3 min to read
Product Quantization with Faiss
Product Quantization with Faiss
1. Introduction
최근 많은 정보와 콘텐츠들의 유입으로 정보의 홍수가 발생하게 되면서 모든 분야에서 유사도 탐색은 항상 중요한 문제입니다. 가령 Youtube, Amazon과 같은 플랫폼에서 유사한 아아이템이나 동영상이 어떤 것인지를 알려주는 것은 고객의 만족도를 높이고 더 많은 콘텐츠를 소비하게 할 수 있습니다.
유사도 탐색은 일반적으로 search nearest neighbor이라 하며, 고전적으로는 brute-force 방법으로 모든 Pair에 대해 유사도를 계산하고, 정렬시킬 수 있습니다. 하지만 전체 유클리드 공간 d가 커질수록 이러한 방법은 연산량이 높아지게 되면서 요청 시에 latecy를 발생시키게 됩니다. 또한 이미지, 동영상, 텍스트와 같이 고차원의 벡터로 표현되는 데이터들이 많아지게 되면서 실제 연산은 기하급수적으로 증가하게 됩니다.
결국 엄청나게 커지는 데이터 규모에 비례해서 효율적으로 유사도를 탐색하는 방법들이 연구되어왔으며, 이는 Approximate Nearest Neighbor(ANN)으로 발전되었습니다. 이름에서 알 수 있듯이 ANN은 간단하게 설명하자면 벡터를 근사하여 유사도를 탐색하는 방법이고, 어렵게 설명하면 벡터를 quantization시켜 여러개의 codebook을 만들고 이를 통해 부분거리 합을 최소화 시켜 유사도를 탐색합니다.
따라서 ANN에서는 벡터를 어떠한 방식으로 quantization을 수행하여 codebook을 구성할 것인지, 어떠한 distance method를 사용하여 유사도를 탐색할 것인지가 핵심이라고 할 수 있습니다.
ANN은 다양한 기업들에서 오픈소스로 공개되어있습니다. 그 중 대표적으로 알려져 있는 알고리즘은 아래 3가지입니다.
- Faiss(Facebook)
- ScaNN(Google)
- Annoy(Spotify)
개인적으로는 Faiss가 GPU를 활용해서 연산속도를 개선시킬 수 있다는 점에서 가장 많이 활용되고 있는 것으로 보입니다.
이번 포스트에서는 Faiss가 어떻게 동작하는지, 어떻게 유사도를 탐색할 수 있는것인지를 알아보고자 합니다.
2. Quantization
Quantization은 예전부터 신호처리 분야에서 연구되던 분야로 간단하게는 표현되는 정보의 양을 줄이는 방법이라고 할 수 있습니다. 이에 대해서는 https://pyy0715.github.io/Audio/#quantization 에 설명되어 있으니 참고 부탁드립니다.
3. Exhaustive Search with Approximate Distances
Faiss는 ANN에서 사용되는 tree-based index 대신 k-nn기반의 product quantizer를 사용하여, query vector와 database의 모든 vector를 비교하는 exhaustive search 으로 동작하게 됩니다. 여기서 핵심은 approximates와 distance를 계산과정을 매우 간소화시킴에 있습니다.
4. Dataset Compression
우선 50,000개의 이미지를 가지고 있다고 가정해봅시다. 우리는 CNN 모델을 통해서 각 이미지의 특징을 1024개의 차원으로 추출하였습니다. 즉 50,000 feature vectors와 1024개의 component를 가지고 있습니다.
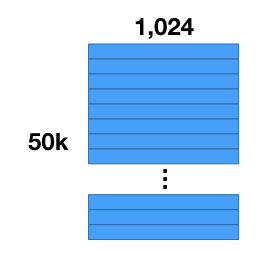
우리가 해야 할 첫번째 작업은 데이터셋을 압축하는 것입니다. vector의 크기를 줄일 수는 없지만 각 vector의 차원을 여러개의 sub vectors들로 줄일 수는 있습니다. 차원을 축소하는 것이 아니라 차원을 여러개의 matrices로 분할하는 것입니다.
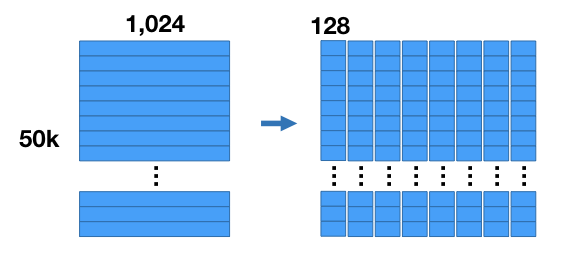
위의 이미지처럼 1,024개의 component를 8개의 sub vectors로 분할함으로써, 128개의 차원으로 나타낼 수 있습니다. 즉 8개의 행렬을 갖고 있으며, 각 행렬의 사이즈는 [50K*128]이 됩니다.
다음으로는 각 행렬에 대해 k-means 클러스터링을 적용합니다. 여기서 k=256으로 설정합니다. 이를 통해 8개의 행렬에 대해 256개의 centroid를 가질 수 있습니다. 256개의 centroids들은 codebook이라 하며, 각 centorid들을 code라 합니다. 우리는 8개의 codebook을 생성했다고 할 수 있습니다.
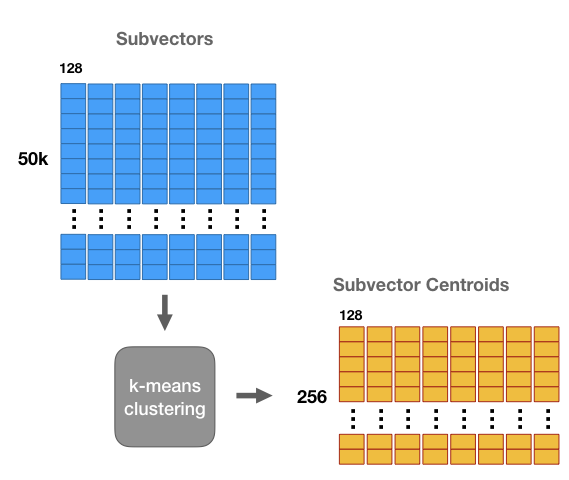
즉 위의 그림에서 노란색 테이블의 column은 각 cluster를 의미하고, row는 cluster들의 centorid를 나타낸다고 볼 수 있습니다.
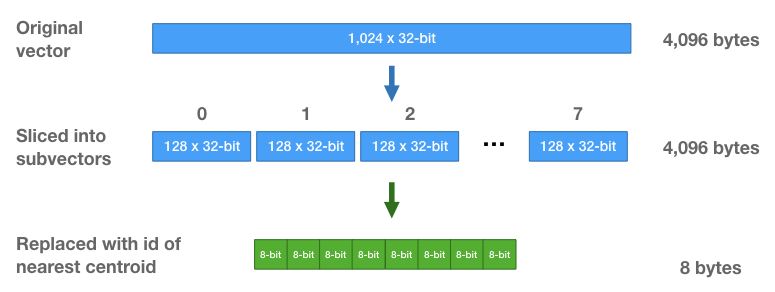
sub vector가 있을 때, 가장 가까운 centroid를 찾아 sub_vector를 centroid의 id로 대체합니다. 이는 모든 vector에 대해서 우리는 연속적인 8개의 centroid ids들로 다시 나타낼 수 있음을 말합니다.
조금 더 자세히 설명하면 subvector를 centorid의 id만으로 표현함으로써, floating point 32bit를 이산화시켜 8bit로 나타낼 수 있음을 말합니다. 이는 표현되는 정보의 양을 줄임으로써 데이터를 효과적으로 압축시킬 수 있습니다.
5. Nearest Neighbor Search
vector를 centroid ids로 압축할 수 있지만, 이를 통해 거리를 계산할 수는 없습니다. centroid id간에 거리 계산은 의미가 없습니다.
Faiss에서 nearest neighbor search를 수행하는 과정은 look-up 테이블을 사용하여 exhaustive search방식으로 동작합니다.
먼저 nearest neighbors를 찾기 위해 query vector가 있는 상황을 가정해봅시다. 단순하게는 centroid ids들을 결합하여 다시 vector를 reconstruct하여 거리 계산을 할 수는 있습니다만, 스마트한 방법은 아닙니다.
vector에 대한 각각의 sub vector와 cluster의 centriods들에 대해 L2 distance를 계산하여 subvector distance table을 구축합니다. 테이블의 크기는 [256 * 8]이 될 것입니다. distance table은 연산량을 줄이면서도 50K database vectors들과의 distance를 근사합니다.
database vector는 8개의 centroid ids들로 구성되어 있습니다. db vector와 query vector사이의 유사도를 근사하기 위해서는 centroid id들의 distance table을 look-up 하여 합산합니다.
\(db vector = [\text{centroid-id1}, \text{centroid-id2}, \text{centroid-id3} ... \text{centroid-id8}]\) \(db vector = [\text{lookup-id1} + \text{lookup-id2} + \text{lookup-id3}, ... + \text{lookup-id8}]\)
이러한 방식은 vector를 다시 reconstruct하여 거리를 계산하는 것과 동일한 결과를 제공하지만 더 낮은 계산 비용을 요구합니다. 이후 단계는 거리를 계산하고 정렬하는 일반적인 neigbor search와 같은 방식으로 이루어집니다.
Comments