3 min to read
Linear Regression 톺아보기
Linear Regression이란?
Linear Regression의 사전적 의미는 종속 변수 $y$ 와 한 개 이상의 독립 변수 $x$와의 선형 상관 관계를 모델링하는 회귀분석 기법입니다. 즉, 우리가 학습한 데이터를 기반으로 어떤 임의의 점이 평면 상에 그려졌을 때, 최적의 선형 모델(선)을 찾는 것이 목표로 하며, 다시 말해 주어진 데이터를 통해 종속 변수 $y_i$와 $n$개의 설명 변수 $x_i$ 사이의 선형 관계를 모델링합니다.
즉, 모델은 다음과 같은 형태를 가진다고 가정합니다.
\[\widehat{y}=\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\cdots+\theta_{n}x_{n}\]이를 내적 형태로 더 간단하게 표현하면 다음과 같이 표현할 수 있습니다.
\[\widehat{y}=h_{\theta}(\textbf{x})=\theta^{T}\cdot\textbf{x}\]즉 $x$와 ${\theta}=\left(\theta_{0}, \theta_{1}, \cdots, \theta_{n}\right)$에 대하여, 식 $h_{\theta}(\textbf{x})$이 주어졌다고 할 때, $\sum_{i}\left(y_{i}-h_{\theta}({x_i})\right)^{2}$의 값을 최소로 만드는 ${\theta}$(Parameter)를 구하는 것이 목표입니다.
Parameter Estimation
위의 식에서 $e_{i} = y_{i}-h_{\theta}({x_i}) = y_{i}-\hat{y}_{i}$ 를 우리는 실제값과 예측값의 차이인 잔차(Residual)로 해석할 수 있으며, 결국 위의 식은 가능한 가장 작은 RSS(Residual Sum of Squares)를 가지는 값으로 파라미터를 추정합니다.
위의 방법은 Least Square Method(최소자승법)으로, 데이터와의 잔차의 제곱의 합을 최소화하도록 모델의 파라미터를 구하는 방법으로 통칭됩니다.
Least Square Method을 통해서 파라미터를 추정하는데 있어서 크게 2가지의 계산 방법이 사용됩니다.
1. Analytical solution: Normal Equation
$\textbf{x}$를 Full-Rank라고 가정
$\displaystyle{ \mathrm{RSS}=\sum_{i=1}^n(e_i)^2} = {e}^{T} \cdot e$ 로 나타낼 수 있으며, 이를 다시 행렬식으로 나타내면
$\mathrm{RSS} = y^{T}y -2\theta^{T} \textbf{x}^{T}Y + \theta^{T}\textbf{x}^{T}\textbf{x} \theta$ 와 같아집니다.
가장 작은 RSS를 구하기 위해, 즉 ${\theta}$ 에 대해 미분한 식을 0으로 두면 $\dfrac{d \text{RSS}}{d\theta} = 0$ 가 되는 지점이 잔차가 최소화되며, 이에 대한 식을 직교방정식이라 합니다.
이를 계산하면 $\theta=\left(\textbf{x}^{T}\textbf{x}\right)^{-1}\textbf{x}^{T} y$ 로 파라미터를 추정할 수 있습니다.
2. Numerical solution: Gradient descent
경사하강법의 기본 아이디어는 반복적인 계산을 통해 파라미터를 업데이트하면서 오류 값이 최소가 되는 방향으로 $\theta$ 파라미터를 구하는 방식입니다. 즉 방향과 크기를 이동시켜 오류를 최소화시킵니다.
오류 값(Loss)는 실제값과 예측값 사이의 차이값을 기반으로 계산되며, 오류에 대한 식은 손실함수로 아래와 같이 나타내어집니다.
\[\mathrm{L}(\theta) = \mathrm{RSS}(\theta) = \sum_{i}\left(y_{i}-h_{\theta}({x_i})\right)^{2}\]회귀에서 주로 사용되는 손실함수는 MSE, MAE 등 다양하며, 이는 분석 상황에 따라 적절한 선택이 필요합니다.
MSE는 회귀분석에 있어서 가장 많이 사용되는 지표로 RSS를 Scaling한 것과 같습니다.
\[\mathrm{MSE}=\frac{1}{N} \sum_{i}\left(y_{i}-\hat{y}_{i}\right)^{2}\]위의 식은 결국 분산의 공식과 같아집니다. 따라서 회귀분석에서 MSE를 손실함수로 사용하는 것은 직관적으로 합당합니다.
다시 경사하강법으로 돌아와 MSE를 사용하여, 파라미터를 추정하는 과정을 살펴보겠습니다.
\[\begin{array}{l} \theta_{0}:=\theta_{0}-\alpha \cdot \frac{1}{m} \cdot \sum_{i=1}^{m}\left\{h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right\} \cdot x_{0}^{(i)} \\ \theta_{1}:=\theta_{1}-\alpha \cdot \frac{1}{m} \cdot \sum_{i=1}^{m}\left\{h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right\} \cdot x_{1}^{(i)} \\ \end{array}\] \[\vdots\]$\text { for } j=0,1, \cdots, m$에 대하여,
\(\theta_{j}:=\theta_{j}-\alpha \cdot \frac{1}{m} \cdot \sum_{i=1}^{m}\left\{h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right\} \cdot x_{j}^{(i)}\) 로 식이 도출됨을 알 수 있습니다.
파라미터 추정은 Chain Rule에 의해 편미분한 결과로 나타내어집니다. 식에서의 $a$는 학습률로 얼마나 파라미터의 크기를 이동시킬지에 대한 매개변수입니다.
Overfitting
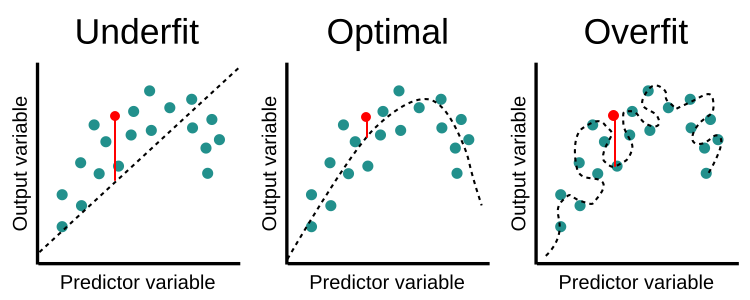
과적합이란 모델이 학습 데이터에 지나치게 최적화되어 범용성이 없어진 상태를 말합니다.
위의 그림에서 오른쪽 그래프를 살펴보면 학습 데이터로 주어진 점을 억지로 통과하다 보니 곡선이 부자연스럽게 그려진 것을 알 수 있습니다.
이처럼 과하게 적응한 모델들은 가중치 행렬이나 가중치 벡터에서 계수의 절대값이 크다는 특징이 있습니다.
그래서 원래의 손실함수에 가중치 행렬이나 가중치 벡터의 계수에 비례하는 패널티를 적용해 계수의 절대값을 낮추는 방법을 고안하게 됩니다. 이러한 방법을 Regularization이라 합니다.
Regularization
Linear Regression애서 모델을 Regularize를 하는 방법은 크게 Ridge, Lasso가 있습니다. 두 방법은 모두 $\lambda$ 를 통한 제약조건을 통해 추정된 계수들의 분산을 줄이고자 합니다.
Ridge 회귀모형에서는 가중치들의 제곱합을 최소화하는 것을 추가적인 제약 조건으로 합니다.
\[\theta = \text{arg}\min_\theta \left( \sum_{i=1}^N e_i^2 + \lambda \sum_{j=1}^M \theta_j{^2} \right)\]Lasso 회귀모형은 가중치의 절대값의 합을 최소화하는 것을 추가적인 제약 조건으로 합니다.
\[\theta = \text{arg}\min_\theta \left( \sum_{i=1}^N e_i^2 + \lambda \sum_{j=1}^M | \theta_j | \right)\]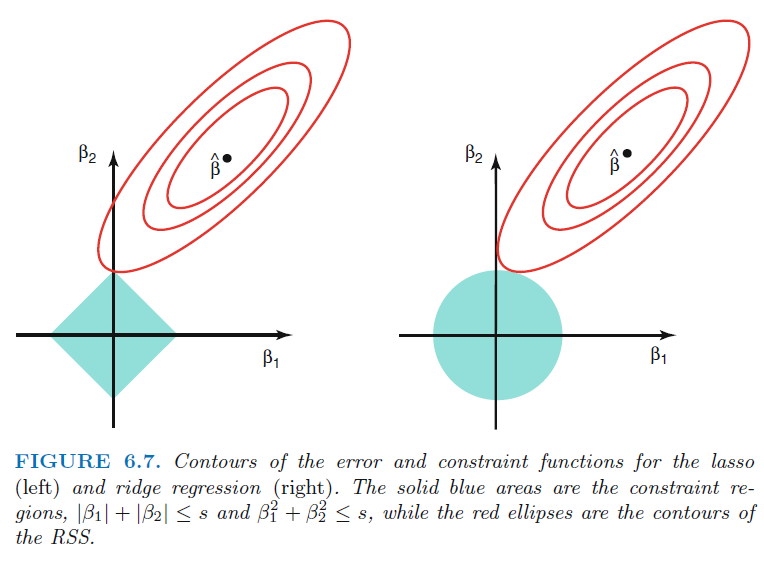
위 그림은 Lasso와 Ridge를 설명하는 가장 유명한 그림으로 왼쪽이 Lasso, 오른쪽이 Ridge 방법을 의미합니다. 각각의 방법은 제약범위와 가능한 가장 작은 RSS를 가지면서 만나는 지점의 값으로 계수를 추정합니다.
Lasso의 경우 제약범위가 사각형 형태라서 최적값은 모서리 부분에서 나타날 확률이 Ridge에 비해 높아, 몇몇 유의미하지 않은 변수들에 대해 계수를 0에 가깝게 추정해 주어 Feature Selection 효과를 가져오게 됩니다.
반면, Ridge의 경우 어느정도 상관성을 가지는 변수들에 대해서 pulling이 되는 효과를 보여줘 변수 선택보다는 상관성이 있는 변수들에 대해서 적절한 가중치 배분을 하게 됩니다.
Comments