3 min to read
Bubble Sort & Selection Sort
이 글은 Edwith에서 제공하는 모두를 위한 컴퓨터 과학 (CS50 2019)를 수강하고 정리한 글입니다.
Bubble Sort
정렬되지 않은 리스트를 탐색하는 것 보다 정렬한 뒤 탐색하는 것이 더 효율적입니다. 정렬 알고리즘 중 하나는 버블 정렬입니다.
버블 정렬은 두 개의 인접한 자료 값을 비교하면서 위치를 교환하는 방식으로 정렬하는 방법을 말합니다. 버블 정렬은 단 두 개의 요소만 정렬해주는 좁은 범위의 정렬에 집중합니다.
이 접근법은 간단하지만 단 하나의 요소를 정렬하기 위해 너무 많이 교환하는 낭비가 발생할 수도 있습니다.
Example
버블 정렬은 배열 안에 들어있는 두 개의 인접한 수를 비교하고 만약 순서에 맞지 않는다면 교환해주는 방식으로 아래의 그림과 같이 작동합니다.
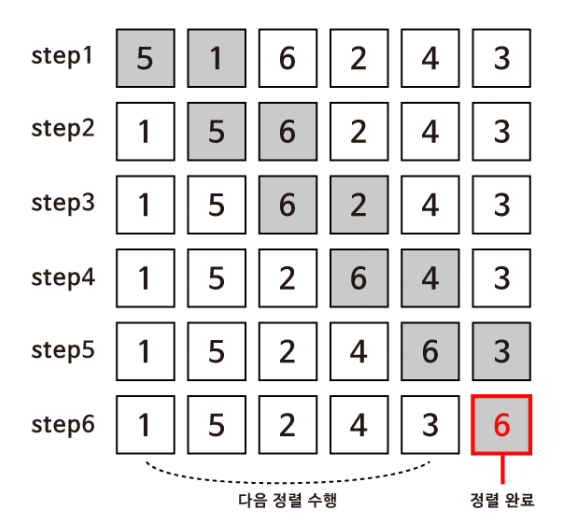
- 제일 먼저 배열 안에서 5와 1을 비교합니다. 1은 5보다 작기 떄문에 두 수는 교환됩니다.
- 다음에는 5와 6을 비교하는데, 올바른 순서로 되어있기 때문에 다음 요소로 넘어갑니다.
- 다음은 6과 2를 비교하고 계속 같은 방식으로 비교하여 교환합니다.
버블 정렬을 한번 시행하면 [1,5,2,4,3,6]의 순서로 정렬된 것을 확인할 수 있습니다. 아직 완전히 정렬되지 않은 배열이지만 6은 이미 제 자리에 와있습니다.
정렬할 데이터가 많지 않고 한 번 정렬해놓은 데이터를 여러번 검색하려 할 때는 버블 정렬이 효율적으로 사용될 수 있습니다.
Code
def Bubble_Sort(arr):
"""
Bubble Sort Alogirhm
Args:
arr: input array
Return:
arr: sorted array
"""
n = len(arr)
for i in range(n):
for j in range(i, n-i-1):
if arr[j]>arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
Time Complexity
$n$개의 원소에 대해서 버블 정렬을 한번 수행할 때마다 $n$번쨰의 원소가 제 자리를 찾게 됩니다. 그렇기 때문에 다음 정렬에서는 $n-1$개의 원소를 정렬해 주면 됩니다.
따라서 비교 횟수가 $ (n-1)+(n-2)+\ldots+2+1=\frac{n(n-1)}{2} $번이 되면서, 평균적으로 시간 복잡도는 $O(n^2)$가 됩니다.
정렬할 데이터의 개수가 많고 정렬해놓은 데이터를 많이 검색할 필요가 없을 때는 버블 정렬이 데이터 정렬 자체에 많은 시간을 투자하기 때문에 비효율적이라고 할 수 있습니다.
Selection Sort
보통 배열이 정렬되어 있으면 정렬되지 않은 배열보다 더 쉽게 탐색할 수 있습니다.
정렬을 위한 알고리즘 중 선택정렬을 배열 안의 자료 중 가장 작은 수(혹은 가장 큰 수)를 찾아 첫 번째 위치(혹은 가장 마지막 위치)의 수와 교환해주는 방식의 정렬입니다.
선택 정렬은 교환 횟수를 최소화하는 반면 각 자료를 비교하는 횟수는 증가합니다.
Example
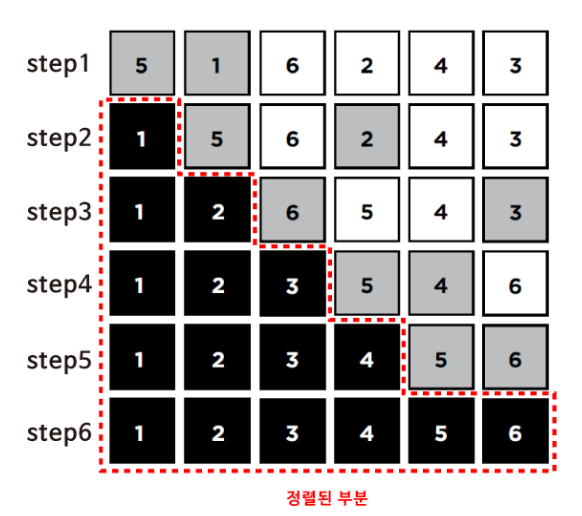
- 배열의 첫 번쨰 자리(5)에서 시작하여, 가장 작은 원소를 찾기 위해 5를 [1, 6, 2, 4, 3]과 비교합니다.
- 1이 가장 작은 값이기 때문에, 5의 위치와 교환합니다.
- 이제 1은 정렬되었으며, 두 번쨰 자리(5)와 [6, 2, 4, 3]과 비교합니다.
- 2가 가장 작은 값이기 떄문에 5의 위치와 교환하며, 이와 같은 방식으로 비교와 교환을 반복합니다.
Code
def Selection_Sort(arr):
"""
Bubble Sort Alogirhm
Args:
arr: input array
Return:
arr: sorted array
"""
n = len(arr)
for i in range(n-1):
min_idx = i
for j in range(i+1, n):
if arr[min_idx] > arr[j]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
return arr
Time Complexity
버블 정렬과는 다르게 몇 번의 교환을 해주었는지 횟수를 계산할 필요가 없습니다. 원래 배열의 순서와 상관없이 선택 정렬로 정렬되는 배열은 $n-1$번의 교환만 필요하기 때문입니다. 하지만 이 과정은 훨씬 더 많은 비교가 필요하므로 연산 비용이 많이 듭니다.
따라서 시간복잡도는 루프문을 통해 모든 인덱스에 접근해야 하기 떄문에 기본적으로 $O(n)$을 소모하며, 최소값 또는 최대값을 찾으면서 swap해야 하기 떄문에 $O(n)$이 추가로 소모되어 버블 정렬과 같이 $O(n^2)$의 시간복잡도를 가지게 됩니다.
Next
- [Algorithm] Merge Sort
Comments