3 min to read
OpenAI GPT-2, Language Models are Unsupervised Multitask Learners 리뷰
OpenAI GPT-2: Language Models are Unsupervised Multitask Learners
최근 NLP 분야에서 Open AI에서 발표한 GPT-3는 많은 사람들에게 놀라움을 주고 있습니다. Few-Shot 학습 방법을 통해 여러가지 NLP Task에서 사람과 같은 수준으로 뛰어난 성능을 보여주기 떄문입니다.
GPT-3의 접근 방법은 기존 GPT-2와 크게 차이나지 않습니다. 이전보다 약 1750억개 가량의 파라미터를 학습시키면서 모델의 사이즈와 데이터의 사이즈를 크게 증가시키는 등 학습 방법을 조정하면서 뛰어난 성능을 갖게 되었습니다.
따라서 이번 포스트에는 기존 GPT-2를 살펴보면서 풀려고자 하는 문제와 그에 대한 해결 방법들을 간단하게 살펴볼려고 합니다.
1. Goal
zero-shot task란 학습 때 보지 못했던, 새로운 데이터에 대해서도 예측을 수행하는 방법입니다.
그렇다면 언어 모델 역시, 한번도 보지 못했던 단어나 문장에 대해서도 예측을 잘 할 수 있을까요? 그럴 수 있다면 QA, Translation, Comprehension, Summarization과 같은 특정 Task에 맞는 데이터를 따로 학습하지 않아도 될 수 있습니다.
논문에서 제시하는 GPT-2는 WebText라는 수백만 웹 페이지의 데이터를 Unsupervised 방식으로 학습하여, 이러한 특정 task들에 대해서 zero-shot 방법을 이용하여 해결하려고 합니다.
2. Differences
기존 언어 모델의 경우, Unsupervised 방식으로 pre-train을 진행하고, Task에 맞게 다시 supervised 방식으로 fine-tunning 하거나, feature-base 방식으로 학습이 진행되었습니다.
하지만 특정 Task에 대한 Dataset을 이용하여 학습이 진행되었기 때문에, NLP 전체적인 관점에서 일반화의 성능은 부족하다는 단점이 존재합니다.
일반적으로 언어는 자연적으로 연속된 순서를 가지므로, 다음 단어를 예측하기 위해서 아래와 같이 보통 조건부 확률의 곱으로 이루어지게 됩니다.
\[p(x) = \prod_{i=1}^n p(s_n \vert s_1, ..., s_{n-1})\]즉 기존의 언어 모델은 특정 Task를 처리하기 위해, 조건부 분포 $p(output \vert input)$를 추정하도록 되었습니다.
하지만 특정 Task를 넘어서, 다양한 도메인과 Task를 처리하기 위해서는 기존과는 다른 구조가 필요하게 됩니다. 같은 입력이 들어오더라도, 다양한 task를 처리하기 위해서 조건부 분포의 형태가 바뀌어야 할 필요성이 있습니다.
\[p(output \vert input, task)\]예를 들어 번역을 진행하기 위해서는 (translate to french, english text, french text) 같이 원하는 Task와, 입력, 출력을 넣어 주기만 하면 됩니다.
즉, 이전과 다르게 Task에 맞도록 fine-tuning 할 필요가 없어졌습니다.
이러한 방법은 parameter나 전반적인 모델 구조의 변화 없이도, zero-shot setting 하에서 다양한 Task를 수행할 수 있음을 시사하였습니다.
3. Method
논문에서 제안한 구조는 결국 같은 입력이 들어오더라도, 다양한 Task를 처리할 수 있다는 것입니다. 그렇다면 다양한 Task를 처리하기 위해서는 어떤 데이터를 학습시켜야 할까요?
논문에서는 기존의 사용되는 데이터들이 신뢰성이 떨어지기 때문에, 직접 WebText 라는 데이터를 구축하였습니다. Reddit이라는 social media platform에서 3개 이상의 Karma(좋아요)를 받은 글만 추출하였습니다. 결과적으로 8M개의 문서, 40GB의 text를 확보하였습니다.
4. Results
모델은 크기가 각각 다른 4개의 모델로 실험하였습니다.
| Parameters | Layers | $d_{model}$ |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
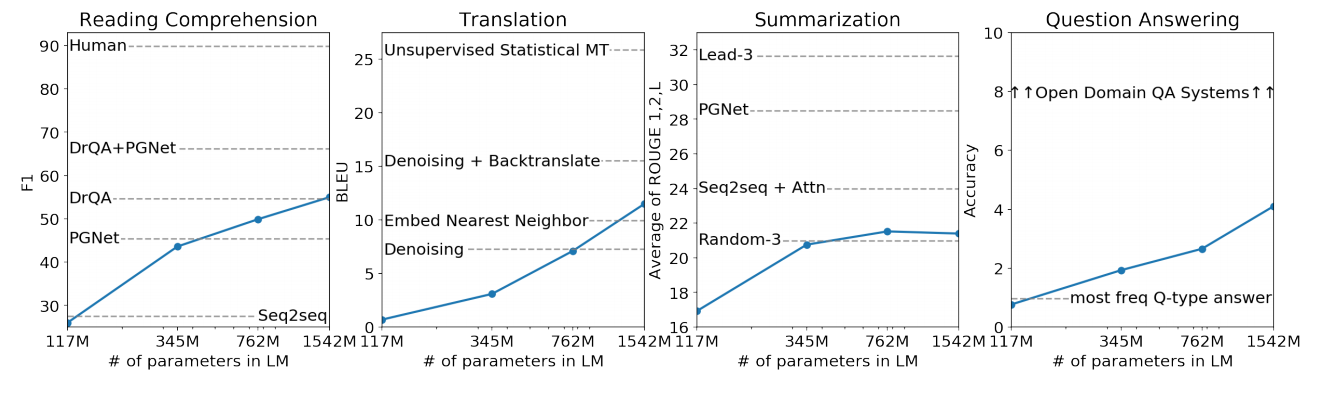
위에서 말한 Task에 따른 실험 결과입니다.
-
Reading Comprehension
CoQA(The Conversation Question Answering dataset) 테스트는 7개의 도메인으로 데이터가 구성되어, 독해능력과 대화에 기반한 모델의 답변 능력을 평가합니다.
GPT-2는 55 F1 score를 달성하여, Base line 4개의 모델 중 3개의 모델보다 성능에서 우수함을 보였습니다. 하지만BERT의 경우, 89 F1 Score를 달성하여 사람과 비슷한 수준의 성능으로 SOTA를 달성하였습니다. -
Summarization
CNN과 Daily Mail 데이터로 모델의 요약 능력을 평가하였습니다. 100개의 토큰을 생성 후에, 처음 3개의 생성 된 문장을 요약으로 사용하였습니다.
성능은 ROUGE로 측정되었으며,
GPT-2는 베이스라인 보다 살짝 좋은 정도의 성능을 기록하였습니다. -
Translation
WMT-14 French-English 데이터로 프랑스어를 영어로 번역하는 능력을 평가하였습니다. WebText 는 프랑스어 Corpus를 매우 적은 숫자만 갖고 있음에도, 11.5 BLEU의 성능을 보여주어 놀라운 결과를 기록하였습니다.
-
Question-Answering
Natural Questions 데이터로 생성한 문장과 답변한 문장이 일치하는지 ACC를 이용해 평가하였습니다.
GPT-2는 약 4.1%의 정확도를 보였으며, 자신있는 1%의 질문에 대해서는 63.1%의 정확도를 보여주었습니다.
5. Discussion & Evaluation
GPT-2의 zero-shot 학습 성능은 Reading Comprehension 등에서 좋은 성능을 보였으나, 아직까진 Summarization과 같은 문제에서는 기본적인 성능만을 보여주었습니다.
실제 적용할 수 있는지의 관점에서는, 아직 사용하기엔 여전히 무리라는 것을 보여주었습니다.
하지만 fine-tuning 없이도 zero-shot task에서 일정 수준 이상의 성능을 보여주었다는 점을 생각하면, fine-tuning을 통해서 어느 정도 수준의 성능을 달성할 수 있을지와 BERT처럼 단방향 표현의 비효율성을 극복할 수 있을지는 아직 연구가 필요한 부분입니다.
또한 Unsupervised task learning의 가능성을 보여주었다는 점은 연구 관점에서 유망한 영역이라는 것을 시사합니다.
Comments