11 min to read
Bootstrapping RKE2 Cluster - 0
Cloudnet@K8S-Deploy Week7
Kubernetes는 오늘날 컨테이너 오케스트레이션의 사실상 표준으로 자리 잡았지만, Kubernetes를 설치하고 운영하는 방식은 배포판과 도구에 따라 상당한 차이를 보입니다.
kubeadm은 업스트림 Kubernetes를 그대로 설치하기 위한 부트스래핑 도구이고, Kubespray는 kubeadm을 포함한 여러 구성 요소를 Ansible 플레이북으로 자동화한 배포 도구입니다.
RKE2는 이들과 근본적으로 다른 접근 방식을 취합니다. RKE2는 단순히 Kubernetes를 설치해주는 도구가 아니라 보안 및 규정 준수를 기본값으로 설계된 Kubernetes 배포판입니다. 따라서 설치 도구보다는 보안 지향 설계가 내장된 Kubernetes 제품으로 이해할 수 있습니다.
RKE2의 내부 구조를 이해하려면 K3s를 먼저 이해하는 것이 중요합니다. RKE2는 K3s의 코드베이스와 운영 철학을 직접 계승한 프로젝트입니다. RKE2의 여러 아키텍처적 결정은 K3s가 해결했던 문제, 그리고 K3s가 의도적으로 다루지 않았던 영역에서 출발했습니다.
K3s
K3s는 2019년 Rancher Labs가 공개한 경량 Kubernetes 배포판입니다. 현재는 Cloud Native Computing Foundation의 Sandbox 프로젝트로 관리되고 있습니다.
K3s의 설계 목표는 매우 명확합니다. 리소스가 제한된 엣지(Edge) 환경, IoT 디바이스, 단일 노드 개발 환경과 같은 경량 환경에서 Kubernetes를 실행하는 것입니다.
Remove in-tree cloud provider
업스트림 Kubernetes에는 AWS, GCP, Azure와 같은 클라우드 환경과 직접 연동하기 위한 in-tree cloud provider 코드가 포함되어 있습니다. 예를 들어, LoadBalancer 타입의 Service를 생성하면 해당 클라우드의 API를 호출하여 실제 로드밸런서를 생성하는 기능이 기본 내장되어 있습니다.
그러나 K3s는 이러한 클라우드 프로바이더 종속성을 기본적으로 포함하지 않습니다.
그 이유는 명확합니다. K3s의 주요 사용 환경은 퍼블릭 클라우드가 아니라 엣지(Edge), 온프레미스(On-Premise), IoT 환경이기 때문입니다. 이런 환경에서는 특정 클라우드 API에 의존하는 기능이 불필요하거나 오히려 복잡성을 증가시킬 수 있습니다.
Remove in-tree volume plugin
업스트림 Kubernetes는 in-tree volume plugin을 점진적으로 CSI(Container Storage Interface) 기반 드라이버로 전환하는 과정에 있으며, 이 때문에 레거시 스토리지 드라이버와 여러 단계(Alpha, Beta, GA)의 기능이 함께 포함되어 있습니다.
이러한 요소들은 범용 Kubernetes 배포판에서는 필요할 수 있지만, 경량 배포판에서는 오히려 유지 비용과 복잡성을 증가시킵니다.
Use SQLite in Single Node
업스트림 Kubernetes는 고가용성(HA)을 고려하여 기본적으로 etcd를 데이터스토어로 사용합니다. etcd는 분산 키-값 저장소로, 클러스터 상태를 일관성 있게 유지하는 데 핵심적인 역할을 합니다.
하지만 단일 노드 환경에서는 분산 합의 알고리즘이 필요하지 않습니다.
K3s는 이러한 점을 고려하여 단일 서버(single-server) 모드에서는 기본 데이터스토어로 SQLite를 사용합니다.
Single Binary
일반적인 Kubernetes 구성에서는 다음과 같은 컴포넌트가 각각 별도의 바이너리로 존재합니다.
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- kubelet
- kube-proxy
kubeadm 기반 환경에서는 이러한 Control Plane 구성 요소들이 개별 프로세스로 실행되거나, /etc/kubernetes/manifests에 정의된 Static Pod 형태로 동작합니다. 각 컴포넌트는 독립적으로 실행되며, container runtime 또한 별도로 설치하고 구성해야 합니다. 즉, 관리자가 여러 구성 요소를 조합하여 하나의 클러스터를 완성하는 구조입니다.
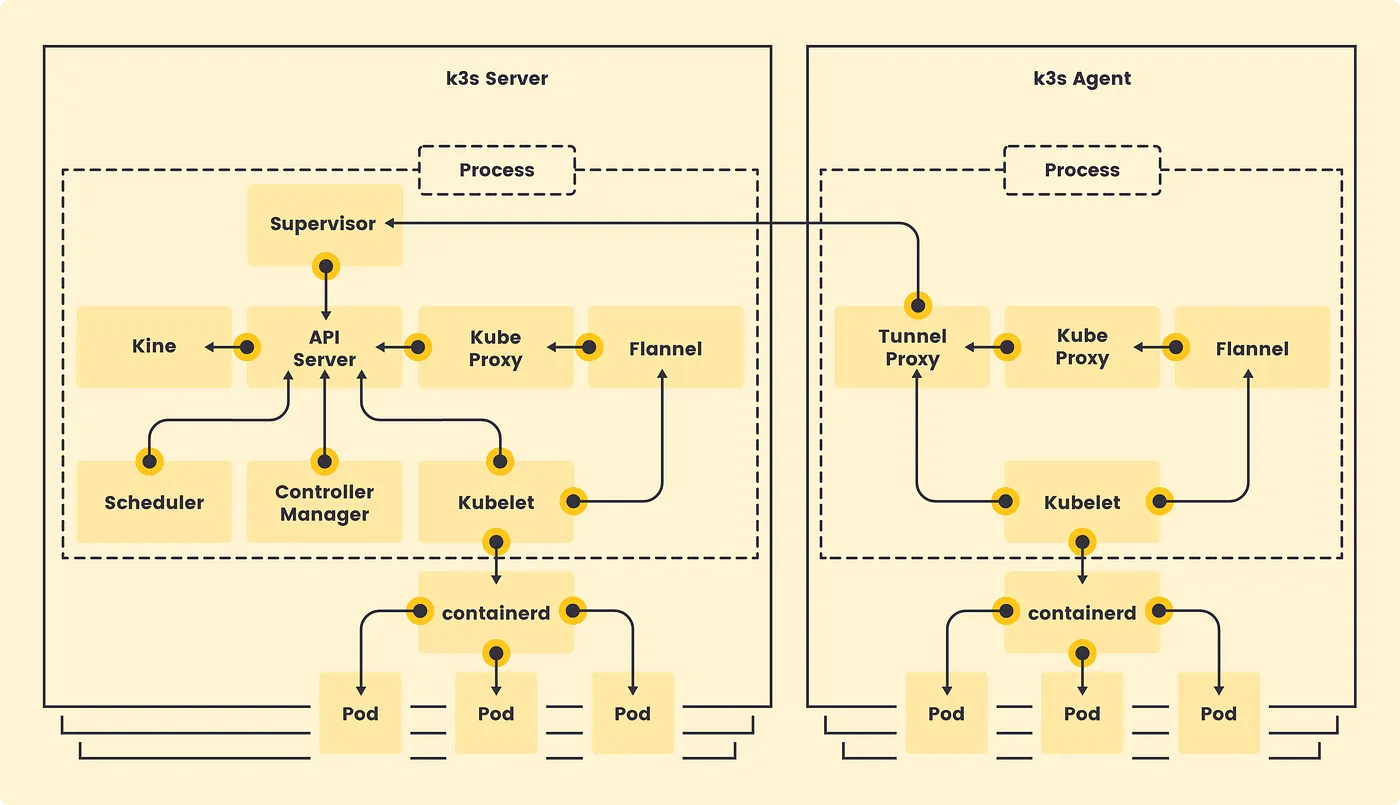
반면, K3s는 주요 Control Plane 구성 요소와 container runtime(containerd)을 단일 바이너리로 패키징합니다.
K3s 프로세스는 내부적으로 Supervisor 역할을 수행하며, kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy 등 필요한 구성 요소를 생성하고 관리합니다. 즉, 외부에서 여러 바이너리를 개별적으로 실행하는 구조가 아니라, 하나의 상위 프로세스가 내부 컴포넌트를 통합 관리하는 구조입니다.
 Architecture
Architecture
k3s server는 Control Plane과 데이터스토어(SQLite 또는 etcd)를 포함하며, 클러스터의 중심 역할을 수행합니다.k3s agent는 Worker Node로 동작하며, kubelet, kube-proxy, containerd를 실행하고 server의 Supervisor 엔드포인트에 연결하여 클러스터에 참여합니다.
Limitations
K3s의 철학은 경량성과 간결함이라는 분명한 장점을 제공합니다. 설치가 단순하고, 리소스 사용량이 낮으며, 엣지(Edge) 환경이나 단일 노드 개발 환경에 매우 적합합니다. 그러나 엔터프라이즈 환경에서는 단순한 설치 편의성보다 보안 기준과 규정 준수 충족 여부가 더 중요한 평가 요소가 됩니다.
엔터프라이즈 환경에서 자주 언급되는 기준이 바로 CIS Kubernetes Benchmark입니다.
이는 Center for Internet Security(CIS)가 발행하는 보안 설정 가이드라인으로, Kubernetes 클러스터를 안전하게 구성하기 위한 구체적인 권고 사항을 정의합니다.
- kube-apiserver 보안 플래그 설정
- etcd 통신 TLS 구성
- kubelet 인증 및 권한 설정
- RBAC 최소 권한 원칙 적용
- Pod Security 설정
K3s는 기본적으로 이러한 항목을 강제하지 않습니다. 따라서 CIS 기준을 충족하려면 관리자가 별도로 설정을 조정해야 합니다.
또 다른 중요한 기준이 FIPS 140–2입니다.
FIPS(Federal Information Processing Standards)는 미국 연방 정부가 정의한 정보 처리 표준입니다. 그 중 140–2는 암호화 모듈(Cryptographic Module)의 보안 요구사항을 정의한 표준입니다.
- TLS 통신에 사용되는 암호화 라이브러리
- OpenSSL 또는 Go crypto 모듈
- 해시 알고리즘 및 키 관리 방식
이러한 구성 요소가 FIPS 인증을 받은 구현체여야 한다는 의미입니다.
미국 연방 기관, 국방, 일부 금융 및 공공기관 환경에서는 FIPS 140–2 준수가 필수입니다. 일반적인 오픈소스 Kubernetes 빌드는 FIPS 인증을 전제로 하지 않기 때문에, 별도의 FIPS 빌드 또는 검증된 배포판이 필요합니다.
K3s의 기본 빌드는 FIPS 인증 환경을 기본 가정으로 하지 않습니다. 반면, RKE2는 FIPS 지원 빌드를 제공합니다.
K3s는 기본 CNI(Container Network Interface)로 Flannel을 사용합니다. Flannel은 단순하고 가벼운 오버레이 네트워크를 제공하며, 엣지 환경이나 소규모 클러스터에 적합합니다.
그러나 엔터프라이즈 환경에서는 네트워크 계층에서 보다 복잡한 요구사항이 발생합니다.
- 네임스페이스 단위의 세밀한 Network Policy 제어
- 멀티테넌시(Multi-tenancy) 환경에서의 격리 보장
- 서비스 간 mTLS 통신
- 트래픽 가시성(Observability) 확보
- 트래픽 제어(예: Canary 배포, A/B 테스트)
이 중 Network Policy 및 멀티테넌시는 CNI 레벨에서 해결해야 하는 문제입니다. 따라서 실제 엔터프라이즈 환경에서는 Flannel 대신 Calico나 Cilium과 같은 CNI를 사용하는 경우가 많습니다. 이들은 정책 기반 트래픽 제어를 지원합니다.
반면, 서비스 간 mTLS, 트래픽 가시성 확보, 트래픽 제어와 같은 기능은 일반적으로 Service Mesh 계층에서 해결합니다. 대표적인 구현체가 Istio입니다.
K3s에서는 이에 대한 요구사항을 기본 구성만으로는 제공되지 않으며 추가적인 네트워크 및 Service Mesh 설계를 전제로 합니다.
RKE2
앞서 살펴본 것처럼 K3s는 경량성과 단순성을 목표로 설계된 Kubernetes 배포판입니다. 단일 바이너리 모델, SQLite 기반 단일 노드 구성, 최소화된 의존성은 엣지 및 소규모 환경에서 강력한 장점을 제공합니다.
그러나 엔터프라이즈 환경에서는 단순한 실행 모델보다 Control Plane의 수명주기 관리 방식, Adds-on 배포 전략, 보안 기본값 적용 수준이 더 중요한 판단 기준이 됩니다.
RKE2는 바로 이 지점에서 출발합니다. K3s의 실행 모델을 계승하되, 운영 모델과 보안 기본값을 재정의한 배포판이 RKE2입니다.
Architecture
RKE2는 단일 바이너리 기반 실행 모델 위에 Control Plane, 내장 etcd, containerd, 기본 CNI, 시스템 애드온을 통합한 구조를 가집니다.
 Architecture
Architecture
위 구조에서 볼 수 있듯이, RKE2 Server 노드는 Static Pod 형태로 Control Plane을 실행하고, Agent 노드는 kubelet과 containerd를 통해 워크로드를 실행합니다.
Control Plane Management
kubeadm 기반 클러스터에서 Control Plane 컴포넌트(kube-apiserver, kube-controller-manager, kube-scheduler)는 /etc/kubernetes/manifests/ 경로에 배치된 Static Pod로 실행됩니다. kubelet이 해당 디렉토리를 확인하여 manifest가 생성되면 컨테이너를 기동하는 구조입니다.
# kubeadm Control Plane Static Pod 위치
/etc/kubernetes/manifests/
├── etcd.yaml
├── kube-apiserver.yaml
├── kube-controller-manager.yaml
└── kube-scheduler.yaml
RKE2 역시 kubeadm과 동일하게 Static Pod 모델을 사용합니다. 그러나 두 방식의 차이는 Control Plane manifest를 누가 생성하고, 어떻게 관리하는가에 있습니다.
kubeadm에서는 kubeadm init 또는 kubeadm upgrade 실행 시 Static Pod manifest가 생성됩니다. 이후 구성 변경이 필요한 경우 관리자가 /etc/kubernetes/manifests/ 경로의 manifest를 직접 수정해야 합니다. kubeadm은 Control Plane 구성을 지속적으로 관리하는 프로세스가 아닙니다.
반면 RKE2에서는 rke2 server 프로세스가 Control Plane 구성의 생성과 적용을 내부적으로 관리합니다. Control Plane manifest는 다음 경로에 생성됩니다.
# RKE2 Control Plane Static Pod 위치
/var/lib/rancher/rke2/agent/pod-manifests/
├── etcd.yaml
├── kube-apiserver.yaml
├── kube-controller-manager.yaml
├── kube-proxy.yaml
└── kube-scheduler.yaml
RKE2는 설정 파일(/etc/rancher/rke2/config.yaml)을 기준으로 Control Plane manifest를 동적으로 생성합니다. 설정이 변경되면 관련 manifest가 재생성되며, 컴포넌트 기동 순서(etcd → kube-apiserver → kube-controller-manager / kube-scheduler) 역시 내부 로직에 따라 조율됩니다.
즉 동일한 Static Pod 실행 모델을 사용하지만, Control Plane 구성의 수명주기를 배포판 수준에서 관리한다는 점이 차이입니다.
Add-on
kubeadm은 CoreDNS와 kube-proxy를 제외한 대부분의 애드온 설치를 관리자에게 위임합니다. CNI 선택, Ingress Controller 배포, Metrics Server 설치 등은 별도의 작업으로 수행해야 합니다.
Kubespray는 Ansible Role과 변수를 통해 이를 자동화합니다. RKE2는 애드온을 배포판 수준에서 관리합니다.
RKE2에는 Helm Controller가 포함되어 있습니다. Helm Controller는 K3s 프로젝트에서 도입된 경량 컨트롤러로, HelmChart와 HelmChartConfig라는 Custom Resource Definition(CRD)을 기반으로 Helm Chart를 자동 설치하고 관리합니다.
var/lib/rancer/rke2/server/manifests 디렉토리에 HelmChart 리소스가 정의된 manifest가 존재하면, Helm Controller가 이를 감지하고 지정된 Helm Chart를 다운로드하여 설치합니다.
# RKE2 서버 매니페스트 디렉토리
/var/lib/rancher/rke2/server/manifests/
├── rke2-canal-config.yaml
├── rke2-canal.yaml
├── rke2-coredns-config.yaml
├── rke2-coredns.yaml
├── rke2-metrics-server.yaml
└── rke2-runtimeclasses.yaml
CNI
kubeadm 기반 클러스터에서는 CNI를 직접 선택하고 설치해야 합니다. Flannel, Calico, Cilium 등 다양한 옵션이 존재하며, 선택과 구성은 전적으로 관리자 책임입니다.
RKE2는 설치 시 --cni 옵션을 통해 Canal, Calico, Cilium, Flannel 중 선택할 수 있습니다. RKE2는 기본 CNI로 Canal을 사용합니다.Canal은 독립적인 CNI 플러그인이 아니라, Flannel과 Calico를 하나의 DaemonSet 내에서 결합한 하이브리드 구성입니다.
- Flannel: Pod 간 오버레이 네트워크(VXLAN) 구성
- Calico: Kubernetes NetworkPolicy enforcement
따라서 실제 Canal Pod 내부에는 두 컨테이너가 함께 실행됩니다.
Pod가 다른 노드의 Pod로 패킷을 전송하면, Flannel의 flanneld 프로세스가 VXLAN 터널을 통해 패킷을 캡슐화하여 목적지 노드로 전달합니다. 수신 노드에서는 패킷이 역캡슐화되어 목적지 Pod로 전달됩니다.
이 과정에서 Calico의 calico-node는 iptables 또는 eBPF 규칙을 통해 Kubernetes NetworkPolicy를 적용합니다. 허용되지 않은 트래픽은 이 단계에서 차단됩니다.
즉, Flannel이 네트워크 연결을 담당하고, Calico가 정책 적용을 담당하는 구조입니다. RKE2는 이 구조를 기본 스택으로 제공합니다.
Canal은 Flannel의 단순한 네트워크 구성과 Calico의 정책 기반 제어를 결합하여, 기본 구성에서 NetworkPolicy 적용을 가능하게 합니다.
Process Lifecycle
RKE2의 부트스트랩 과정은 단일 바이너리 기반 설계가 실제로 어떻게 구현되는지를 가장 명확하게 보여주는 부분입니다.
kubeadm 기반 환경에서는 다음 단계가 명확히 분리되어 있습니다.
- kubeadm init
- CNI
- CoreDNS 및 Add-on 배포
각 단계는 운영자가 순서를 인지하고 수행해야 합니다.
반면 RKE2는 단일 rke2 server 프로세스가 내부적으로 초기화 순서를 조율합니다. 이 과정은 다음 네 단계로 구분할 수 있습니다.
- Content Bootstrap
- Initialize Server
- Initialize Agent
- Daemon Process
각 단계는 의존성 그래프에 따라 순차적으로 진행됩니다.
Content Boostrap
RKE2는 외부 패키지 관리자에 의존하지 않습니다. 시작 시점에 런타임 이미지를 기준으로 필요한 바이너리와 Helm Chart를 추출합니다.
사용되는 런타임 이미지는 다음 파일에서 확인할 수 있습니다.
cat /var/lib/rancher/rke2/agent/images/runtime-image.txt
# index.docker.io/rancher/rke2-runtime:v1.34.3-rke2r3
rke2-runtime 이미지는 단순한 컨테이너 이미지가 아니라, Kubernetes 실행에 필요한 바이너리와 시스템 애드온 Helm Chart를 모두 포함한 패키지입니다.
온라인 환경에서는 해당 이미지를 레지스트리에서 pull합니다. 그러나 Air-Gapped 에서는 이 이미지를 tarball 형태로 사전에 준비해야 합니다. 이 tarball은 일반적인 Docker image tar와 동일한 구조를 가집니다.
RKE2는 시작 시, /var/lib/rancher/rke2/agent/images/*.tar 경로의 로컬 tarball 확인후에 이미지가 존재하지 않는 경우, 원격 레지스트리에서 pull합니다.
이미지가 준비되면 RKE2는 이미지 내부의 /bin 디렉토리와 /charts 디렉토리를 추출합니다. /bin에는 containerd, kubelet, runc, kubectl, crictl 등의 실행 파일이 포함되어 있으며, /charts에는 Canal, CoreDNS, Metrics Server 등의 Helm Chart 정의가 포함되어 있습니다.
# rke2-runtime 이미지 내부 구조
├── bin
│ ├── containerd # CRI 구현체
│ ├── containerd-shim-runc-v2 # runc 태스크 래퍼
│ ├── crictl # CRI 저수준 점검 도구
│ ├── ctr # containerd 저수준 점검 도구
│ ├── kubectl # 클러스터 관리 도구
│ ├── kubelet # 노드 에이전트
│ └── runc # OCI 컨테이너 런타임
└── charts
├── rke2-canal.yaml
├── rke2-cilium.yaml
├── rke2-coredns.yaml
├── rke2-ingress-nginx.yaml
├── rke2-metrics-server.yaml
└── ...
추출된 바이너리는 /var/lib/rancher/rke2/data/${RKE2_DATA_KEY}/bin경로에 저장됩니다. ${RKE2_DATA_KEY} 는 이미지를 식별하는 고유 문자열을 나타냅니다.
Helm Chart는 /var/lib/rancher/rke2/server/manifests경로에 배치됩니다. 이 디렉토리는 이후 Helm Controller의 감시 대상이 됩니다.
Initialize Server
Content Bootstrap이 완료되면 RKE2는 Server 초기화 단계에 진입합니다. 이 단계의 핵심은 Control Plane 컴포넌트 간 의존성 관리입니다.
RKE2는 설정 파일(/etc/rancher/rke2/config.yaml)을 기준으로 Static Pod manifest를 생성합니다.
순서는 다음과 같은 의존성 그래프를 따릅니다.
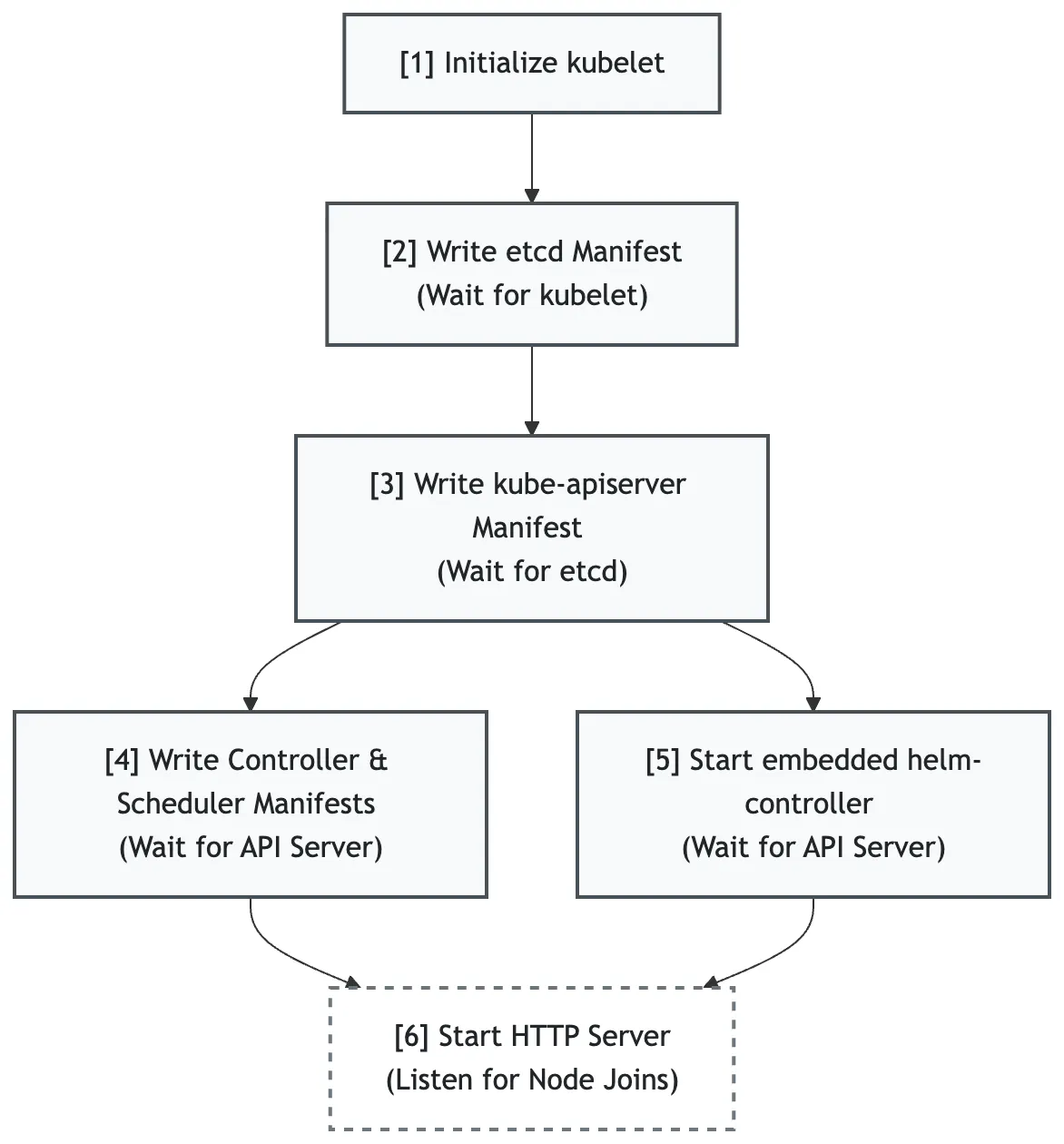 Control Plane 의존성 그래프
Control Plane 의존성 그래프
중요한 점은, 이러한 의존성 관계가 초기화 시점에 한 번 수행되는 것이 아니라 rke2 server 프로세스가 데몬으로 실행되면서 의존성 관계를 지속적으로 확인합니다.
Initialize Agent
Initialize Agent 단계는 RKE2가 containerd와 kubelet을 생성하고 감독하는 단계입니다. Server 노드에서 rke2 server를 실행하면 Control Plane 컴포넌트와 함께 containerd와 kubelet도 기동됩니다. Worker 노드에서 rke2 agent를 실행하는 경우에도 동일하게 containerd와 kubelet이 기동됩니다.
먼저 RKE2는 containerd를 자식 프로세스로 기동합니다. containerd는 CRI(Container Runtime Interface) 구현체로, 모든 Pod와 컨테이너 실행의 기반이 됩니다. containerd가 정상적으로 기동하지 않으면 노드는 워크로드를 실행할 수 없습니다. 따라서 containerd가 비정상 종료되면 RKE2 프로세스도 함께 종료됩니다.
containerd가 준비되면 kubelet이 실행됩니다. kubelet은 containerd 소켓에 연결되어 Pod를 관리합니다. kubelet이 비정상 종료될 경우 RKE2는 재시작을 시도합니다. kubelet은 복구 가능한 컴포넌트로 간주되기 때문입니다.
Server 노드에서는 kubelet이 /var/lib/rancher/rke2/agent/pod-manifests/ 경로를 감시하며, 해당 디렉토리에 생성된 Static Pod manifest를 기반으로 etcd와 kube-apiserver 등 Control Plane 컴포넌트를 기동합니다. Agent 노드에서는 Control Plane manifest가 존재하지 않으며, kubelet은 API Server에 연결하여 일반 워크로드를 실행합니다.
Daemon Process
Initialize 단계가 완료되면 rke2 server 또는 rke2 agent 프로세스는 종료되지 않고 계속 실행됩니다.
RKE2는 containerd와 kubelet을 직접 자식 프로세스로 실행하며, 두 프로세스의 상태를 지속적으로 확인합니다. systemd는 rke2-server.service 또는 rke2-agent.service를 통해 이 전체 프로세스 그룹을 관리합니다.
KillMode=process
Delegate=yes
Restart=always
KillMode=process는 systemd가 메인 프로세스(rke2)에만 시그널을 전달하도록 제한합니다. 기본값인control-group을 사용할 경우, 서비스 중지 시 containerd와 kubelet을 포함한 모든 하위 프로세스가 동시에 종료됩니다Delegate=yes는 cgroup 관리 권한을 RKE2 프로세스에 위임합니다. 이를 통해 containerd와 각 컨테이너 프로세스가 독립적인 cgroup에서 관리될 수 있습니다.Restart=always는 rke2 프로세스 자체가 비정상 종료될 경우 systemd가 자동으로 재시작하도록 보장합니다.
Comments