5 min to read
Conditional Random Fields 설명
Conditional Random Fields?
Conditional Random Field(CRF) 는 sequential labeling 문제에서 Recurrent Neural Network (RNN) 등의 deep learning 계열 알고리즘이 이용되기 이전에 널리 사용되던 알고리즘입니다. Conditional Random Field 는 Softmax regression 의 일종입니다.
그러나 a vector point 가 아닌, sequence 형식의 입력 변수에 대하여 같은 길이의 label sequence 를 출력합니다. 이를 위해서 Conditional Random Field 는 Potential function 을 이용합니다. Potential function 은 다양한 형식의 sequence data 를 high dimensional Boolean sparse vector 로 변환하여 입력 데이터를 logistic regression 이 처리할 수 있도록 도와줍니다.
Brief review of Logistic (Softmax) regression
Conditional Random Field (CRF) 는 softmax regression 입니다. 정확히는 categorical sequential data 를 softmax regression 이 이용할 수 있는 형태로 변형한 뒤, 이를 이용하여 sequence vector 를 예측하는 softmax regression 입니다. 그렇기 때문에 softmax regression 에 대하여 간략히 리뷰합니다. Logistic 은 (X,Y)가 주어졌을 때, feature X와 Y와의 관계를 학습합니다. 특히 Y가 positive / negative 와 같이 두 개의 클래스로 이뤄져 있을 때 이용하는 방법입니다. Logistic 은 positive, negative 클래스에 속할 확률을 각각 계산합니다.
\[\begin{bmatrix} P(y=Positive~\vert~x) \\ P(y=Negative~\vert~x) \end{bmatrix} = \begin{bmatrix} \frac{exp(\theta_p^Tx)}{\sum_k exp(\theta_k^Tx)} \\ \frac{exp(\theta_n^Tx)}{\sum_k exp(\theta_k^Tx)} \end{bmatrix}\]Logistic regression 을 기하학적으로 해석할 수도 있습니다. 각각의 θ는 일종의 클래스의 대표벡터가 됩니다. θ1은 파란색 점들을 대표하는 백터, θ2는 빨간색 점들을 대표하는 벡터입니다. 하나의 클래스 당 하나의 대표벡터를 가집니다. Logistic regression 은 각 점에 대하여 각 클래스의 대표벡터에 얼마나 가까운지를 학습하는 것입니다.
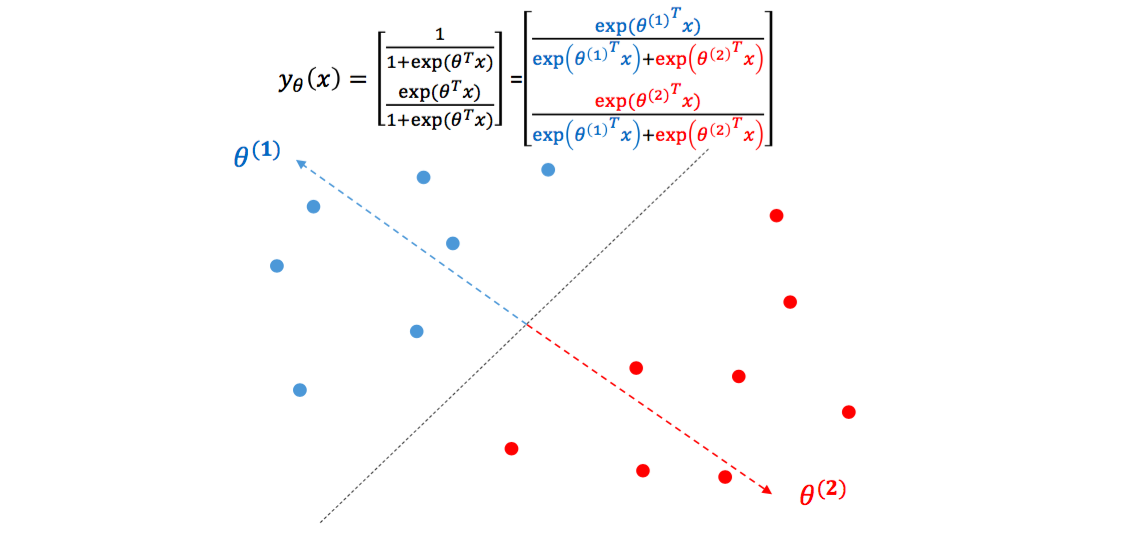
Softmax regression 은 logistic regression 의 일반화버전입니다. 클래스가 2 보다 많은 n개일 때, n개의 대표벡터를 학습하는 것입니다. 각 클래스를 구분하는 결정단면은 대표벡터의 Voronoi diagram 과 같습니다. 단, 각 대표벡터에 얼마나 가까운지는 벡터 간 내적 (inner product)으로 정의됩니다.
Sequential labeling
일반적으로 classification 이라 하면, 하나의 입력 벡터 $x$에 대하여 하나의 label 값 $y$를 return 하는 과정입니다. 그런데 입력되는 $x$가 벡터가 아닌 sequence 일 경우가 있습니다. $x$를 길이가 n인 sequence, $x = [x_1, x_2, \ldots, x_n]$ 라 할 때, 같은 길이의 $y = [y_1, x_2, \ldots, y_n]$을 출력해야 하는 경우가 있습니다. Labeling 은 출력 가능한 label 중에서 적절한 것을 선택하는 것이기 때문에 classification 입니다. 데이터의 형식이 벡터가 아닌 sequence 이기 때문에 sequential data 에 대한 classification 이라는 의미로 sequential labeling 이라 부릅니다. 띄어쓰기 문제나 품사 판별이 대표적인 sequential labeling 입니다. 품사 판별은 주어진 단어열 $x$에 대하여 품사열 $y$를 출력합니다.
| $x = [이것, 은, 예문, 이다]$ | $y = [명사, 조사, 명사, 조사]$ |
| $x = [이것, 은, 예문, 이다]$ | $y = [0, 1, 0, 1]$ |
띄어쓰기는 길이가 $n$인 글자열에 대하여 [띈다, 안띈다] 중 하나로 이뤄진 Boolean sequence $y$를 출력합니다. 이 과정을 확률모형으로 표현하면 주어진 $x$에 대하여 $P(y \mid x)$가 가장 큰 $y$를 찾는 문제입니다. 이를 아래처럼 기술하기도 합니다. $[x_1, \ldots, x_n]$은 길이가 $n$인 sequence 라는 의미입니다.
\[argmax_y P(y_{1:n} \vert x_{1:n})\]위 문제를 풀 수 있는 가장 간단한 방법 중 하나는 각각의 $y_i$에 대하여 독립적인 labeling 을 수행하는 것입니다.
‘너’라는 글자에 대하여 학습데이터에서 가장 많이 등장한 품사를 출력합니다.
하지만 한 단어는 여러 개의 품사를 지닐 수 있습니다.
한국어의 ‘이’라는 단어는 tooth, two 라는 의미의 명사일 수도 있고, 조사나 지시사일 수도 있습니다.
이처럼 문맥을 고려하지 않으면 모호성이 발생합니다.
더 좋은 방법은 앞, 뒤 단어와 품사 정보들을 모두 활용하는 것입니다.
‘너’라는 단어 앞, 뒤의 단어와 우리가 이미 예측한 앞 단어의 품사를 이용한다면 더 정확한 품사 판별을 할 수 있습니다.
특히 앞 단어의 품사를 이용하면 문법적인 비문을 방지할 수 있습니다.
예를 들어 ‘조사’ 다음에는 ‘조사’가 등장하기 어렵습니다.
앞에 조사가 등장하였다면, 이번 단어의 품사가 조사일 가능성은 낮도록 유도할 수 있습니다.
Bidirectional LSTM + CRF
CRF는 Conditional Random Field의 약자로 양방향 LSTM을 위해 탄생한 모델이 아니라 이전에 독자적으로 존재해왔던 모델입니다. 이를 양방향 LSTM 모델 위에 하나의 층으로 추가하여, 양방향 LSTM + CRF 모델이 탄생하였습니다. 여기서는 CRF의 수식적 이해가 아니라 양방향 LSTM + CRF 모델의 직관에 대해서 이해합니다. CRF 층의 역할을 이해하기 위해서 간단한 개체명 인식 작업의 예를 들어보겠습니다. 사람(Person), 조직(Organization) 두 가지만을 태깅하는 간단한 태깅 작업에 BIO 표현을 사용한다면 여기서 사용하는 태깅의 종류는 아래의 5가지입니다.
B-Per
I-Per
B-Org
I-Org
O
아래의 그림은 위의 태깅을 수행하는 기존의 양방향 LSTM 개체명 인식 모델의 예를 보여줍니다.
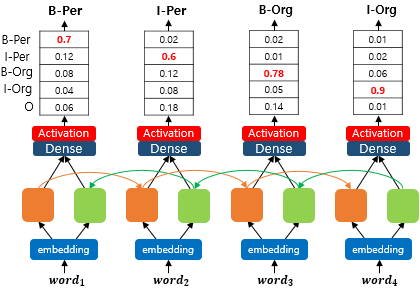
위 모델은 각 단어를 벡터로 입력받고, 모델의 출력층에서 활성화 함수를 통해 개체명을 예측합니다. 사실 입력 단어들과 실제 개체명이 무엇인지 모르는 상황이므로 이 모델이 정확하게 개체명을 예측했는지는 위 그림만으로는 알 수 없습니다.
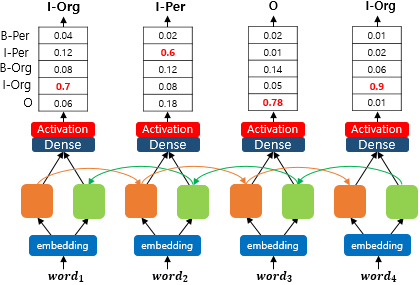
위 모델은 명확히 틀린 예측을 포함하고 있습니다. 입력 단어들과 실제값의 여부와 상관없이 이 사실을 알 수 있습니다. BIO 표현에 따르면 우선, 첫번째 단어의 레이블에서 I가 등장할 수 없습니다. 또한 I-Per은 반드시 B-Per 뒤에서만 등장할 수 있습니다. 뿐만 아니라, I-Org도 마찬가지로 B-Org 뒤에서만 등장할 수 있는데 위 모델은 이런 BIO 표현 방법의 제약사항들을 모두 위반하고 있습니다.
여기서 양방향 LSTM 위에 CRF 층을 추가하여 얻을 수 있는 이점을 언급하겠습니다. CRF 층을 추가하면 모델은 예측 개체명, 다시 말해 레이블 사이의 의존성을 고려할 수 있습니다. 아래의 그림은 양방향 LSTM + CRF 모델을 보여줍니다.
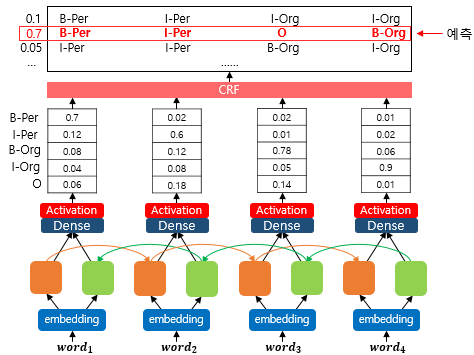
앞서봤듯이, 기존에 CRF 층이 존재하지 않았던 양방향 LSTM 모델은 활성화 함수를 지난 시점에서 개체명을 결정했지만, CRF 층을 추가한 모델에서는 활성화 함수의 결과들이 CRF 층의 입력으로 전달됩니다. 예를 들어 $word_1$에 대한 BiLSTM 셀과 활성화 함수를 지난 출력값 [0.7, 0.12, 0.08, 0.04, 0.06]은 CRF 층의 입력이 됩니다. 마찬가지로 모든 단어에 대한 활성화 함수를 지난 출력값은 CRF 층의 입력이 되고, CRF 층은 레이블 시퀀스에 대해서 가장 높은 점수를 가지는 시퀀스를 예측합니다. 이러한 구조에서 CRF 층은 점차적으로 훈련 데이터로부터 아래와 같은 제약사항 등을 학습하게 됩니다.
1. 문장의 첫번째 단어에서는 I가 나오지 않습니다.
2. O-I 패턴은 나오지 않습니다.
3. B-I-I 패턴에서 개체명은 일관성을 유지합니다. 예를 들어 B-Per 다음에 I-Org는 나오지 않습니다.
요약하면 양방향 LSTM은 입력 단어에 대한 양방향 문맥을 반영하며, CRF는 출력 레이블에 대한 양방향 문맥을 반영합니다.
참고문헌
(5) 양방향 LSTM과 CRF(Bidirectional LSTM + CRF)
From Softmax Regression to Conditional Random Field for Sequential Labeling
Comments