6 min to read
Item2Vec, Neural Item Embedding for Collaborative Filtering 리뷰
Item2Vec: Neural Item Embedding For Collaborative Filtering
자연어 처리에서 인기를 끌고 있는 Word Embedding의 방법 중 하나인 Word2Vec에서 영감을 얻어, 사용자의 정보가 존재하지 않더라도 아이템을 Embedding 하면 [아이템-아이템] 간의 관계를 추론할 수 있다는 방법을 Item2Vec라는 이름으로 제시하고 있습니다.
Prerequisite Learning
Word2Vec이란 비슷한 위치에 등장하는 단어들은 그 의미도 유사할 것이라는 전제로 단어를 벡터로 바꿔주는 알고리즘. Word2Vec의 학습 방식을 참고해보세요
1. Introduction
아이템의 유사도를 계산하는 것이 현재 추천시스템의 목표. 반면에 많은 추천 알고리즘이 사용자와 아이템을 동시에 Low Dimension으로 Embedding시키는 것을 목표로 학습. 이 논문에서는 사용자와 관계없이 아이템을 Low Dimensional 공간에 Embedding시켜 아이템의 유사도을 학습하는 것을 다룸. 아이템 유사도는 단일 아이템 추천의 기반으로 사용되어짐.
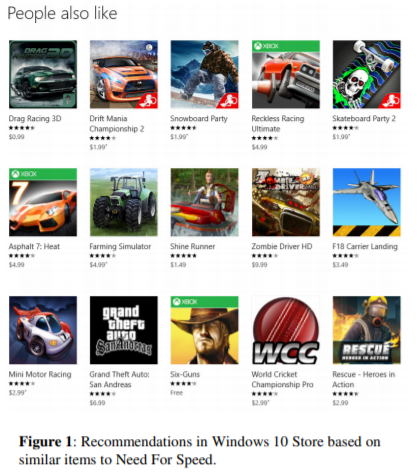
위의 방법은 전통적인 User to Item의 추천방식과는 다른데 그 이유는 User to Item의 경우 아이템에 대해 사용자의 관심과 구매의도가 표시되기 떄문.
그러므로 아이템 유사도 기반의 단일 아이템 추천이 User to Item의 추천 방식보다 CTR(클릭률)이 매우 높으며, 결과적으로도 더 큰 수익을 가져올 수 있음. 아이템 유사도 기반의 단일 아이템 추천은 다양하게 다른 추천 분야에도 사용되어집니다. 결제 전에 Check-Out 페이지에서 추천으로 유사한 아이템을 알려줍니다.
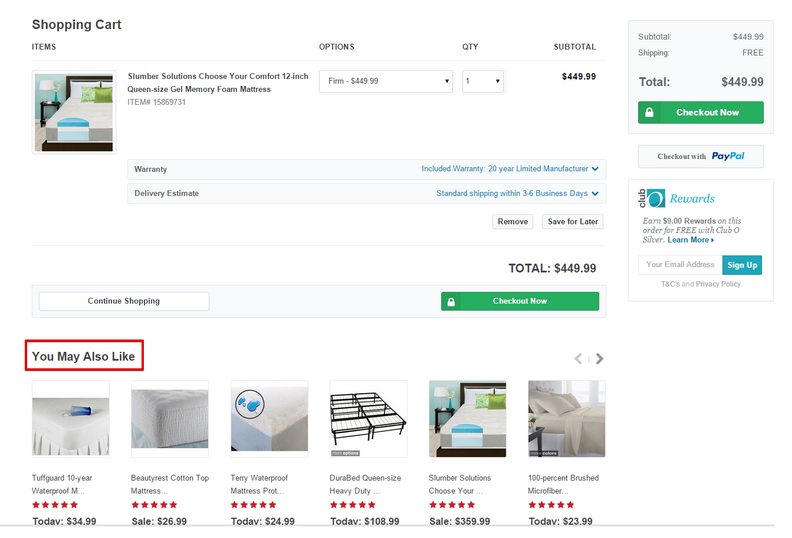
결국 아이템 유사도는 온라인 상점에서 좀 더 나은 탐색과 발견을 위해 사용되며, 전반적인 사용자 경험을 향상시켜줍니다. 아이템 유사도는 아이템 간의 관계를 표현하는 것을 목표로 Item-Based CF 알고리즘의 핵심입니다.
매우 큰 데이터에서 사용자의 수가 아이템의 수보다 휠씬 많을 떄 User-Item 기반보다 Item만을 기반으로 한 모델링이 계산복잡도를 훨씬 낮출 수 있습니다.
예를들어 온라인 음악 서비스의 경우 수만 명의 Artist가 있지만 사용자는 수억명이 존재할 수 있습니다. 위와 같이 User-Item 기반의 관계가 사용될 수 없는 경우도 존재합니다.
오늘날, 온라인 쇼핑의 경우 대부분 로그인을 하지 않아도 이용가능합니다.
대신 이용 가능한 정보는 Session입니다. 하지만 이러한 Session을 사용자로 취급 시, 정보의 질이 떨어질 뿐만 아니라 엄청나게 관리 비용이 증가할 수도 있습니다.
최근 Neural Embedding 기법들은 NLP 분야에서 성능을 극적으로 향상시켜왔습니다. 특히 Negativie-Sampling과 Skip-Gram을 기반으로 한 Word2Vec이 NLP 분야에서 기록들을 갈아치우며, 다양한 분야로 확장되어졌습니다. 이 논문에서는 Word2Vec의 확장판으로써 Item2Vec를 소개하며, SVD를 사용한 Item-Based CF 기법과 유사성을 비교해볼 것 입니다.
2. SKIP-GRAM WITH NEGATIVE SAMPLING
SGNS(Skip-gram with Negatvie Sampling)는 문장 내 중심단어를 기반으로 주변단어를 예측하는 것을 목표로 합니다. 사전 $W$로부터 연속적인 단어 $w$들이 있다고 가정한다면, Skip-Gram의 목표는 밑의 수식을 최대화 하는 것이라고 할 수 있습니다. $c$는 Window_Size로 중심단어 주변을 앞 뒤로 몇개 볼지 정할 수 있습니다.
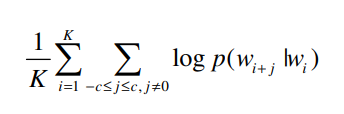
중심단어 $w_i$로부터 설정한 $c$로 주변단어들 중에서 softmax로 가장 큰 확률값을 갖는 단어를 알 수 있습니다.
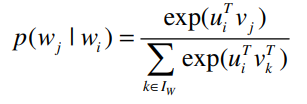
$u$와 $v$는 latent Vector로, 차원은 데이터 사이즈에 따라 설정한 변수 $m$을 따릅니다. 각각 단어 $w_i$에 대한 Target과 Embedding된 값이라고 할 수 있습니다.
위의 수식은 중심단어와 나머지 모든 단어와 내적을 하면서 계산 복잡도가 증가하여 실용적이지 않습니다. Negative Sampling은 이러한 계산 복잡도의 문제를 완화시킬 수 있습니다.
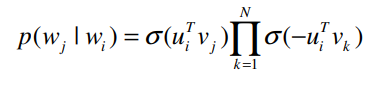
$N$은 Positivie example(window_size)들 중 Negative exmaple(window_size에 없는)의 수를 결정하는 파라미터입니다. Negative Sampling은 여러 분포를 실험적으로 사용해본 결과 Unigram Distribution에서 $3/4$승을 적용한 분포에서 추출하였을 떄 가장 성능이 좋았습니다. 따라서 negative sample로 뽑힐 확률은 아래처럼 정의됩니다.
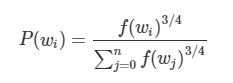
또한 자주 등장하는 단어와 희귀한 단어 사이의 불균형을 줄이기 위해 subsampling 과정이 제안되었습니다. $i$번째 단어($w_i$)를 학습에서 제외시키기 위한 확률을 아래와 같이 정의했습니다.
\[P({discard} | { w })=1-\sqrt { \frac { ρ }{ f({ w }_{ i }) } }\]$f(w_i)$ - 해당 단어가 말뭉치에 등장한 비율, (해당 단어 빈도/ 전체 단어수)
$ρ$ - 임계값
이런 과정은 학습 과정을 가속시키고, 자주 나오지 않은 단어들의 표현 역시 크게 향상시켰습니다. 결국 $U$와 $V$는 이러한 과정들을 통해 목적함수에 경사하강법을 적용하여 계산되어집니다.
3. ITEM2VEC – SGNS FOR ITEM SIMILARITY
CF 데이터에서 아이템은 사용자가 생성한 품목(Set)으로 이루어집니다. 하지만 사용자와 유저에 관계에 대한 정보가 항상 사용 가능하지는 않습니다.
예를 들어 아이템을 비회원으로 구매를 한 유저의 정보가 제공될 수도 있습니다. 정보가 충분하지 않을 수도 있기 때문에 우리는 경험적 결과를 기반으로 Item-Based CF에 SGNS를 적용하게 되면 이런 경우를 더 잘 처리할 수 있습니다.
SGNS를 Item-Based CF에 적용한다는 것은 앞으로 단어와 아이템을 동일하게 본다는 것입니다. Sequence에서 Set으로 동일하게 보면, 사용자가 생성한 아이템 순서/시간에 상관없이 동일한 품목을 공유하는 아이템만의 유사도를 고려합니다.
따라서 동일한 품목을 공유하는 각 아이템들의 쌍을 Postivie example(window_size)로 보며 품목의 크기로부터 결정 됩니다. 목적함수는 아래와 같이 변형됩니다.
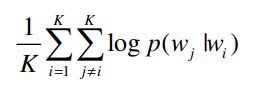
다른 옵션으로는 같은 목적함수로 runtime동안 품목의 아이템들을 shuffle 시키는 것입니다. 이후 과정은 2번쨰 챕터에 소개된 알고리즘과 동일합니다.
4. Experimental Results
-
Item2Vec 방법에 대한 실험결과를 제시
-
아이템이 존재하는지 데이터에 따라서 정성적/정량적 결과 제공
-
Baseline으로 SVD기법을 사용
4.1 Datasets
두가지 다른 유형의 데이터로 테스트하였음.
1. Microsoft XBOX Music Service
- 데이터의 사이즈 9M
- 데이터에는 사용자가 특정 아티스트의 노래를 플레이 했는지에 대한 정보가 있음.
- 사용자는 723K, 아티스트 49K
2. Microsoft Store goods order
- 데이터에서 주문은 사용자의 정보없이 아이템으로 이루어진 정보로 제공
- 데이터의 사이즈 379K개의 주문으로 구성되있으며, 1706개의 아이템들이 있음.
4.2 Systems and parameters
두 데이터에서 모두 epoch을 20번으로 설정하고 SGD 기법을 이용하여 Item2Vec를 적용했습니다. SVD기반의 아이템 유사도 시스템과 결과 비교를 위해 Negative_Sampling에서의 $N$은 15로 모두 설정하였습니다. 두 데이터의 사이즈가 다르기 떄문에 차원 변수 $m$은 100, 40으로, subsampling의 임계값은 10^-5, 10^-3으로 설정하였습니다.
4.3 Experiments and results
Music 데이터의 경우 장르가 제공되지 않았기 때문에 웹에서 각 아티스트에 대하여 장르 데이터를 반환하여, Embedding 값과 장르 간의 관계를 시각화 하기 위해 장르-아티스트 카탈로그를 만들었습니다.
이는 아티스트를 장르에 의해 군집화가 이루어질 것이라는 가정으로 실행되었습니다. 마지막으로 장르 당 인기 아티스트 100명을 포함하는 하위 세트를 생성였습니다. 장르에 따라 각각 아티스트 point들을 t-SNE로 시각화 하였습니다.
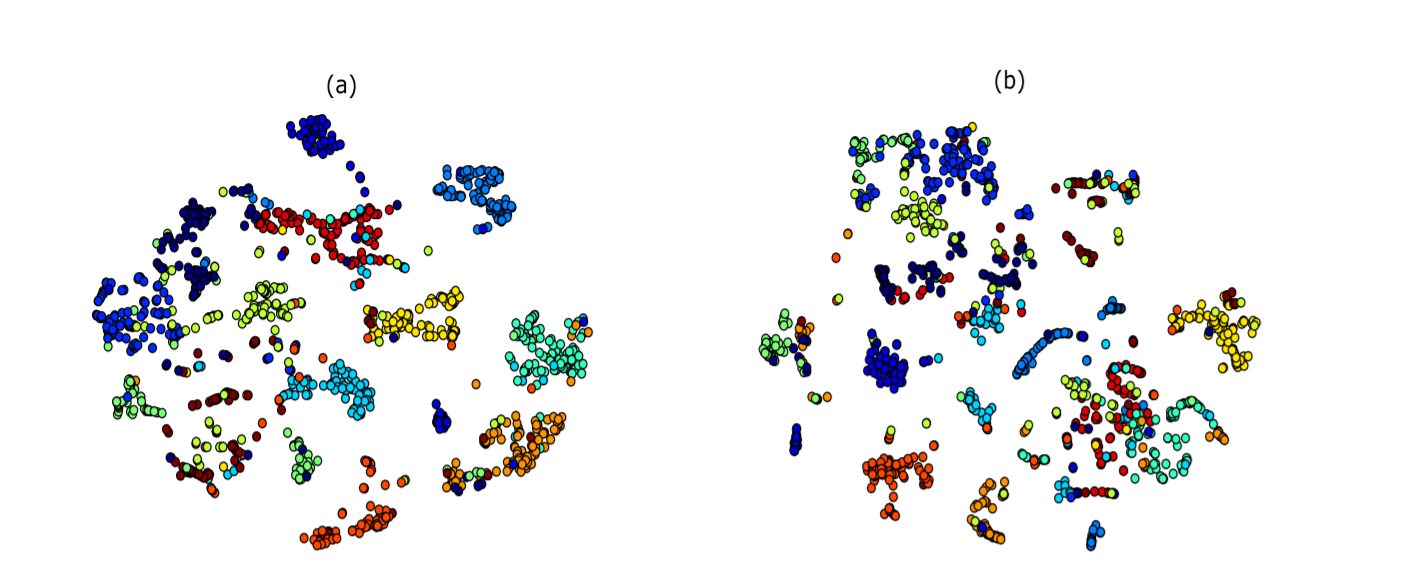
(a) item2Vec, (b) SVD
Item2Vec가 SVD에 비해 더 클러스터링이 잘 된 것으로 보여지지만, 다른 색으로 칠해진 항목들을 볼 수 있습니다. 이러한 경우, 대다수는 웹에서 라벨이 잘못 구성되있거나 아티스트의 장르가 혼합되있는 경우입니다.
따라서 Item2Vec 모델의 경우 레이블이 잘못 지정되어 있는 데이터들을 탐지하는데 유용할 수 있으며 KNN 분류기를 사용하여 레이블을 수정 할 수 있습니다. 유사성 측도를 확인하기 위해 아이템과 가까운 $k$개의 아이템 사이의 장르 일치성을 확인하였습니다.
이는 다수결로 이루어지는데, 서로 다른 이웃 $k$개에 대해서 실험 결과 큰 차이는 없었습니다.
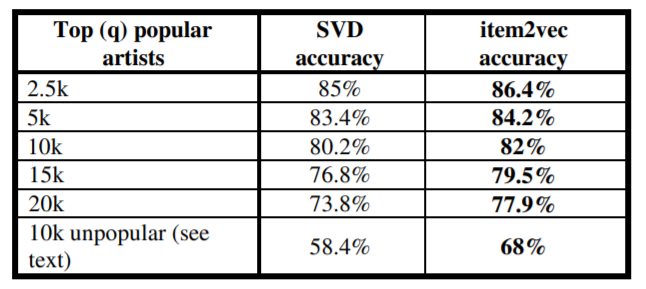
위의 그림은 $k=8$로 얻은 결과이며, SVD보다 Item2Vec의 결과가 좋다는 걸 정량적으로 확인할 수 있습니다. 또한 $q$가 증가함에 따라 두 방법의 결과 차이 또한 상승하고 있습니다.
두 데이터에서 아이템을 일부만 뽑아 가장 가까운 4개의 이웃을 뽑았을 떄 역시, Item2vec가 SVD보다 항목간의 관계를 더 잘 반영한다는 것을 보여줍니다.
인기가 없는 항목에서 두 모델의 성능 차이가 제일 많이 나는데 이에 대한 이유는 Item2Vec는 인기있는 아이템에 대해서 subsampling을 진행하고, 인기에 따라 Negative Sampling을 적용하기 때문입니다.
5. CONCLUSION
-
이 논문에서는 아이템 기반의 Collaborative Filtering을 위한 Embedding 알고리즘으로 Item2Vec를 제시
-
Item2Vec는 약간의 수정된 SGNS를 기반으로 하며, 다수의 실험결과 SVD 기법보다 아이템에 대한 표현이 더 뛰어나다는 것을 보여줌.
-
추후 아이템 유사도의 적용을 위해 베이지안 변형을 추가로 탐구할 예정
Comments