델을 사용하지 않고 2가지의 새로운 unsupervised prediction task로 pre-training을 수행합니다.
3.1.1 Task #1: Masked LM
직관적으로 양방향 모델이 기존의 left-to-right, right-to-left 모델보다 훨씬 더 좋다는 것은 합리적입니다. 하지만 양방향으로 바라보게 될 떄, 각 단어가 간접적으로 자기 자신 즉 ‘see itself’ 을 보면서, 모델이 multi-layered context 안에서 타겟 단어를 예측할 때 영향을 끼친다는 것입니다.
설명할 수 있는 좋은 그림이 있어 첨부합니다
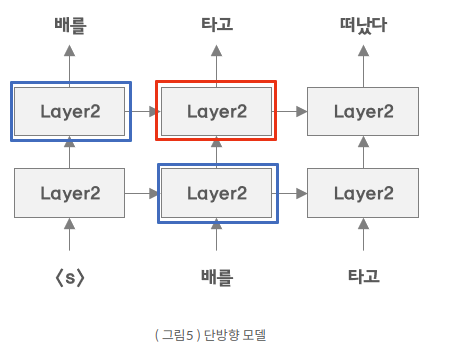
기존의 단방향 모델의 경우, 타고 라는 단어를 예측하기 위해서는 배를이라는 단어만을 사용해서
학습을 진행하였습니다. 즉 파란색 박스만 영향을 끼치게 됩니다.
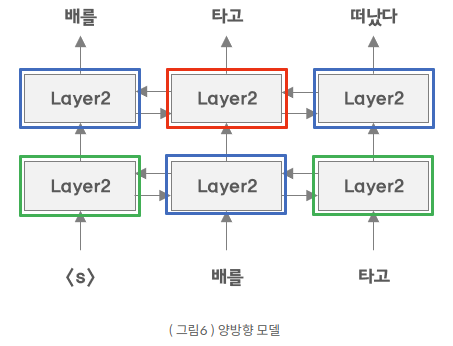
하지만 양방향 모델의 경우 파란색 박스에 초록색 박스가 영향을 끼치면서 타고 라는 단어를 예측
하기 위해 자기 자신인 타고 가 간접적으로 사용됨을 알 수 있습니다.
위와같은 문제를 해결하기 위해, 입력 token의 일부를 무작위로 mask 시킨 다음, [mask]token을 예측합니다.
해당 token을 맞추는 task를 수행하면서, BERT는 문맥을 파악하는 능력을 길러내게 됩니다.
논문에서는 token의 일부를 mask시키는 비율을 15%로 설정하였습니다. 이러한 절차를 maskedLM (MLM) 이라고 합니다.
MLM을 이용하면서, 양방향 사전학습 된 모델을 얻을 수 있게 되었지만, 또 다른 문제점이 발생하였습니다.
이 [mask]token은 pre-training 에만 사용되고, fine-tuning 시에는 사용되지 않기 때문에
pre-train 과 fine-tuning 사이의 간극이 생긴다는 점입니다
이를 완화하기 위해, masking 과정을 수행하지만 항상 [mask]token으로 바꾸어주지는 않았습니다.
예를 들어, i번쨰의 token이 선택되어진 상황을 가정해보겠습니다.
- 80%의 경우,
[mask]token으로 바꾸어줍니다. - 10%의 경우, 임의의 다른 token으로 대체합니다.
- 10%의 경우, token에 아무런 변화도 주지 않습니다.
위와 같이 mask가 선택된 token에 대해서 확률적인 처리를 수행하여, pre-train과 fine-tuning 사이의 간극을 줄일려고 합니다.
3.1.2 Task #2: Next Sentence Prediction (NSP)
Question Answering(QA), Natural Language Inference(NLI)와 같은 task들에서는 두 sentence 사이의 관계를 이해하는 것이 중요합니다. 하지만 이러한 관계는 language model에서는 확인할 수 없습니다.
따라서 sentence 사이의 관계를 이해하도록 binarized next sentence prediction 를 통해 pre-train 합니다. 예를들어 문장 A와 문장 B가 있을떄, 어떻게 학습하는지 살펴보겠습니다.
- 50%(Label=IsNext) : 문장 A가 있을때, 실제 다음 문장인 문장 B가 선택.
- 50%(Label=NotNext) : 문장 A가 있을때, 임의의 다른 문장이 선택.
단순한 작업이지만, 이러한 과정을 거친 pre-train은 task에서 매우 효과적이었다는 것이 증명되었습니다.
3.1.3 Pre-training Procedure
pre-training의 기본적인 절차는 LM에서 수행하는 절차를 따릅니다. Corpus를 pre-training시키기 위해, BooksCorpus(800M), EnglishWikipedia(2,500M)에 나온 단어들을 사용하였습니다. Wikipedia corpus의 경우 list, tables, header를 모두 무시하고 text만을 추출하였습니다. 이는 long contiguous sequences만을 학습시키기 위해서라고 합니다.
3.2 Fine-tunning BERT
BERT에서 fine-tunning은 self-attention을 이용하여 매우 간단합니다. 하나의 sentence pair가 있을 떄, 기존에는 sentence를 분리하고 독립적으로 encode 시키는 과정을 진행하였습니다.
BERT는 이러한 두 단계를 self-attention을 이용하여 통합하였습니다. self-attention을 이용하여 sentence-pair를 encode시키면, 효과적으로 sentence 간의 bidirectional cross attention를 포함시킬 수 있습니다. 간단히 Task-specific한 입력과 출력을 BERT와 연결하고, 모든 파라미터들을 End-to-End로 fine-tuning합니다.
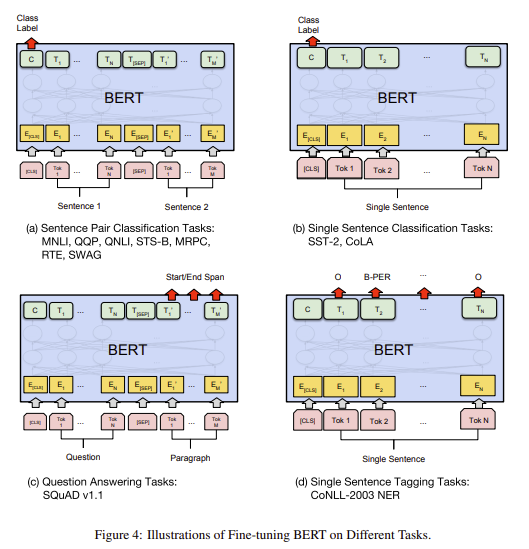
fine-tuning과정은 대부분 pre-train과정의 hyper parameters와 동일합니다. 다른점은 batch size, learning rate, epochs 입니다. fine-tuning과정과 pre-train과정은 task에 따라 조금씩 달라지는데 아래의 그림을 참고하시면 됩니다.
자세한 과정은 논문에서 4. Experiments 와 5. Ablation Studies 에 소개되어집니다.
Conclusion
ELMo, Transformer의 뒤를 이어 나온 BERT는 생각해보면 당연한 사고의 흐름이었던거 같다. 기존의 단방향으로 학습하였던 language represntation을 양방향으로 학습할 수 있고, self-attention을 이용하여 sentence간의 cross attention을 이용할 수 있다는 점. 또한 pre-training 단계에서 MLM과 NSP task을 적용한다는 점이 매우 새로웠다. 어찌보면 간단한 아이디어일 수도 있지만, NLP분야에서 SOTA 성능을 달성하였다는 것이 대단하다.
Comments