22 min to read
LLM Inference on Kubernetes
Abstract
최근 LLM 생태계는 빠른 발전에 맞춰 다양한 서비스와 스택이 등장하고 있습니다. 하지만 각각의 역할과 경계를 명확히 파악하기 어려웠으며, 이를 계기로 LLM 서빙 인프라가 Kubernetes 위에서 어떻게 동작하는지, 그리고 그 위에서 라우팅이 어떻게 이루어지는지 정리하고자 합니다.
From Ingress API to Gateway API
쿠버네티스 환경에서 마이크로서비스 아키텍처를 운영하다 보면 네트워크 라우팅 문제에 직면하게 됩니다. 클러스터 내부에는 수많은 Service가 존재하지만 이들 모두에게 외부 접속용 공인 IP(LoadBalancer 타입)를 할당하는 것은 비용 측면에서나 관리 측면에서나 매우 비효율적입니다. 결국 단일 진입점을 통해 들어온 트래픽을 URL 경로나 호스트 이름을 기반으로 적절한 내부 서비스로 분배해 줄 L7 로드밸런서가 필요하게 되며, 이 문제를 해결하기 위해 도입된 것이 Ingress API입니다.
인그레스는 클러스터 외부에서 클러스터 내부 서비스로 HTTP와 HTTPS 경로를 노출합니다. 트래픽 라우팅은 인그레스 리소스에 정의된 규칙에 의해 컨트롤됩니다. 이를 통해 Domain/Path기반 라우팅이나 TLS Termination을 단일 리소스로 표현할 수 있게 되었고 NGINX, Traefik, HAProxy 같은 다양한 컨트롤러가 이 스펙을 구현했습니다.
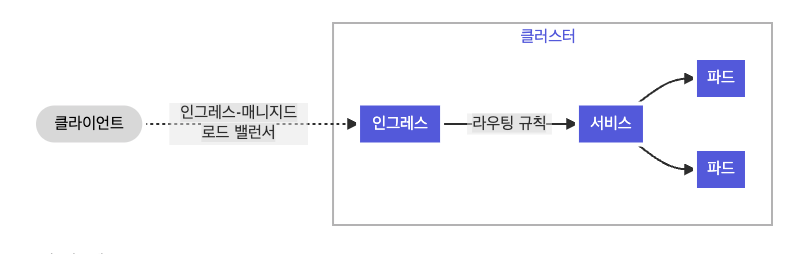
그러나 실제 운영 환경이 복잡해지면서 Ingress의 구조적 한계가 드러나기 시작했습니다.
Ingress API 자체가 지원하는 기능은 매우 제한적이었습니다. 카나리 배포, 요청 재시도, Rate Limit, 헤더 조작 같은 기능은 API 스펙에 존재하지 않았기 때문에, 각 구현체는 annotation을 통해 기능을 확장했습니다.
# NGINX Ingress Controller에서만 유효한 annotation
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "20"
nginx.ingress.kubernetes.io/rate-limit: "100"
위의 annotation들은 NGINX 전용 확장이기 때문에 다른 컨트롤러로 교체하게 되면 위의 annotation들은 적용되지 않습니다. 컨트롤러별 확장이 표준 스펙 밖에서 제각각 정의되면서 실제 운영 설정은 특정 컨트롤러에 종속되어 컨트롤러 교체 시, 동일한 동작을 보장하기 어려웠습니다.
또 다른 한계는 역할 분리를 구조적으로 표현하기 어렵다는 점입니다. 실제 조직에서 트래픽 구성의 책임은 여러 팀에 나뉘어 있습니다. 인프라팀은 로드밸런서와 네트워크 계층을, 플랫폼팀은 TLS 인증서·보안 정책을, 개발팀은 서비스별 라우팅 규칙을 관리합니다. 그러나 Ingress 모델에서는 이러한 관심사가 하나의 리소스로 수렴하기 쉽고, 결과적으로 서로 다른 책임이 같은 오브젝트에서 충돌합니다.
이 구조는 두 가지 운영 비용을 만듭니다.
- 개발팀이 라우팅 규칙 하나를 수정하려면 같은 Ingress 리소스에 포함된 TLS 정책 관련 설정과 함께 변경을 관리해야 하므로 역할이 분리되지 않습니다.
- 플랫폼팀이 클러스터 전반에 일관되게 적용해야 하는 보안 정책은 Ingress 스펙만으로는 전역 정책으로 분리해 선언하기 어렵고, 결국 서비스별 Ingress에 반복적으로 설정되거나 컨트롤러별 확장 기능에 의존하게 됩니다.
결국 Ingress는 API 레벨에서 역할과 책임을 분리해 선언할 수 있는 기본 단위가 부족했고, 이는 규모가 커질수록 운영 복잡도를 더 높이게 되었습니다.
Gateway API
이러한 한계를 해결하기 위해 Kubernetes SIG-Network가 설계한 것이 Gateway API입니다. 2023년 10월 v1.0 GA를 출시하면서 Ingress API는 frozen상태로 더 이상 새로운 기능이 추가되지 않고 있습니다. 2026년 3월에는 가장 널리 사용되던 Ingress NGINX Controller의 공식 지원이 종료될 예정입니다.
Gateway API의 핵심 설계 원칙은 단일 리소스를 역할에 따라 세 개의 계층으로 분리하는 것입니다.
- GatewayClass
- Gateway
- HTTP/TCP/GRPC Route
GatewayClass를 통해 클러스터에서 사용할 Gateway API 컨트롤러를 선언하고, Gateway로 리스너(포트, 프로토콜)와 TLS같은 설정을 운영합니다. HTTPRoute로 서비스별 라우팅 규칙을 독립적으로 정의합니다. 이 리소스들은 서로 다른 범위와 책임을 가지도록 설계되어 있어 Kubernetes RBAC을 리소스 단위로 분리해 적용하기가 상대적으로 수월합니다.
또한 Gateway API는 Ingress에서 annotation를 통해 지원하던 각기 다른 요구사항들을 스펙의 구조화된 필드로 정의하였습니다. 예를 들어 가중치 기반 트래픽 분할은 HTTPRoute의 backendRefs weight로 표준적으로 표현할 수 있습니다.
Challenge
일반적인 웹 트래픽 라우팅에는 Round-Robin 방식의 단순 부하 분산 알고리즘이 널리 사용됩니다. 그러나 LLM 추론 트래픽은 각 인스턴스의 현재 상태에 따라 처리 성능의 차이가 크게 발생합니다. 모델 서버의 KV Cache 상태, 활성화된 LoRA Adapter 목록, 현재 대기 중인 요청 수 등 동적인 요소를 고려하지 않고 트래픽을 분산할 경우 리소스 낭비와 응답 지연이 발생합니다. 이러한 문제를 해결하기 위해 표준 Kubernetes 환경 위에서 동작하는 LLM 특화된 라우팅 및 스케줄링 로직이 필요합니다.
Kubernetes Gateway API Inference Extension란 Kubernetes 환경에서 대규모 언어 모델(LLM) 추론 워크로드를 효율적으로 처리하기 위한 라우팅 확장 기술입니다. 이 프로젝트는 Gateway API와 Envoy의 External Processing(ext-proc)을 활용해, 기존 Gateway를 inference-aware gateway로 확장합니다. 즉 트래픽을 단순 분산하는 것을 넘어 각 모델 서버의 실시간 상태에 기반한 동적 라우팅을 제공합니다.
Gateway API Inference Extension optimizes self-hosting Generative AI Models on Kubernetes. It provides optimized load-balancing for self-hosted Generative AI Models on Kubernetes. The project’s goal is to improve and standardize routing to inference workloads across the ecosystem.
Architecture
해당 프로젝트는 두 가지 레이어를 결합합니다.
- Gateway API: 어떤 요청을 어떤 백엔드로 보낼지를 Kubernetes 리소스로 선언
- Envoy ext-proc: 요청 처리 중간에 외부 서비스(EPP)에게 어디로 보낼지 판단을 위임
이를 통해, Gateway(Envoy, Istio 등)는 L7 프록시 역할을 유지하면서도 inference 스케줄링 로직을 외부로 분리해 확장할 수 있습니다.
Envoy Filter Chain and ext-proc Protocol
Envoy 프록시는 트래픽을 처리할 때 Filter Chain이라는 일련의 처리 단계를 거칩니다. 이 중 ext-proc(External Processing) 프로토콜은 Envoy가 요청을 처리하는 중간에 외부 서비스와 통신하여 라우팅 결정을 위임할 수 있도록 지원하는 기능입니다. 이를 통해 프록시 내부 로직을 직접 수정하지 않고도 외부의 복잡한 스케줄링 알고리즘을 라우팅 과정에 통합할 수 있습니다.
Envoy Gateway에서는 EnvoyExtensionPolicy를 통해 ext-proc 필터를 HTTPRoute 또는 Gateway에 선언적으로 연결할 수 있습니다.
Endpoint Picker (EPP)
EPP는 Gateway API Inference Extension(GIE)에서 정의하는 ext-proc 기반의 외부 inference routing 서비스로, data, routing, flow control, scheduling 레이어를 통해 요청을 처리할 최적의 endpoint를 선택합니다.
EPP는 대상 InferencePool에 속한 각 Pod가 노출하는 metrics 및 capabilities를 바탕으로 endpoint를 평가하고, 구현된 scheduling policy에 따라 최적의 Pod를 선택합니다. 예를 들어 vLLM 기반 환경에서는 Queue depth, KV cache utilization, LoRA adapter availability 같은 신호를 활용할 수 있습니다.
즉, GIE는 EPP의 역할과 아키텍처를 표준화하였고, 여러 구현체들이 존재합니다.
Request Routing Flow
트래픽 처리는 표준 Kubernetes 라우팅 규칙과 확장된 동적 스케줄링이 결합된 형태로 진행됩니다.
요청 라우팅은 다음 2단계로 이루어집니다.
- HTTPRoute는 수신된 요청을 매칭한 뒤, backendRef로 지정된 InferencePool로 트래픽을 전달합니다.
- 트래픽이 프록시에 도달하면 Envoy는 ext-proc 프로토콜을 사용하여 EPP에게 해당 InferencePool 내에서 어떤 Pod로 요청을 보낼지 질의합니다. EPP가 메트릭을 기반으로 최적의 Pod를 선택하여 응답하면, Envoy는 해당 Pod로 최종 트래픽을 전달합니다.
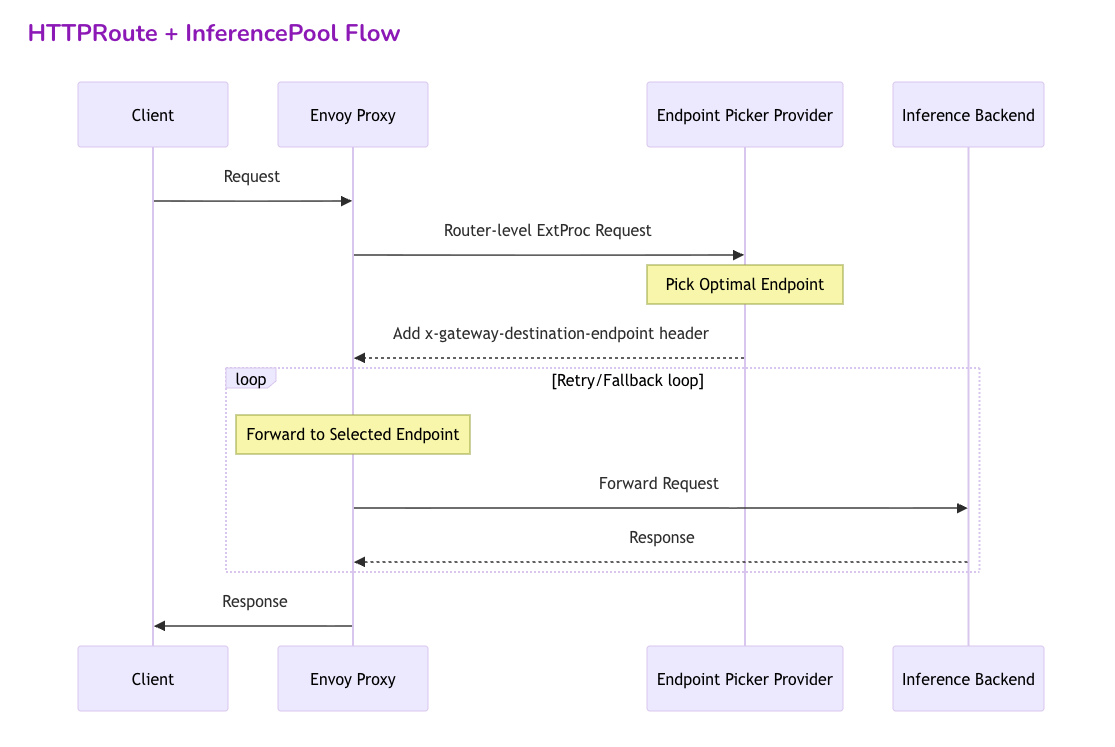 https://aigateway.envoyproxy.io/docs/capabilities/inference/inferencepool-support/#httproute–inferencepool-flow
https://aigateway.envoyproxy.io/docs/capabilities/inference/inferencepool-support/#httproute–inferencepool-flow
Components
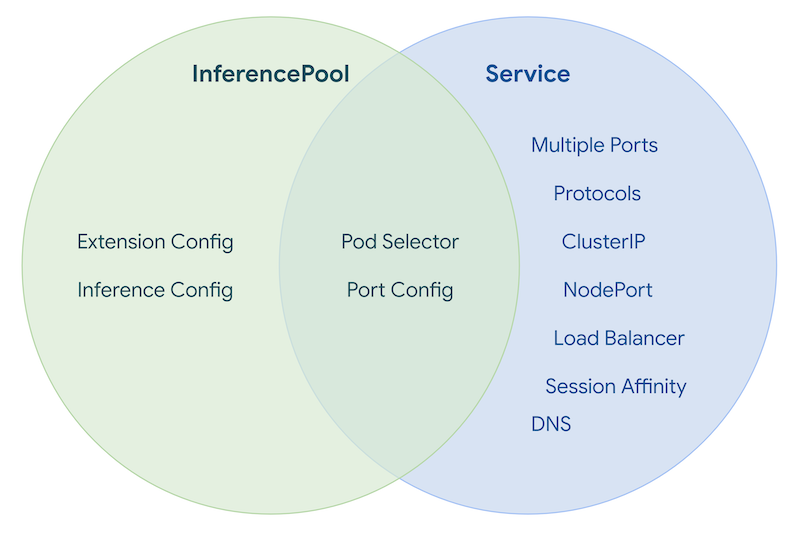
Kubernetes 기본 리소스만으로는 AI 추론 워크로드의 복잡한 라우팅 요구사항과 정책을 표현하기 어렵습니다. 이를 해결하기 위해 프로젝트에서 CRD를 도입했습니다.
기존 Kubernetes의 Service 리소스는 단순한 엔드포인트 목록을 제공하며 트래픽을 무작위 또는 순차적으로 분산하는 데 그칩니다.
이러한 한계를 극복하고 AI 모델 서비스에 최적화된 라우팅을 구현하기 위해, 추론 대상을 정의하는 InferencePool과 라우팅 정책을 정의하는 InferenceObjective라는 두 가지 리소스로 분리하여 설계했습니다.
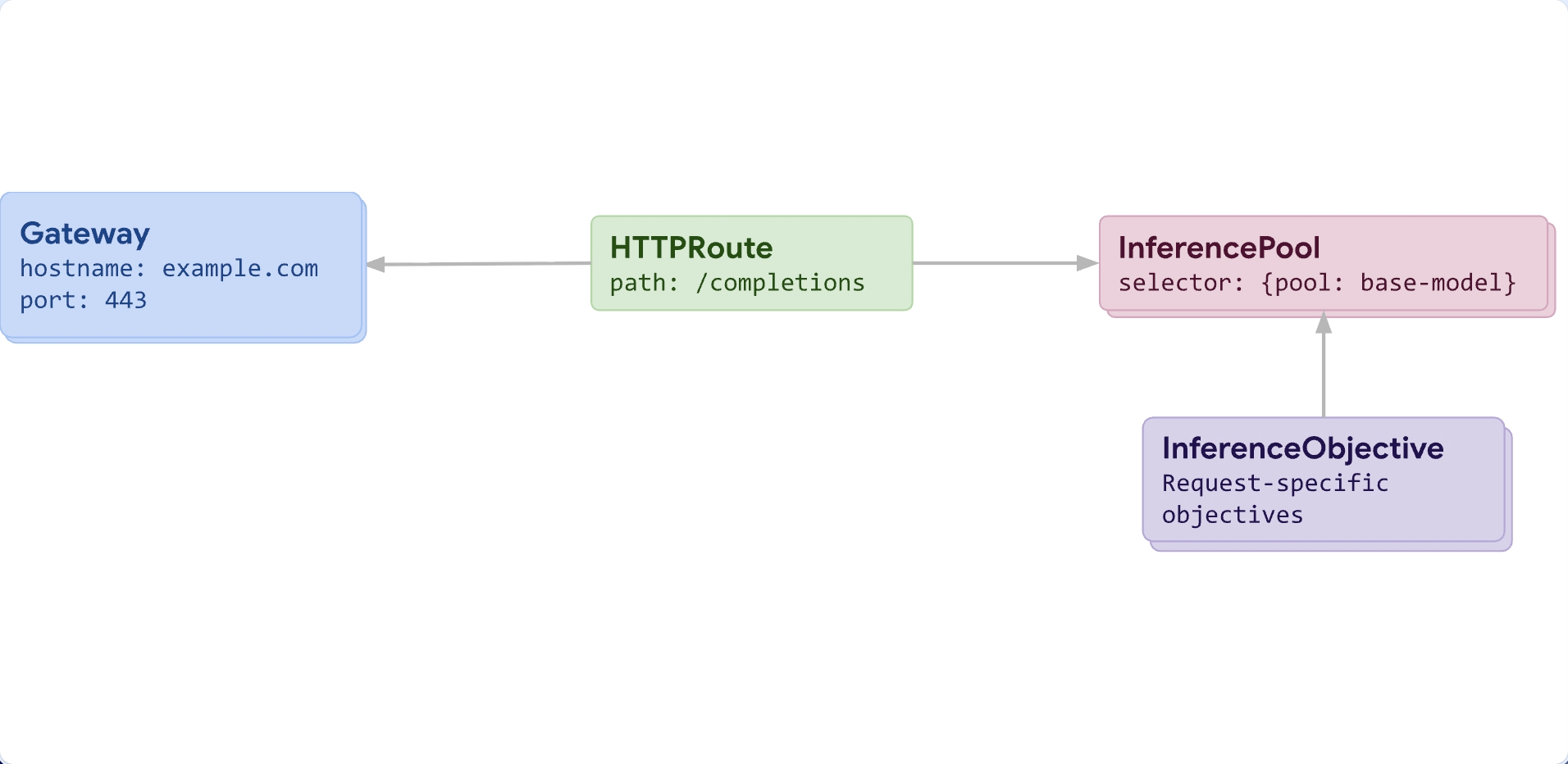
InferencePool
InferencePool은 HTTPRoute에서 backend로 지정될 수 있는 LLM 백엔드 풀입니다. Kubernetes 블로그/문서에서도 InferencePool을 Service 유사 개념으로 설명하며, AI/ML 서빙 요구를 반영해 설계된 리소스로 소개합니다.
InferencePoolSpec은 세 가지 주요 부분으로 구성됩니다.
selector: 어떤 Pod들이 InferencePool에 속해야 하는지를 라벨 셀렉터로 지정targetPorts: 게이트웨이가 해당 Pod로 트래픽을 보낼 때 사용할 Pod의 포트 번호endpointPickerRef: InferencePool이 엔드포인트 선택(Endpoint Selection)을 위임할 확장(Extension)을 지정하는 필드
InferenceObjective
InferenceObjective는 스케줄링 또는 라우팅 의사결정에 들어가는 정책을 표현합니다. 현재 스펙은 priority 중심으로 설계되어 있으며, 문서에서는 향후 SLO 달성 여부 같은 필드로 확장될 수 있음을 명시합니다.
poolRef: 어떤 InferencePool에 적용되는 objective인지 연결priority: objective 우선순위
특정 요청을 InferenceObjective 정책에 따라 처리하고 싶다면, 클라이언트는 아래와 같이 HTTP 헤더를 설정합니다. 시스템은 이 헤더를 감지하여 요청을 적절한 Objective와 연결된 스케줄링 로직에 반영합니다.
- Key:
x-gateway-inference-objective - Value: 적용할 InferenceObjective의 metadata.name
Implementations
CRD를 설치했다고 라우팅이 자동으로 되는 것은 아닙니다. Gateway API의 실제 동작은 컨트롤러가 담당하므로 사용하는 Gateway 구현체가 inference extension을 지원하는지 확인해야 합니다.
지원되는 Gateway 목록으로 Envoy AI Gateway, Istio, kgateway, GKE, NGINX Gateway Fabric 등이 있습니다.
일반적으로 조직의 요구사항에 맞춰서 선택하는 것이 중요하지만, 해결하려는 문제의 범위와 운영 모델은 조금씩 다릅니다.
Istio는 범용 서비스 메시로서 mesh에 포함된 각 워크로드 Pod에 Envoy 데이터플레인을 배치하는 전통적인 sidecar 모델을 사용해 왔고, Envoy AI Gateway는 게이트웨이 계층의 Envoy Proxy Pod에 AI-specific ExtProc를 sidecar로 결합하는 구조를 사용합니다.
따라서 둘 다 Envoy 기반이지만, 전자는 클러스터 전반의 네트워크 정책과 서비스 간 통신에 더 가깝고, 후자는 AI 요청 처리를 위한 게이트웨이 계층에 더 집중된다고 볼 수 있습니다.
Envoy AI Gateway
Envoy AI Gateway는 Envoy Proxy와 Gateway API 위에서 동작하는 오픈소스 AI Gateway 프로젝트로, Bloomberg와 Tetrate가 주도하여 시작되었습니다. 2025년 2월 v0.1을 출시한 이후 v0.5까지 빠르게 진화하고 있으며, v0.3부터 Gateway API Inference Extension의 Endpoint Picker Provider 통합이 추가되었습니다.
Envoy AI Gateway는 트래픽의 출처와 목적지에 따라 두 개의 계층으로 역할을 구분합니다.
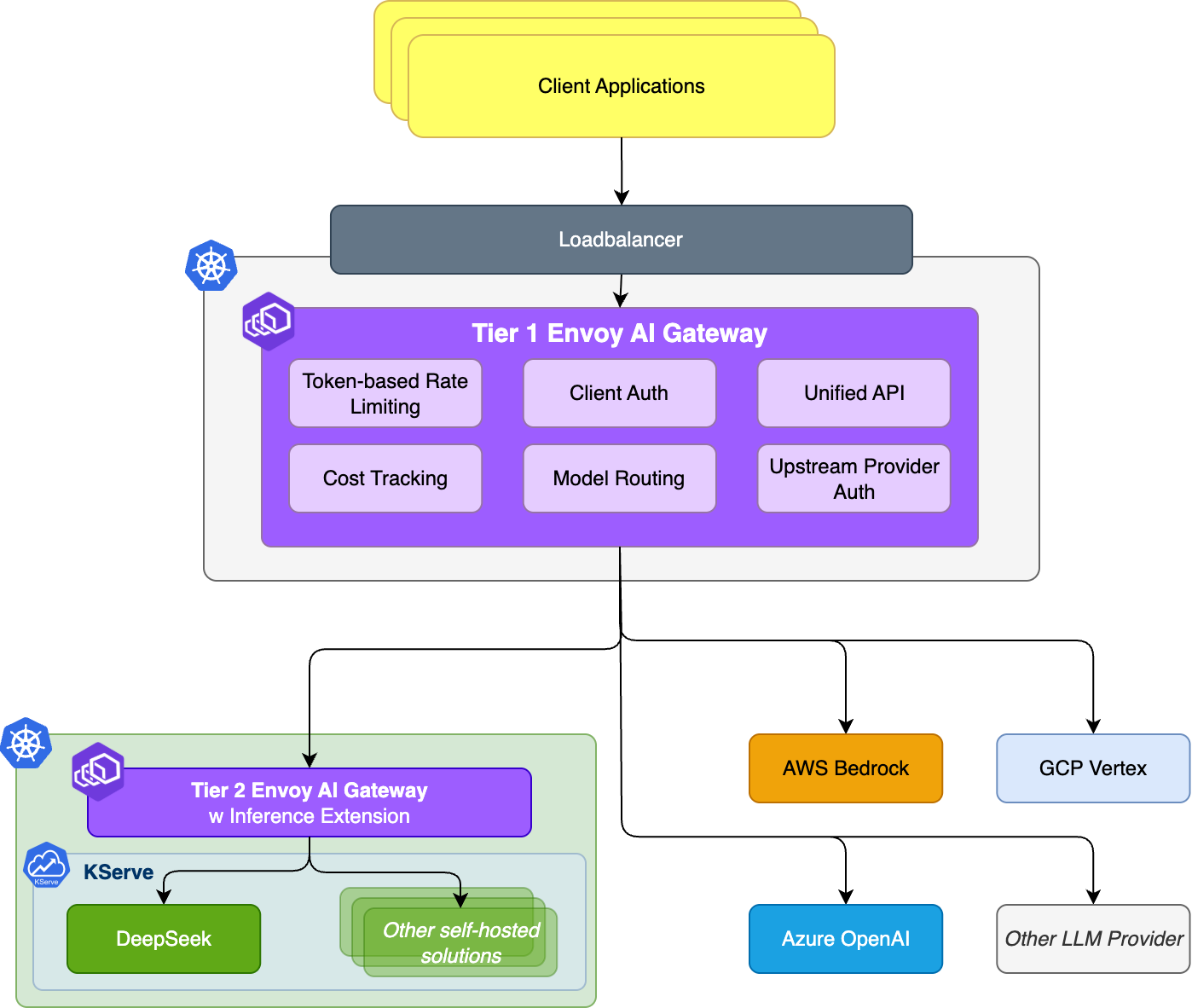
- 트래픽을 외부 LLM 제공자(예: OpenAI, Anthropic, Bedrock, Vertex)로 라우팅하거나 적절한 내부 게이트웨이로 라우팅하여 내부 모델 서비스 클러스터에 접근
- KServe와 같은 플랫폼에서 self-hosted 모델에서 실행되는 내부 트래픽 라우팅, 부하 분산 및 정책등을 처리하며, 해당 티어에서 Inference extension이 동작합니다.
즉 이를 통해 Envoy AI Gateway는 Envoy Gateway에서 Layer1과 같이 LLM기능을 추가하였고, v0.3부터 Gateway API Inference Extension을 통합하여 Layer2까지 확장된 것으로 볼수 있습니다.
여기서 주목할점은 Envoy AI Gateway가 InferencePool을 backendRef로 참조할 수 있게 된 것이지 EPP자체는 별도의 Pod으로 동작합니다.
Layer1
AIGatewayRoute
클라이언트가 단일 엔드포인트(OpenAI 호환 API)로 요청하면, 내부적으로 OpenAI / AWS Bedrock / Azure / GCP Vertex AI 등 서로 다른 스키마의 백엔드로 변환 및 라우팅하는 리소스가 AIGatewayRoute입니다.
라우팅은 HTTP헤더(x-ai-eg-model)를 기반으로 매칭이 이뤄집니다. AI Gateway의 ExternalProcessor(ExtProc)가 요청 Body에서 필드를 읽어서 헤더를 주입합니다.
AIGatewayRoute는 사용자 편의를 위한 추상화 CRD입니다. Envoy는AIGatewayRoute를 직접 이해하지 못하기 때문에, Controller가 이를 Envoy가 실제로 읽을 수 있는HTTPRoute로 자동 변환합니다. 이 변환 과정에서 ExtProc 연결도 자동으로 구성되며, 사용자는 백엔드별 스키마 차이를 신경 쓰지 않아도 됩니다.
각 Rule은 헤더 매칭 조건(matches)과 라우팅 대상(backendRefs)으로 구성됩니다.
backendRefs에서 참조할 수 있는 리소스는 AIServiceBackend와 InferencePool 두 가지입니다. 단, 한 Rule 안에서는 반드시 하나의 타입만 사용해야 하며, InferencePool을 참조하는 경우 해당 Rule에 1개만 허용됩니다.
AIServiceBackend는 여러 개를 등록해 weight(트래픽 분산)나 priority(우선순위 기반 fallback)를 설정할 수 있지만, InferencePool은 fallback을 포함한 로드밸런싱을 pool 내부의 endpoint picker가 담당하므로 외부에서 별도로 제어하지 않습니다.
# AIGatewayRoute
rules:
# OpenAI
- matches:
- headers:
- name: x-ai-eg-model
value: gpt-5.2
backendRefs:
- name: openai-backend
# Anthropic
- matches:
- headers:
- name: x-ai-eg-model
value: sonnet-4.6
backendRefs:
- name: anthropic-backend
modelNameOverride: anthropic.claude-sonnet-4-6
weight: 100
# Custom Model
- matches:
- headers:
- name: x-ai-eg-model
value: demo-model
backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: demo-inference-pool
AIServiceBackend
AIServiceBackend는 각 외부 백엔드의 API 스펙을 정의하는 리소스입니다. schema.name에 지정한 값을 기준으로 ExtProc가 요청 및 응답 변환을 수행합니다.
지원되는 schema.name 값은 현재 기준으로 OpenAI, Anthropic, AWSBedrock, AzureOpenAI, GCPVertexAI, GCPAnthropic, AWSAnthropic, Cohere입니다.
백엔드마다 요구하는 헤더 스펙이 다르기 때문에 headerMutation으로 헤더 방식을 오버라이드 할 수 있습니다.
# AIServiceBackend - OpenAI
apiVersion: aigateway.envoyproxy.io/v1alpha1
kind: AIServiceBackend
metadata:
name: openai-backend
spec:
schema:
name: OpenAI
version: v1
prefix: /v1
backendRef:
name: openai-endpoint
port: 443
---
# AIServiceBackend - Anthropic
apiVersion: aigateway.envoyproxy.io/v1alpha1
kind: AIServiceBackend
metadata:
name: anthropic-backend
spec:
schema:
name: Anthropic
version: v1
backendRef:
name: anthropic-endpoint
port: 443
headerMutation:
set:
- name: "anthropic-version"
value: "2023-06-01"
OpenAI, Anthropic 같은 경우, 외부 인터넷 API를 대상으로 하기 때문에 Envoy Gateway가 제공하는 Backend 리소스를 사용해 외부 FQDN을 엔드포인트로 직접 지정하도록 해야 합니다. 물론 이 또한 LiteLLM 같은 Proxy로 보내도록 지정하면 스키마 변환을 Proxy에 위임할 수 있어서 라우팅, 인증 등만 Gateway에서 처리되도록 역할 분리를 할 수도 있습니다.
# Envoy Gateway Backend - OpenAI
apiVersion: gateway.envoyproxy.io/v1alpha1
kind: Backend
metadata:
name: openai-endpoint
spec:
endpoints:
- fqdn:
hostname: api.openai.com
port: 443
---
# Envoy Gateway Backend - Anthropic
apiVersion: gateway.envoyproxy.io/v1alpha1
kind: Backend
metadata:
name: anthropic-endpoint
spec:
endpoints:
- fqdn:
hostname: api.anthropic.com
port: 443
BackendSecurityPolicy
BackendSecurityPolicy는 Gateway에서 백엔드로 나가는 트래픽의 인증을 담당합니다. 앞서 headerMutation으로 API Key를 직접 넣을 수도 있지만, 인증 정보는 BackendSecurityPolicy로 분리해서 관리하는 것이 권장됩니다.
targetRefs로 AIServiceBackend를 지정해 연결하며, 하나의 AIServiceBackend에 여러 BackendSecurityPolicy를 붙이는 것은 불가합니다.
apiVersion: aigateway.envoyproxy.io/v1alpha1
kind: BackendSecurityPolicy
metadata:
name: anthropic-auth
spec:
targetRefs:
- name: anthropic-backend
type: AnthropicAPIKey
anthropicAPIKey:
secretRef:
name: anthropic-secret # K8s Secret으로 관리
---
apiVersion: aigateway.envoyproxy.io/v1alpha1
kind: BackendSecurityPolicy
metadata:
name: openai-auth
spec:
targetRefs:
- name: openai-backend
type: APIKey
apiKey:
secretRef:
name: openai-secret
지원하는 인증 타입은 다음과 같습니다.
| type | 대상 |
|---|---|
APIKey |
범용 API Key (Authorization 헤더에 주입) |
AnthropicAPIKey |
Anthropic (x-api-key 헤더에 주입) |
AzureAPIKey |
Azure OpenAI (api-key 헤더에 주입) |
AzureCredentials |
Azure OIDC 기반 인증 |
AWSCredentials |
AWS STS, IRSA, Pod Identity 등 |
GCPCredentials |
GCP Workload Identity, 서비스 계정 등 |
Layer2
InferencePool
Layer 1의 AIGatewayRoute에서 내부 self-hosted 모델로 라우팅된 트래픽은 InferencePool이 처리합니다.
InferencePool은 동일한 모델을 서빙하는 Pod들을 하나의 풀로 묶고, endpoint picker가 KV-cache 상태 등 추론 서버 내부 정보를 기반으로 최적의 Pod을 동적으로 선택합니다. 로드밸런싱과 fallback 모두 pool 내부에서 처리됩니다.
# InferencePool - demo-model
apiVersion: inference.networking.k8s.io/v1alpha2
kind: InferencePool
metadata:
name: demo-inference-pool
spec:
targetPorts:
- number: 8000
selector:
matchLabels:
app: demo-model-server # 이 라벨을 가진 Pod들을 풀로 관리
endpointPickerRef:
name: demo-endpoint-picker # Pod 선택 로직을 담당하는 endpoint picker
port:
number: 9002
단순 테스트 용도라면 LLM API 없이 AI Gateway를 테스트하기 위한 Mock 서버인
testupstream으로 검증할 수 있습니다.
EPP
InferencePool의 endpointPickerRef가 가리키는 구현체로 EPP는 독립적인 gRPC 서버로 동작하며, Envoy로부터 라우팅 요청을 받아 Pool 내 최적의 Pod를 선택해 반환합니다.
EPP의 Pod 선택 알고리즘은 플러그인 방식으로 구성됩니다.
queue-scorer: 대기 요청이 적은 Pod 우선kv-cache-utilization-scorer: KV-cache 사용률이 낮은 Pod 우선prefix-cache-scorer: 동일 prefix 캐시가 있는 Pod 우선 (TTFT 감소)
플러그인 설정은 ConfigMap으로 주입됩니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-epp-config
namespace: default
data:
default-plugins.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: queue-scorer
- type: kv-cache-utilization-scorer
- type: prefix-cache-scorer
schedulingProfiles:
- name: default
plugins:
- pluginRef: queue-scorer
- pluginRef: kv-cache-utilization-scorer
- pluginRef: prefix-cache-scorer
RBAC
EPP는 InferencePool 리소스와 Pool에 속한 Pod 정보를 읽어야 하므로 별도의 RBAC이 필요합니다.
# ServiceAccount + RBAC
apiVersion: v1
kind: ServiceAccount
metadata:
name: demo-endpoint-picker
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: demo-endpoint-picker
rules:
- apiGroups: ["inference.networking.k8s.io"]
resources: ["inferencepools"]
verbs: ["get", "watch", "list"]
- apiGroups: ["inference.networking.x-k8s.io"]
resources: ["inferenceobjectives", "inferencemodelrewrites"]
verbs: ["get", "watch", "list"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: demo-endpoint-picker
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: demo-endpoint-picker
subjects:
- kind: ServiceAccount
name: demo-endpoint-picker
namespace: default
Routing Strategies Beyond Round-Robin
모델 서빙 엔진으로 널리 사용되는 vLLM과 별개로 단일 vLLM 인스턴스가 감당할 수 없는 분산 규모의 문제를 해결하고자 Kubernetes Native환경에 맞춰서 vLLM Production Stack과 llm-d가 등장하면서 라우팅 전략도 함께 고도화되었습니다.
vLLM Production Stack의 경우, Python 기반 커스텀 라우터를 사용하지만 llm-d는 kgateway를 기반으로 GIE가 확장된 구조입니다.
Prefix Aware Routing
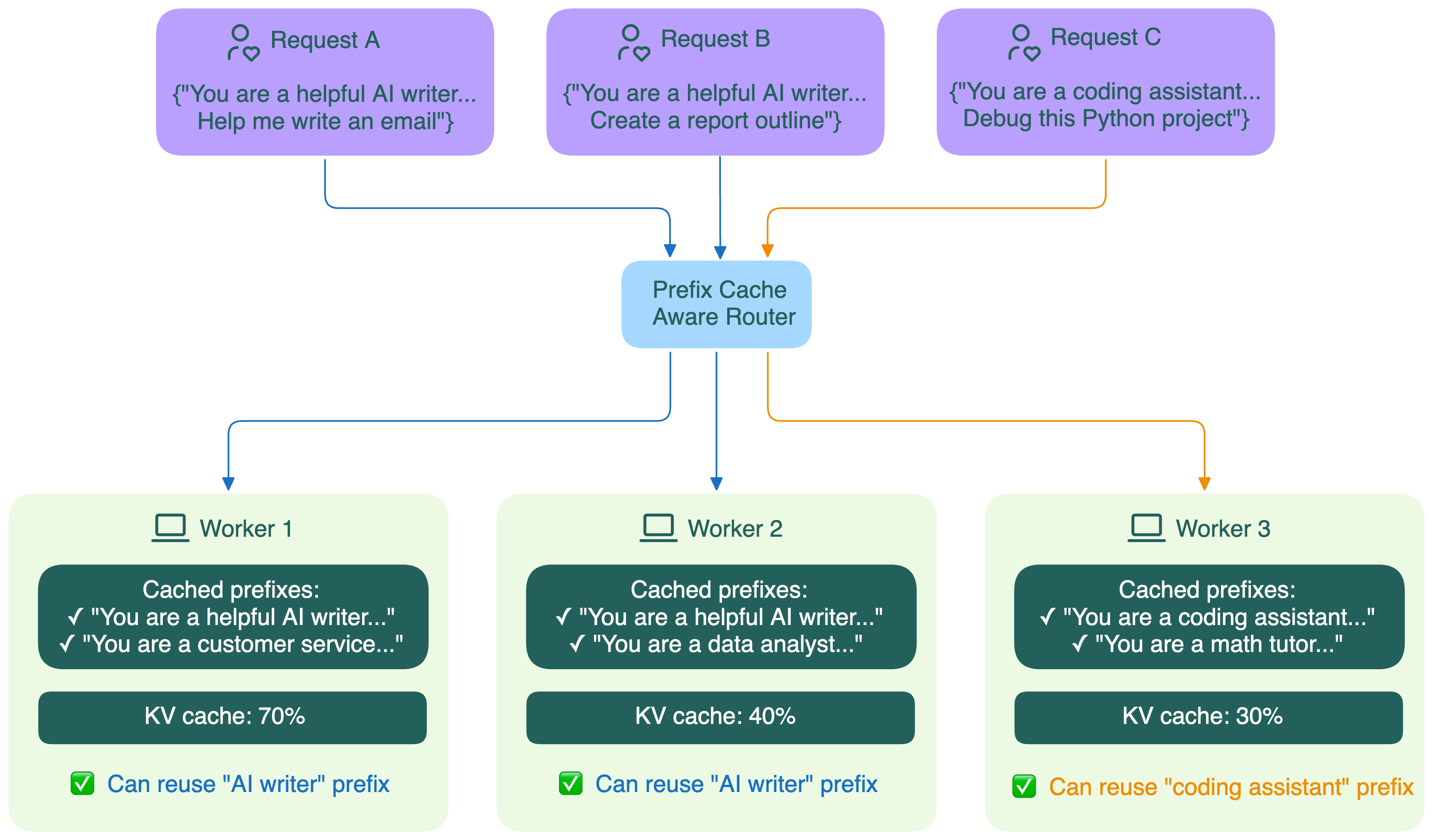
LLM 서비스에서는 서로 다른 사용자 요청처럼 보이더라도, 실제로는 앞부분 프롬프트가 상당 부분 겹치는 경우가 많습니다. 예를 들어 동일한 시스템 프롬프트를 공유하는 챗봇, 같은 코드베이스를 대상으로 하는 코드 어시스턴트, 비슷한 템플릿을 반복 사용하는 에이전트 워크플로우에서는 공통 prefix가 자주 발생합니다.
 https://bentoml.com/llm/inference-optimization/prefix-aware-routing
https://bentoml.com/llm/inference-optimization/prefix-aware-routing
Prefix-aware Routing은 이러한 문제를 줄이기 위한 전략입니다. 공통된 prefix를 가진 요청을 가능한 한 같은 Pod로 보내어, 이미 만들어진 prefix cache를 재사용하도록 유도합니다. 이를 통해 첫 토큰 생성 시간(TTFT)을 줄이고, 동일한 GPU 자원으로 더 많은 요청을 효율적으로 처리할 수 있습니다.
- Hash Based: 각 Query의 prefix 토큰들을 해시하여 특정 인스턴스와 매핑
- Cache-State Based: 각 인스턴스가 보유한 KV cache에 대해 Query와 longest prefix match를 계산하고, 가장 긴 prefix를 재사용할 수 있는 인스턴스로 요청을 라우팅
- Trie-based: 각 인스턴스가 보유한 KV cache의 prefix 정보를 Trie 형태로 관리하여, Query와의 longest prefix match를 좀 더 효율적으로 계산하는 방식
KV Cache-aware Routing
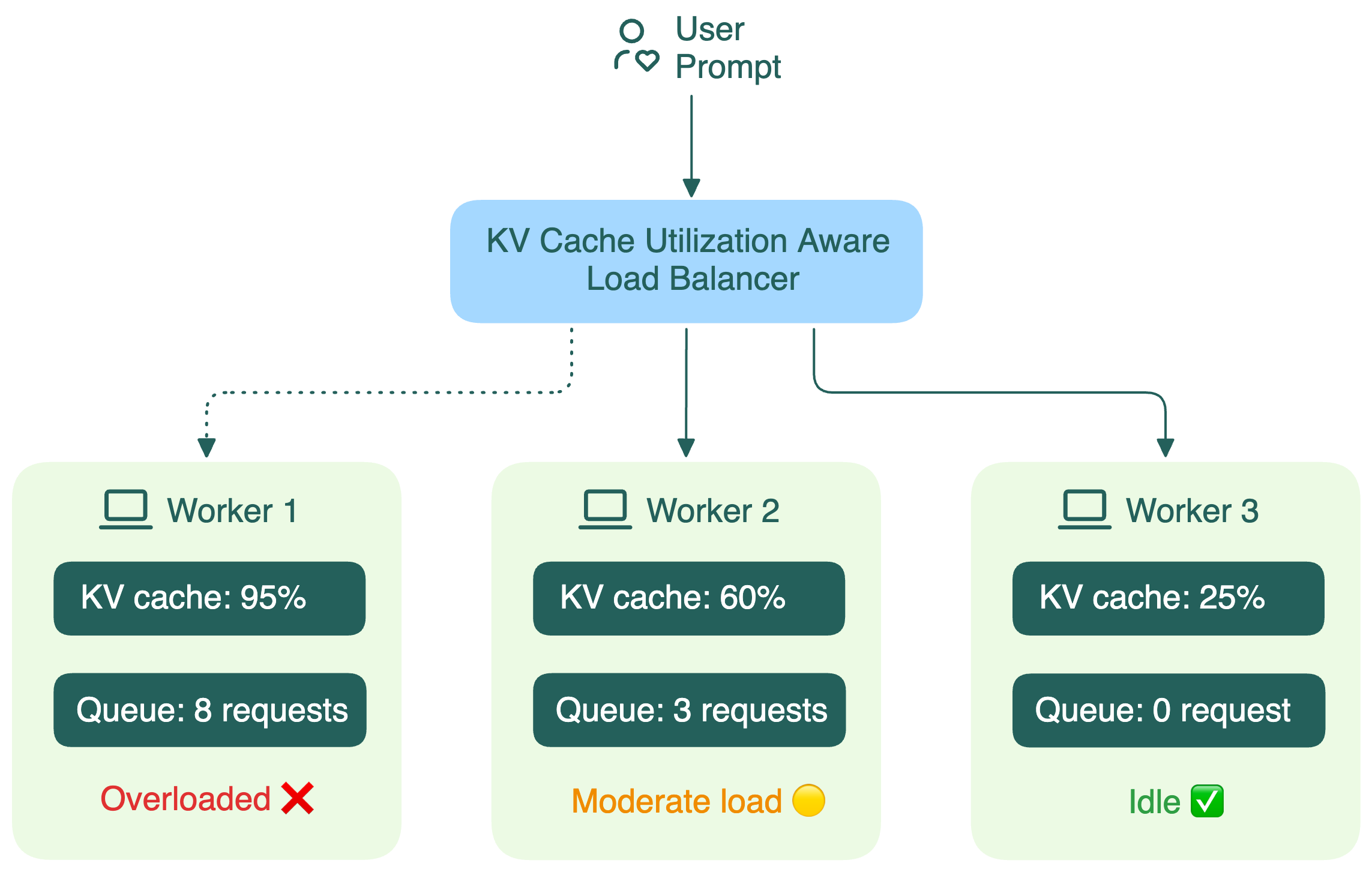
LLM은 텍스트를 한 토큰씩 순서대로 생성합니다. 이 과정에서 이전 토큰들에 대한 어텐션 계산 결과를 메모리에 저장해 재사용하는데, 이 구조를 KV-Cache(Key-Value Cache)라고 합니다. KV-Cache는 생성 속도를 높이는 핵심 메커니즘이지만, 처리 중인 요청이 많을수록, 요청이 길수록 GPU 메모리(VRAM)를 비례하여 소비합니다.
하지만 KV Cache는 무한하지 않습니다. 특정 Pod의 KV Cache 사용률이 지나치게 높아지면 메모리 압박이 커지고, 새로운 요청을 처리할 때 성능 저하가 발생할 수 있습니다. 또한 대기 중인 요청 수가 많은 Pod에 트래픽이 계속 몰리면, 전체 지연 시간이 급격히 증가할 수 있습니다.
KV Cache-aware Routing은 이러한 상태를 고려해 요청을 분배하는 전략입니다. 각 Pod의 KV Cache 사용률, 대기 요청 수, 현재 처리 중인 요청 상태 등을 함께 보고, 과부하된 인스턴스를 피하면서도 캐시 재사용 이점을 해치지 않는 방향으로 트래픽을 보냅니다.
 https://bentoml.com/llm/inference-optimization/kv-cache-utilization-aware-load-balancing
https://bentoml.com/llm/inference-optimization/kv-cache-utilization-aware-load-balancing
Disaggregated Prefill/Decode
LLM 추론은 크게 두 단계로 나눌 수 있습니다. 먼저 사용자의 프롬프트 전체를 한 번에 읽고 계산하는 prefill 단계가 있고, 그 다음에는 한 토큰씩 결과를 생성하는 decode 단계가 이어집니다. 이 두 단계는 모두 GPU를 사용하지만, 필요한 자원 특성과 병목 지점이 서로 다릅니다.
prefill은 긴 입력 프롬프트를 한꺼번에 처리해야 하므로 순간적으로 많은 연산량과 메모리 대역폭을 요구합니다. 반면 decode는 이미 계산된 상태를 바탕으로 토큰을 순차적으로 생성하므로, 요청 하나가 오래 살아 있으면서 KV Cache를 지속적으로 점유하는 특성이 있습니다. 즉, 두 단계는 같은 LLM 추론에 속하지만 시스템에 가하는 부하의 성격이 다릅니다.
Disaggregated Prefill/Decode는 이 두 단계를 하나의 동일한 서버에서 모두 처리하지 않고, 서로 다른 역할의 인스턴스로 분리하는 방식입니다. 예를 들어 prefill에 최적화된 인스턴스가 먼저 프롬프트를 처리한 뒤, 그 결과를 decode에 최적화된 인스턴스로 넘겨 토큰 생성을 이어가도록 구성할 수 있습니다.
이렇게 분리하면 긴 프롬프트를 처리하는 요청이 decode 처리 자원을 과도하게 점유하는 문제를 줄일 수 있습니다. 결과적으로 시스템 전체의 GPU 활용률을 더 안정적으로 유지할 수 있고, 특히 대규모 입력과 장시간 스트리밍 응답이 섞여 있는 환경에서 성능과 처리량을 개선할 수 있습니다.
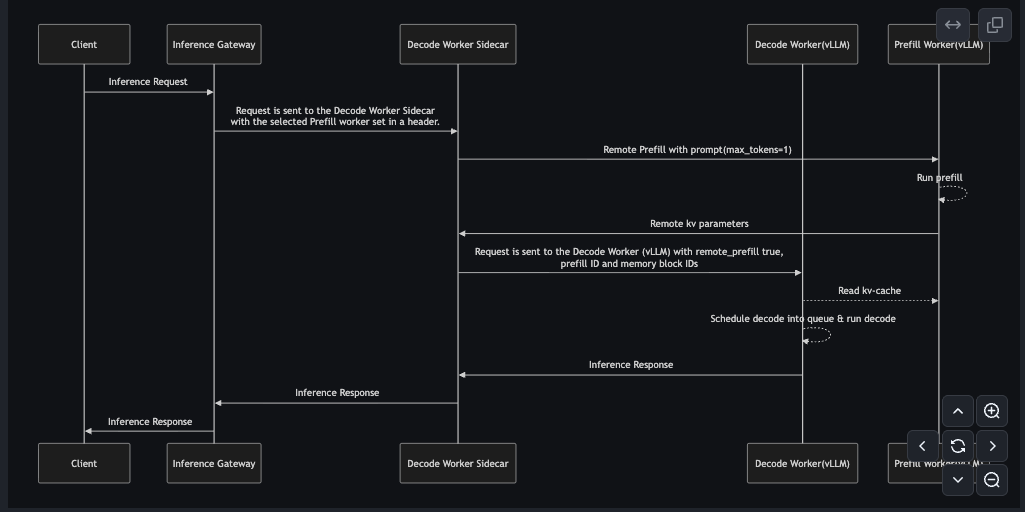
아래 시퀀스 다이어그램은 llm-d기반의 Disaggregation 구현 로직으로 Decode Worker Sidecar라는 중간 레이어가 오케스트레이션을 담당합니다.
 https://github.com/llm-d/llm-d-inference-scheduler/blob/main/docs/disagg_pd.md
https://github.com/llm-d/llm-d-inference-scheduler/blob/main/docs/disagg_pd.md
-
Inference Gateway → Decode Worker Sidecar
클라이언트 요청이 Inference Gateway에 도달하면, 게이트웨이는 이미 어떤 Prefill Worker를 사용할지 결정합니다. 선택된 Prefill Worker의 정보를 HTTP 헤더에 담아 요청을 Decode Worker Sidecar로 전달합니다.
-
Decode Worker Sidecar → Prefill Worker(vLLM)
Sidecar는 헤더에서 Prefill Worker 주소를 읽어, 해당 워커에게 Remote Prefill 요청을 보냅니다. 이때 Prefill Worker가 실제 토큰을 생성하지 않고 KV 캐시 생성만 수행하도록
max_tokens=1로 설정합니다. -
Prefill Worker → Decode Worker Sidecar
Prefill Worker는 Prefill을 마친 후 실제 토큰 대신 KV 캐시 메타데이터를 Sidecar에 반환합니다.
-
Decode Worker Sidecar → Decode Worker(vLLM)
Sidecar는 원본 요청에 KV 메타데이터(
remote_prefill)를 추가하여 Decode Worker에 전달합니다. -
Decode Worker → Prefill Worker (Read KV-Cache)
Decode Worker는
memory_block_ids를 사용해 Prefill Worker의 GPU 메모리에서 KV 캐시 블록을 직접 읽어온다. 전송은 NVLink/InfiniBand를 통해 수행되어 CPU를 거치지 않고 GPU-to-GPU로 전달됩니다. -
Decode Worker: Schedule & Run Decode
KV 캐시가 로컬 메모리에 적재되면, Decode Worker는 해당 시퀀스를 Continuous Batching 큐에 삽입하고 일반적인 Decode 단계를 수행합니다. 이후 생성된 토큰들은 Sidecar → Gateway → Client 순서로 역방향으로 반환된다.
위 아키텍처에서 라우팅 결정은 Inference Gateway가 담당하며, Prefill Worker와 Decode Worker 모두 동일한 스코어링 원칙을 공유합니다.
Prefer longest prefix match/kv-cache utilization (depends on available scorers) and low load
Semantic Routing
앞에서 살펴본 Prefix-aware Routing이나 KV Cache-aware Routing은 주로 동일한 모델을 서빙하는 여러 Pod 중 어느 인스턴스를 선택할 것인가에 초점을 둡니다. 하지만 실제 서비스 환경에서는 한 단계 더 나아가, 이 요청을 어떤 모델이 처리하는 것이 가장 적절한가를 먼저 판단해야 하는 경우도 많습니다.
예를 들어 어떤 요청은 코딩 성능이 좋은 모델이 더 적합하고, 어떤 요청은 수학 추론에 강한 모델이 더 나은 결과를 낼 수 있습니다. 또 단순한 질의는 더 저렴한 소형 모델로 처리하고, 복잡한 질의만 대형 모델로 보내는 것이 비용 측면에서 유리할 수도 있습니다.
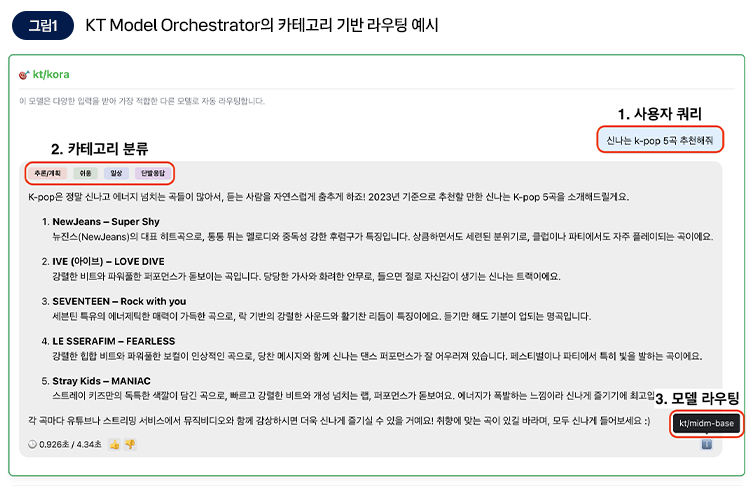 https://enterprise.kt.com/bt/dxstory/3691.do
https://enterprise.kt.com/bt/dxstory/3691.do
Semantic Routing은 요청의 의미나 성격을 분석해, 가장 적합한 모델 또는 백엔드로 보내는 전략입니다. 즉 사용자 쿼리에 따라 가장 적합한 모델을 자동으로 선택하며, 유사한 수준의 응답 품질을 낼 수 있는 여러 모델 중에서는 가장 저렴한 모델을 선택하여 비용 효율성을 극대화합니다.
vLLM-SR
이와 관련해 vLLM 생태계에서는 Mixture-of-Models(MoM) 시스템을 위한 intelligent semantic router로 vLLM Semantic Router(vLLM-SR)를 함께 살펴볼 수 있습니다.
이 구조에서 Semantic Router는 OpenAI 호환 요청을 분석한 뒤 가장 적합한 backend model로 보내고, Production Stack은 그 아래에서 실제 인프라 라우팅과 자원 효율 최적화를 담당합니다
vLLM-SR은 Envoy External Processor(ExtProc)로 동작합니다. 즉, Envoy가 요청 처리 도중 ext-proc 프로토콜을 통해 Semantic Router에 질의하고, Semantic Router는 요청 내용을 분석한 뒤 어떤 모델 또는 backend로 보낼지 결정합니다. 배포 형태에 따라 별도 서비스 또는 독립 컴포넌트로 구성될 수 있으며, 핵심은 Envoy와 ext-proc로 연동된다는 점입니다.
vLLM Semantic Router에서 확인할 수 있습니다.
Envoy Gateway는 기본 게이트웨이와 트래픽 처리 엔진을 제공하고, Envoy AI Gateway는 그 위에서 AI provider 통합, 인증, rate limiting, failover 같은 AI 특화 기능을 담당하게 됩니다. vLLM Semantic Router는 이 구조 안에서 요청의 의미를 바탕으로 어떤 모델 또는 backend가 적절한지 판단하는 semantic routing 계층이며, 실제 텍스트 생성은 최종 backend model이 수행합니다.
따라서 vLLM-SR은 EPP처럼 pool 내부 endpoint를 고르는 컴포넌트라기보다, 그보다 앞단에서 모델 선택을 수행하는 상위 라우팅 계층으로 이해하는 편이 적절합니다.
Conclusion
기존의 Kubernetes Ingress나 일반적인 L7 로드밸런서는 웹 트래픽을 처리하는 데에는 충분했지만, LLM 추론 트래픽을 다루기에는 한계가 분명합니다. LLM 요청은 입력 길이, 스트리밍 응답, KV Cache 상태, LoRA Adapter 가용성, 모델별 특성 등에 따라 비용과 지연 시간이 크게 달라지기 때문에, 단순한 Round-Robin 방식만으로는 안정적인 성능과 효율을 보장하기 어렵습니다.
이러한 배경에서 Gateway API Inference Extension은 Kubernetes Gateway API 위에 inference-aware routing 계층을 추가하려는 시도라고 볼 수 있습니다. InferencePool, EPP, ext-proc 같은 개념을 통해 게이트웨이는 더 이상 단순히 요청을 전달하는 프록시에 머물지 않고, 각 모델 서버의 상태를 반영해 더 적절한 endpoint를 선택할 수 있게 됩니다.
Kubernetes 환경에서의 LLM 서빙은 더 이상 단순히 모델만 띄우는 것이 아니라 어떤 게이트웨이를 사용할지, 어떤 라우팅 전략을 적용할지, 그리고 모델 선택과 인프라 효율화를 어떤 계층에서 나눠 담당할지를 함께 설계해야 합니다.
Comments