4 min to read
고군분투 Ubuntu Machine Learning 구축하기, Chapter2
지난 시간에 Machine Learning 환경이 구축이 되었다면, 이번에는 Anaconda와 대표적인 딥러닝 Framework인 TensorFlow, Pytorch 설치 방법을 소개하겠습니다.
또한 Jupyter를 가상환경에서 사용할 떄 생기는 문제점도 소개하겠습니다.
아직 Nvidia Driver, Cuda 설치가 되지 않았다면 이전의 포스팅을 참고해주세요.
고군분투 Ubuntu Machine Learning 구축하기, Chapter1
1. Anaconda 및 Tensorflow, Pytorch 설치
Anaconda 설치를 위해 다운로드 페이지로 가서 파일을 다운받습니다. 파일을 실행시키기 위해 아래의 명령어를 입력합니다.
cd 다운로드
bash Anaconda3-2020.02-Linux-x86_64.sh
source ~/.bashrc
설치 중간에 라이센스나 경로 설정에 관한 질문이 나오는데, 기본값으로 yes를 입력해주시면 됩니다.
설치가 완료된다면, 콘솔 왼쪽에 base라고 나오게 됩니다.
2. Jupyter Notebook Server
Jupyter Notebook을 Server형태로 이용하면 다음과 같은 장점이 있습니다. local에서만 Jupyter를 이용하실 분들은 skip하셔도 됩니다.
- 외부에서 노트북을 이용시, 데스크탑 환경으로 Jupyter Notebook을 이용할 수 있습니다. 즉, 자신만의 Colab이 생긴다고 생각하시면 됩니다.
jupyter notebook --generate-config
ipython
from notebook.auth import passwd
passwd()
위의 코드를 입력 후에는 Enter password가 나오면서 비밀번호를 입력하고, Verify password가 나오면 앞서 입력한 비밀번호를 한 번 더 입력하면 됩니다.
입력하게 되면 키값이 ‘sha1:~~~~~’ 와 같은 형태로 출력됩니다. 복사를 하고 exit()를 입력하여 ipython을 종료합니다.
다음에는 적용을 위해 설정파일을 열어줍니다.
sudo vim /home/<username>/.jupyter/jupyter_notebook_config.py
그 다음, 아래의 리스트들을 수정하면 됩니다.
# 내부 IP주소를 입력합니다.
c.NotebookApp.ip = ''
# JupyterNotebook이 실행될 port번호를 입력합니다.
c.NotebookApp.port = ''
# 위에서 복사했던 키값을 입력합니다.
c.NotebookApp.password = u'sha1:~~~'
# 서버로 실행될때 서버PC에서 Jupyter Notebook 창이 새로 열릴 필요가 없습니다.
c.NotebookApp.open_browser = False
설정이 완료되면 서버 실행을 위해 아래의 명령어를 입력해줍니다.
sudo ufw allow <yourport>
cd /home/<username>/.jupyter
jupyter notebook --config jupyter_notebook_config.py
서버에서 실행을 해두고나서, 외부 다른 디바이스에서 접속이 되는지 확인을 해보겠습니다.
우리가 설정했던 ip:port로 들어가면, 아래와 같은 화면을 볼 수 있습니다.
3. Install Pytorch, Tensorflow
이제 Pytorch와 Tensorflow 설치를 위해 아래의 명령어를 입력해줍시다.
Tensorflow는 기본적으로 version2가 설치됩니다.
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
conda install tensorflow
이제 정상적으로 설치가 완료되었는지와 GPU 사용 가능 여부를 확인해봐야 합니다.
python
import torch
import tensorflow as tf
print(torch.cuda.is_available())
print(tf.test.is_gpu_available())
True가 2번 나오게 되면 pytorch와 Tensorflow에서 GPU가 사용이 가능한 것입니다.
4. Trouble Shotting Jupyter Notebook Server
저 같은 경우는 Juptyer를 Server로 구동하면서, 가상환경을 만들어서 프로젝트를 진행합니다.
처음 문제의 발단은 가상환경을 실행 후, plotly를 설치하였지만 Jupyter에서 plotly가 계속 없다고 나오게 되는 상황이 발생하였습니다.
No module named ‘plotly’
이는 Jupyter를 Server로 구동시킬떄, 새로운 가상환경을 생성하고 실행하였지만
기존의 base 환경으로 python이 잡혀서, 가상환경 내 설치한 library들을 제대로 import하지 못하는 문제점입니다.
실제로 Jupyter를 실행하고 아래의 명령어를 입력하면, 가상환경으로 실행하였지만
가상환경의 python이 아닌 base의 python을 구동하고 있다는 것을 확인할 수 있었습니다.
import os
print(os.__file__)
-> /home/yyeon/anaconda3/lib/python3.7/os.py
이럴 경우에는 직접 가상환경의 python을 구동하도록 설정해주어야 합니다. 먼저 Jupyter의 위치가 어떻게 되는지 알아봐야 합니다.
jupyter --path
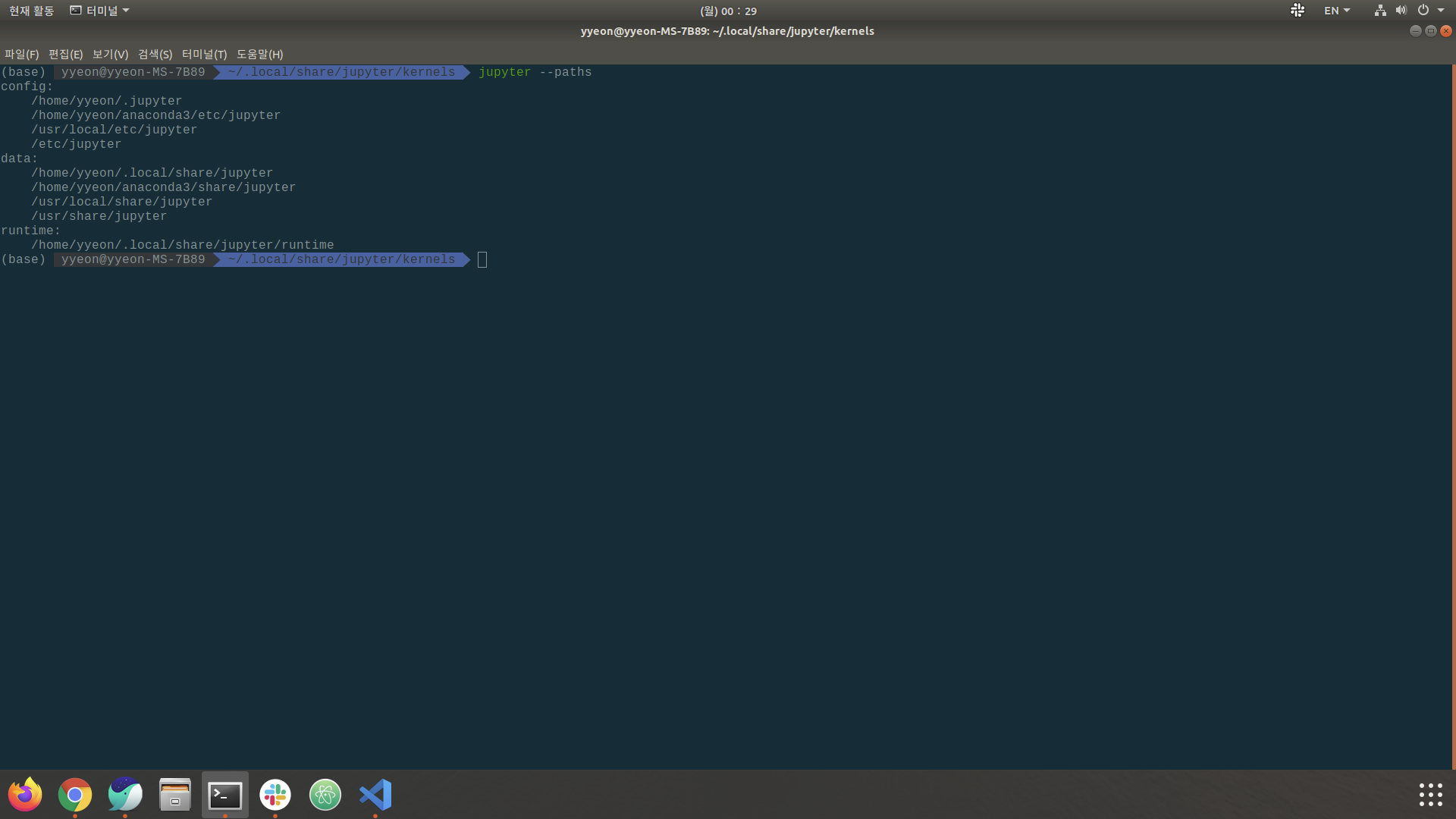
저의 경우에는 data 아래에 있는 /home/yyeon/.local/share/jupyter 에 jupyter가 위치하고 있습니다.
경로에 들어가서 목록을 확인하면, 가상환경 list들이 나오게 됩니다.
cd /home/yyeon/.local/share/jupyter
ls -lh
저는 현재 2개의 가상환경을 쓰고 있기 때문에, 2개의 가상환경이 나오게 됩니다. 원하는 가상환경으로 들어가주세요.
cd <your env>
ls - lh
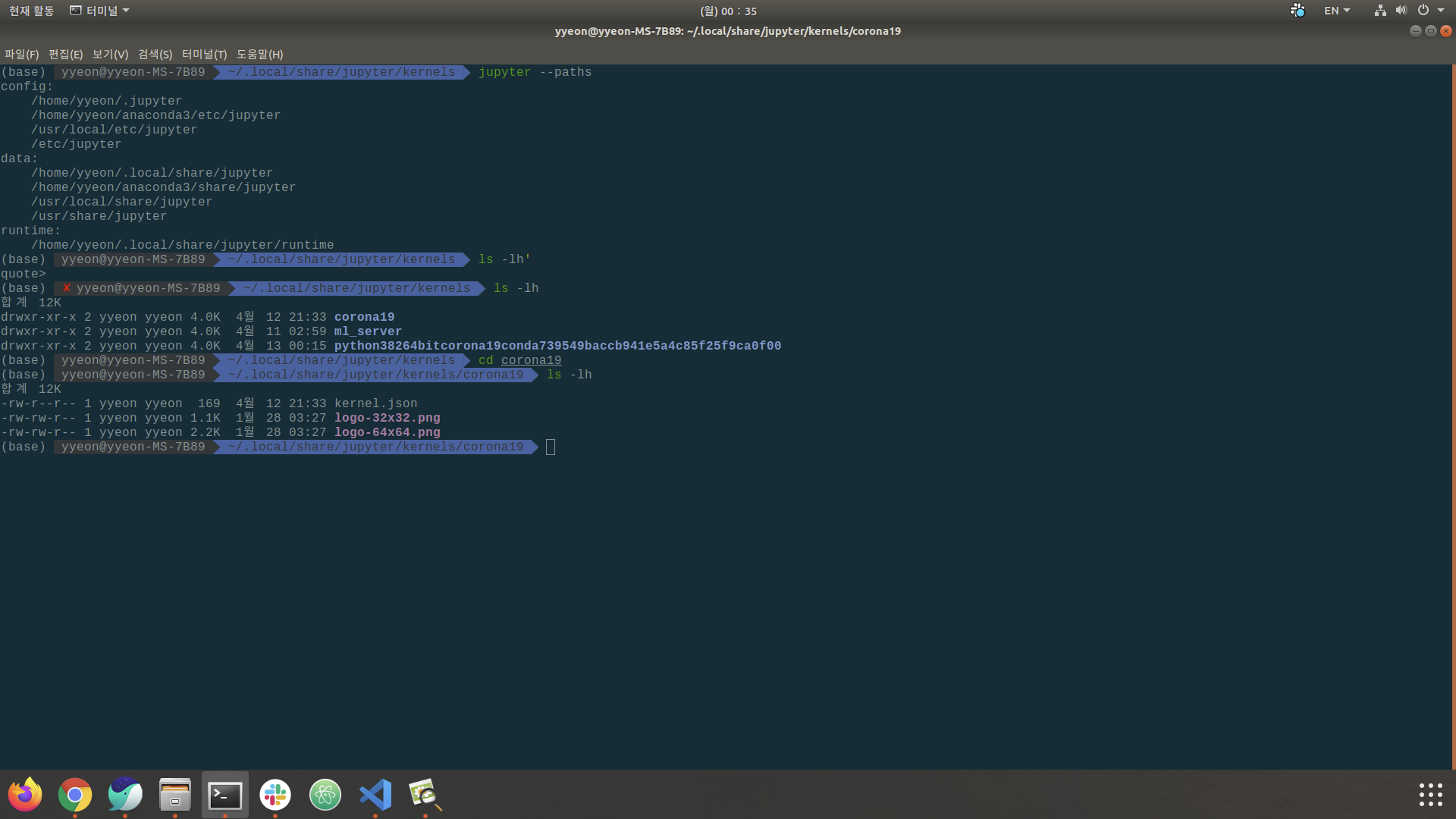
확인해보면 kernel.json이라는 파일이 하나 있습니다.
저희는 가상환경의 python을 구동 시키기 위해 여기서 kernel.json 파일을 수정 해주어야 합니다.
그럼 먼저 가상환경의 python이 어디 위치에 있는지 확인해봐야 합니다.
conda actviate <your env>
which python
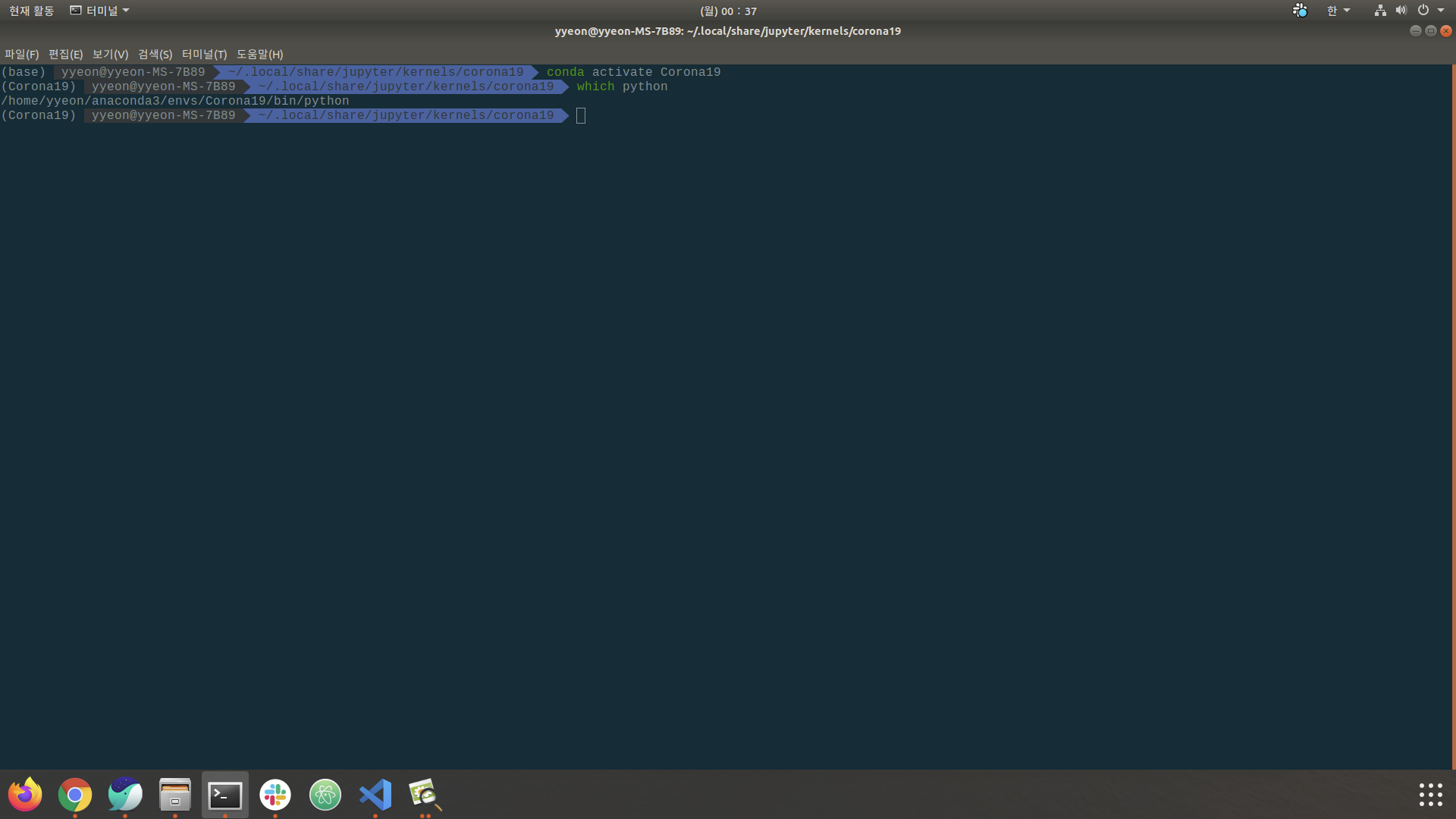
출력되는 경로를 복사한 후에 아래의 명령어를 입력하고 위치를 변경해주어야 합니다.
sudo vim kernel.json
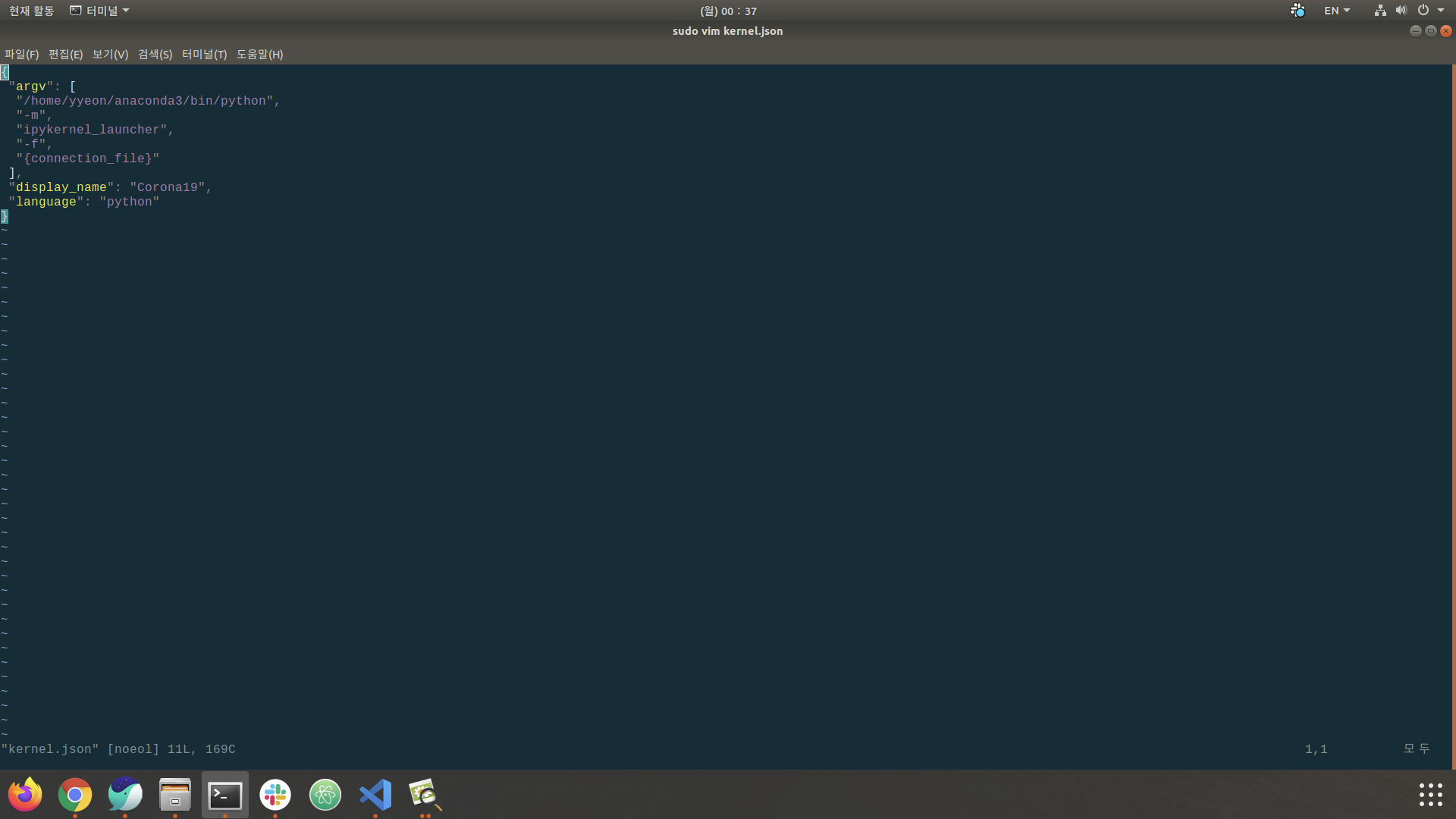
argv에서 기존의 경로를 지우고, 복사한 경로를 붙여넣기 해주세요!
아래는 경로를 변경하고 난 후의 파일입니다.
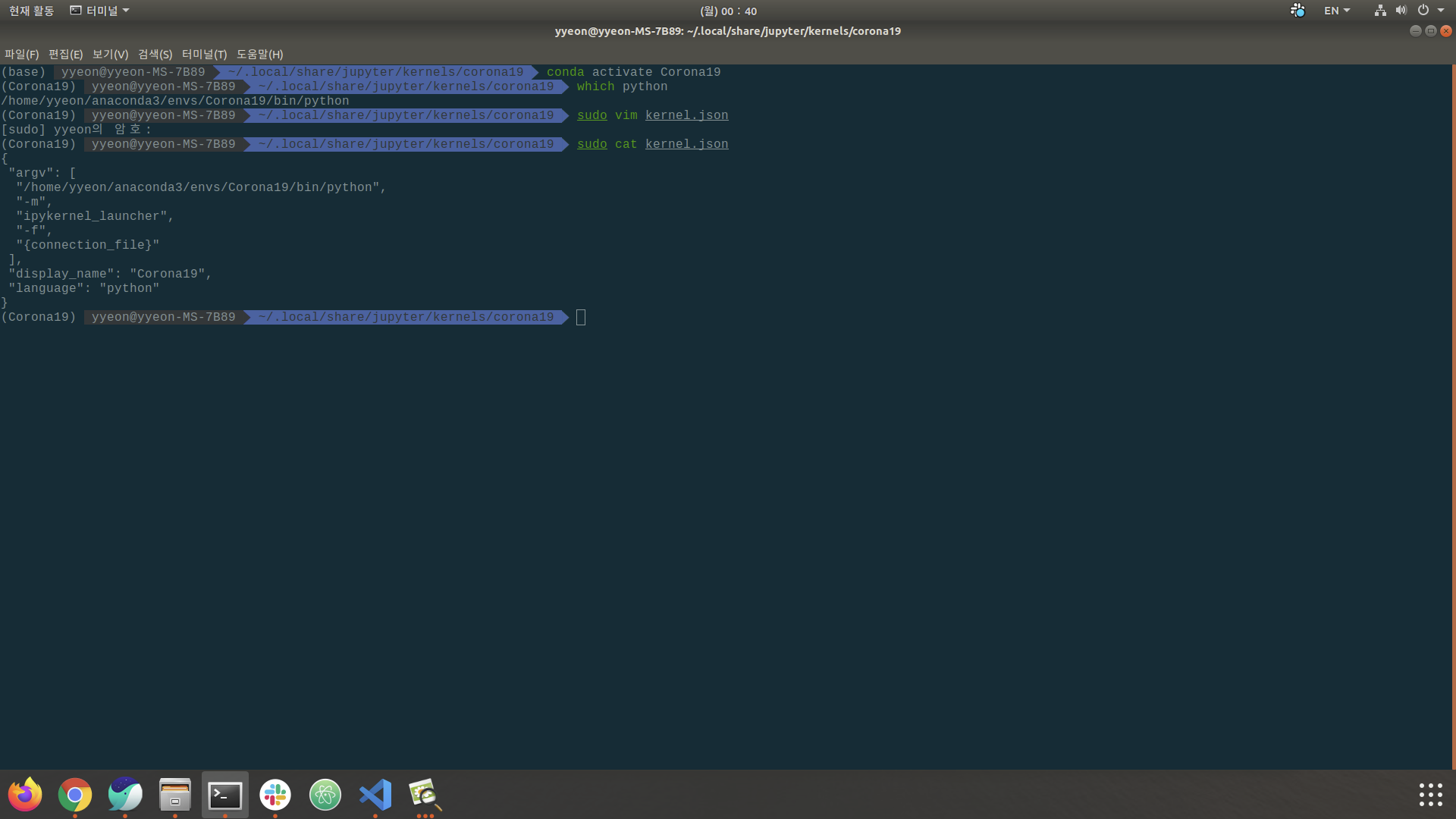
이제 정상적으로 되겠지? 라는 생각에 Jupyter를 실행하게 되면, 또 다른 문제점에 직면하게 됩니다. 바로 가상환경에 Jupyter가 없기 때문에 Jupyter가 실행이 되지 않습니다….ㅠㅠㅠ 다시 아래와 같은 명령어를 입력해주세요.
conda activate <your env>
conda install jupyter
이제는 정상적으로 Jupyter가 작동이 되고, plotly도 Import할 수 있습니다.
Next
분석 환경이 세팅되었지만, 우리는 아직 데이터가 없기 때문에 분석을 수행할 수 없습니다. 실제 머신러닝 과정에서 가장 어려운 것은 데이터 수집이라고도 하죠? 데이터를 수집하는 것만큼 중요한 것이 데이터를 저장하는 것입니다.
다음 글에서는 Docker를 이용하여, 개인 DB를 구축하는 방법을 소개해드리겠습니다.
저도 처음이라 다음 글은 어느 정도의 시간이 소요될꺼 같습니다.
혹시 위의 방법대로 수행하였지만 오류가 있을 경우, 알려주시면 수정하겠습니다.
감사합니다.
Comments