15 min to read
Kubernetes Bootstrapping and Upgrade with kubeadm — 1
Cloudnet@ K8S Deploy — Week3
Worker Node
Worker Node는 실제 애플리케이션 워크로드가 실행되는 계층으로, Control Plane과 동일한 런타임 환경과 커널 설정을 요구합니다. 따라서 Worker Node의 환경 구성은 Control Plane과 기술적으로 동일한 전제 조건을 충족해야 하며, 이는 클러스터 전체의 일관성을 보장합니다.
실습 환경에서 k8s-w1과 k8s-w2 두 개의 Worker Node를 구성합니다. 아래의 모든 설정 작업은 각 Worker Node에 SSH로 접속하여 개별적으로 수행해야 합니다.
ssh k8s-w1
ssh k8s-w2
Prerequisites
Real Time Clock을 UTC 기준으로 설정하고, 시스템 타임존을 한국 표준시로 구성합니다.
timedatectl set-local-rtc 0
timedatectl set-timezone Asia/Seoul
SELinux를 Permissive 모드로 전환하여 Kubernetes 컴포넌트가 파일 시스템에 접근할 수 있도록 허용합니다.
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
firewalld를 비활성화하고 Swap을 완전히 제거합니다.
systemctl disable --now firewalld
swapoff -a
sed -i '/swap/d' /etc/fstab
컨테이너 네트워킹에 필요한 커널 모듈을 로드합니다.
modprobe overlay
modprobe br_netfilter
cat <<EOF | tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
브릿지 트래픽이 IPTables를 거치도록 커널 파라미터를 설정합니다.
cat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system >/dev/null 2>&1
클러스터 노드 간 로컬 도메인 해석을 위한 hosts 파일을 구성합니다.
sed -i '/^127\.0\.\(1\|2\)\.1/d' /etc/hosts
cat << EOF >> /etc/hosts
192.168.10.100 k8s-ctr
192.168.10.101 k8s-w1
192.168.10.102 k8s-w2
EOF
Container Runtime Interface 설치는 Control Plane과 동일한 버전인 containerd v2.1.5를 사용합니다. Worker Node에서 실행되는 kubelet은 이를 통해 Pod의 생명주기를 관리하며, SystemdCgroup 드라이버 설정을 통해 systemd와의 자원 관리 충돌을 방지합니다.
Docker 저장소를 추가하고 containerd를 설치합니다.
dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
dnf install -y containerd.io-2.1.5-1.el10
기본 설정 파일을 생성하고 SystemdCgroup을 활성화합니다.
containerd config default | tee /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
systemctl daemon-reload
systemctl enable --now containerd
Kubernetes 바이너리 설치는 v1.32.11 버전으로 통일하여 Control Plane과의 API 호환성을 유지합니다. 저장소 설정에서 exclude 필드를 사용하여 의도하지 않은 자동 업그레이드를 방지합니다.
Kubernetes 저장소를 추가합니다.
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
kubeadm, kubelet, kubectl을 설치하고 kubelet 서비스를 활성화합니다.
dnf install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet
crictl이 containerd 소켓을 사용하도록 설정합니다.
cat << EOF > /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
EOF
현재 단계에서 kubelet이 실패 상태로 표시되는 것은 정상입니다. kubelet은 /var/lib/kubelet/config.yaml 설정 파일과 API Server 연결 정보가 필요하며, 이는 kubeadm join 과정에서 생성됩니다.
Join
Worker Node가 클러스터에 참여하는 과정은 Discovery와 TLS Bootstrap이라는 두 단계로 구성됩니다.
- Discovery 단계: Worker Node가 Control Plane의 API Server를 신뢰할 수 있는지 검증합니다.
- TLS Bootstrap 단계: API Server가 Worker Node를 신뢰할 수 있도록 인증서를 발급받습니다.
이 메커니즘은 Bootstrap Token을 활용하여 초기 인증을 수행하고, 이후 정식 클라이언트 인증서로 전환함으로써 보안을 유지하면서도 자동화된 노드 등록을 가능하게 합니다.
kubeadm init과 마찬가지로 join 명령도 내부적으로 여러 Phase를 순차적으로 실행합니다.
- Preflight checks를 통해 시스템 요구사항을 검증합니다.
- Discovery 단계에서 클러스터의 CA를 확인합니다.
- TLS Bootstrap 과정을 통해 노드 전용 인증서를 발급받습니다.
- kubelet을 시작하여 클러스터에 노드를 등록합니다.
Control Plane은 이 과정에 필요한 Bootstrap Token을 미리 생성하고, system:bootstrappers:kubeadm:default-node-token 그룹에 권한을 부여하여 join을 지원합니다.
Discovery
kubeadm join은 kube-public 네임스페이스의 cluster-info ConfigMap을 인증 없이 조회하여 API Server의 엔드포인트와 CA 인증서 정보를 획득합니다. 이 ConfigMap은 kubeadm init 과정에서 생성되었으며, system:unauthenticated 그룹에게도 읽기 권한이 부여되어 있기 때문입니다.
Worker Node의 네트워크 인터페이스 IP 주소를 확인하고 kubeadm join 설정 파일을 작성합니다.
NODEIP=$(ip -4 addr show enp18s0 | grep -oP '(?<=inet\s)\d+(\.\d+){3}')
echo $NODEIP
cat << EOF > kubeadm-join.yaml
apiVersion: kubeadm.k8s.io/v1beta4
kind: JoinConfiguration
discovery:
bootstrapToken:
token: "123456.1234567890123456"
apiServerEndpoint: "192.168.10.100:6443"
unsafeSkipCAVerification: true
nodeRegistration:
criSocket: "unix:///run/containerd/containerd.sock"
kubeletExtraArgs:
- name: node-ip
value: "$NODEIP"
EOF
Bootstrap Token은 kubeadm init 실행 시 자동으로 생성되거나 사용자가 명시적으로 지정할 수 있습니다. 이전 실습에서 kubeadm-init.yaml의 bootstrapTokens 섹션에서 ttl을 0s로 설정하여 만료되지 않는 토큰을 생성했습니다. 이 토큰은 쿠버네티스 내부의 Secret 객체로 저장됩니다.
 k get secret -n kube-system
k get secret -n kube-system
이를 자세히 살펴보면 data.auth-extra-groups 필드가 인코딩되어 있습니다.
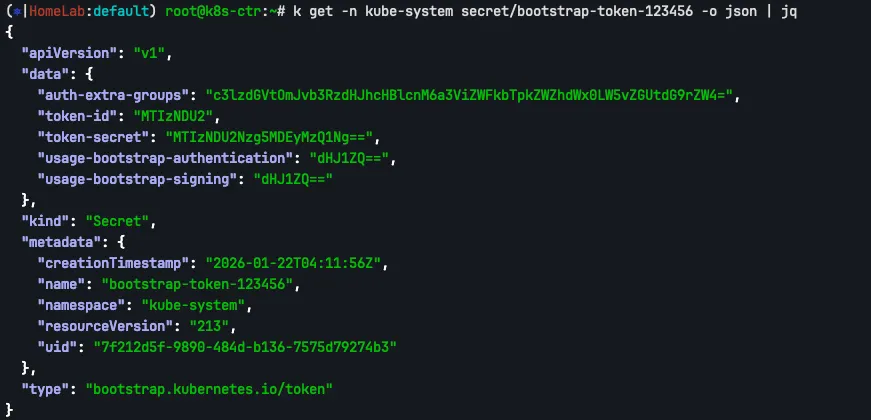 k get -n kube-system secret/bootstrap-token-123456 -o json | jq
k get -n kube-system secret/bootstrap-token-123456 -o json | jq
이를 디코딩해보면 system:bootstrappers:kubeadm:default-node-token이라는 그룹명이 나타납니다.
kubeadm:kubelet-bootstrap이라는 이름의 ClusterRoleBinding은 위 그룹을 system:node-bootstrapper라는 ClusterRole에 연결합니다.
해당 ClusterRole의 권한을 조회해 보면, 노드가 자신의 인증서를 발급받기 위해 반드시 필요한 CSR을 생성하고 조회할 수 있는 권한이 부여되어 있음을 확인할 수 있습니다.
 kubectl describe clusterrole system:node-bootstrapper
kubectl describe clusterrole system:node-bootstrapper
CA 검증이 완료되면 Worker Node는 Bootstrap Token을 인증 수단으로 제시하여 API Server에 접근합니다. 이 토큰은 제한된 권한을 가진 임시 자격 증명으로, Certificate Signing Request를 생성할 수 있는 권한만 부여됩니다. Worker Node는 자체적으로 개인키를 생성한 후, 이 개인키에 대응하는 인증서를 서명해달라는 CSR을 API Server에 제출합니다.
Control Plane의 Certificate 발급 컨트롤러는 이 CSR이 유효한 Bootstrap Token을 통해 제출되었는지 확인하고, kubeadm:node-autoapprove-bootstrap ClusterRoleBinding에 의해 자동으로 승인됩니다.
제출 후, 승인된 CSR에서의 SAN과 Organization 등을 확인할 수 있습니다.
 kubectl describe clusterrole system:node-bootstrapper
kubectl describe clusterrole system:node-bootstrapper
이어서 kubeadm join 명령을 실행합니다.
kubeadm join --config="kubeadm-join.yaml"
 kubectl get nodes -o wide
kubectl get nodes -o wide
각 노드에는 개별 Pod CIDR 블록이 할당되며, Flannel CNI가 이 정보를 기반으로 VXLAN 터널을 구성합니다.
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.podCIDR}{"\n"}{end}'
VXLAN 오버레이 네트워크가 정상적으로 동작하는지 Worker Node의 Flannel 인터페이스 IP로 ping을 시도합니다.
# k8s-ctr 에서 10.244.1.0 IP로 통신 가능(vxlan overlay 사용) 확인
ping -c 1 10.244.1.0
Monitoring
클러스터의 리소스 사용량과 성능 지표를 수집하는 것은 운영 관점에서 필수적입니다. Kubernetes는 기본적으로 메트릭 수집 시스템을 포함하지 않으며, 사용자가 원하는 모니터링 솔루션을 선택하여 배포해야 합니다.
메트릭 수집은 크게 두 가지 계층으로 나뉩니다.
- Metrics Server: 실시간 리소스 메트릭 제공으로,
kubectl top명령과 Horizontal Pod Autoscaler가 이를 사용합니다. - Prometheus: 시계열 데이터베이스를 통한 장기 메트릭 보관 및 시각화입니다.
이 실습에서 두 시스템을 모두 구성하여 클러스터의 리소스 사용 패턴을 추적하고, Grafana를 통해 시각화합니다.
Metrics Server
Metrics Server는 kubelet으로부터 리소스 메트릭을 수집하여 Kubernetes API Server에 제공하는 경량 컴포넌트입니다.
kubelet의 Summary API를 주기적으로 조회하여 노드와 Pod의 CPU 및 메모리 사용량을 집계하며, 이 데이터는 메모리에만 저장되므로 장기 보관이나 히스토리 조회는 지원하지 않습니다.
Helm 저장소를 추가하고 Metrics Server를 설치합니다.
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm upgrade --install metrics-server metrics-server/metrics-server \
--set 'args[0]=--kubelet-insecure-tls' -n kube-system
Metrics Server가 정상적으로 동작하는지 확인합니다. 메트릭 수집이 시작되기까지 약 15–30초가 소요됩니다.
kubectl top node
kubectl top pod -A --sort-by='cpu'
kubectl top pod -A --sort-by='memory'
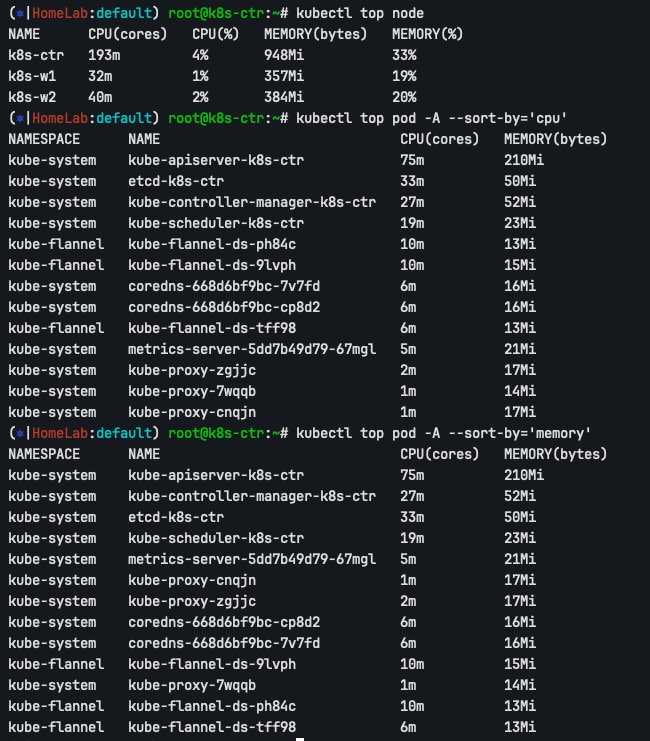 kubectl top node/pod
kubectl top node/pod
Prometheus Stack
kube-prometheus-stack은 Prometheus, Alertmanager, Grafana를 통합하여 제공하는 Helm Chart입니다. Prometheus는 시계열 메트릭을 수집하고 저장하며, Alertmanager는 알림 규칙을 처리하고, Grafana는 시각화 대시보드를 제공합니다. ServiceMonitor와 PrometheusRule 같은 Custom Resource를 사용하여 메트릭 수집 대상과 알림 규칙을 선언적으로 관리할 수 있습니다.
Prometheus 저장소를 추가합니다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
이후 설정 파일을 작성합니다. scrapeInterval과 evaluationInterval은 메트릭 수집 주기와 규칙 평가 주기를 설정하며, 값이 작을수록 더 정밀한 모니터링이 가능하지만 리소스 사용량이 증가합니다. NodePort로 서비스를 노출하여 클러스터 외부에서 접근할 수 있도록 구성합니다.
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "20s"
evaluationInterval: "20s"
externalLabels:
cluster: "myk8s-cluster"
service:
type: NodePort
nodePort: 30001
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
service:
type: NodePort
nodePort: 30002
alertmanager:
enabled: true
defaultRules:
create: true
kubeProxy:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
Helm Chart를 배포합니다.
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 80.13.3 -f monitor-values.yaml --create-namespace --namespace monitoring
배포된 리소스를 확인합니다.
helm list -n monitoring
kubectl get pod,svc,ingress,pvc -n monitoring
kubectl get prometheus,servicemonitors,alertmanagers -n monitoring
kubectl get crd | grep monitoring
Prometheus와 Grafana에 웹 브라우저로 접근하여 정상 동작을 확인합니다.
- Prometheus: http://192.168.10.100:30001
- Grafana: http://192.168.10.100:30002 (admin / prom-operator)
Grafana에서 Kubernetes 클러스터 대시보드를 추가합니다. Dashboard 메뉴에서 [New], [Import]를 선택하고 15661과 15757을 입력하여 Load한 후, 데이터소스로 Prometheus를 선택하고 Import를 클릭합니다.
 Dashboards
Dashboards
kube-prometheus-stack은 기본적으로 kubelet, kube-proxy, CoreDNS 같은 컴포넌트의 메트릭을 수집하도록 구성되어 있지만, Control Plane의 컴포넌트인 kube-controller-manager, kube-scheduler, etcd는 보안상의 이유로 localhost에만 메트릭 엔드포인트를 노출합니다.
이로 인해 Prometheus가 이들 컴포넌트의 메트릭을 수집할 수 없습니다.
 Down
Down
메트릭 엔드포인트를 모든 인터페이스에 바인딩하도록 설정을 변경하여 Prometheus가 메트릭을 수집할 수 있도록 구성해야 합니다. Static Pod manifest 파일을 수정하면 kubelet이 자동으로 변경을 감지하고 Pod을 재시작합니다.
# kube-controller-manager bind-address 127.0.0.1 => 0.0.0.0 변경
sed -i 's|--bind-address=127.0.0.1|--bind-address=0.0.0.0|g' /etc/kubernetes/manifests/kube-controller-manager.yaml
# kube-scheduler bind-address 127.0.0.1 => 0.0.0.0 변경
sed -i 's|--bind-address=127.0.0.1|--bind-address=0.0.0.0|g' /etc/kubernetes/manifests/kube-scheduler.yaml
# etcd metrics-url(http) 127.0.0.1 에 192.168.10.100 추가
sed -i 's|--listen-metrics-urls=http://127.0.0.1:2381|--listen-metrics-urls=http://127.0.0.1:2381,http://192.168.10.100:2381|g' /etc/kubernetes/manifests/etcd.yaml
변경 사항이 적용되면 Prometheus는 이들 컴포넌트로부터 메트릭을 수집하기 시작합니다. Grafana에서 etcd 관련 대시보드를 추가하여 etcd 클러스터의 성능과 상태를 모니터링할 수 있습니다.
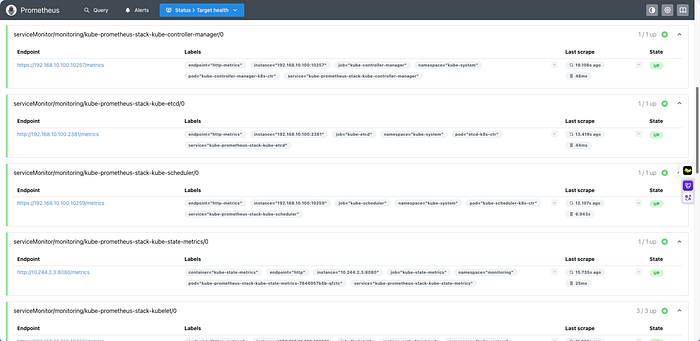 up
up
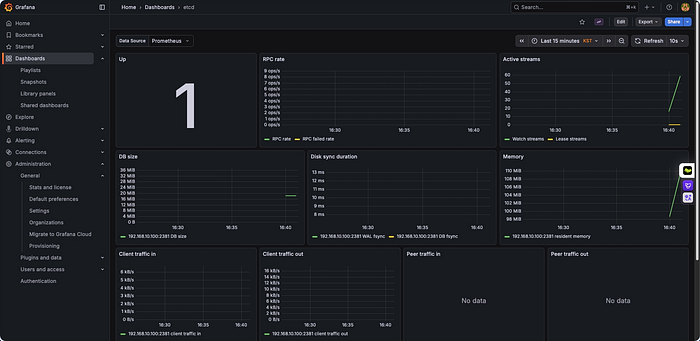 etcd dashboard
etcd dashboard
Certificate Monitoring
Kubernetes 클러스터는 컴포넌트 간 안전한 통신을 위해 TLS 인증서를 광범위하게 사용합니다. API Server, etcd, kubelet, Controller Manager, Scheduler 등 모든 컴포넌트는 상호 인증을 위해 개별 인증서를 보유하며, 이들 인증서는 제한된 유효 기간을 가집니다.
인증서가 만료되면 해당 컴포넌트는 통신할 수 없게 되고, 클러스터 전체가 작동을 멈출 수 있습니다. 따라서 인증서 만료 시점을 추적하고 갱신 시기를 파악하는 것은 클러스터 운영의 필수 요소입니다. kubeadm이 생성하는 인증서의 기본 유효 기간은 1년이므로, 주기적인 모니터링과 갱신 계획이 필요합니다.
인증서 만료 시점을 확인합니다.
kubeadm certs check-expiration
출력 결과에서 각 인증서의 만료 시점과 잔여 일수를 확인할 수 있습니다. CERTIFICATE AUTHORITY 섹션은 Root CA의 만료 시점을 보여주며, 기본적으로 10년의 유효 기간을 가집니다.
이러한 인증서들의 파일 구조는 /etc/kubernetes/pki 경로에는 API Server, Controller Manager, Scheduler의 인증서가 위치하며, /etc/kubernetes/pki/etcd 하위 경로에는 etcd 전용 인증서가 별도로 관리됩니다.
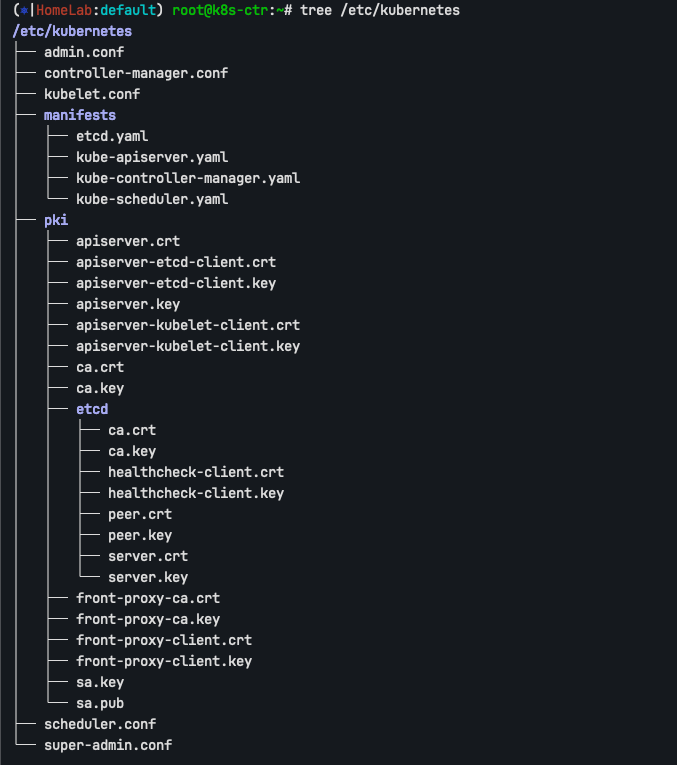 tree /etc/kubernetes
tree /etc/kubernetes
x509-certificate-exporter는 PEM 형식의 인증서 파일과 kubeconfig 파일을 주기적으로 읽어 만료 시점까지 남은 시간을 Prometheus 메트릭으로 노출합니다. DaemonSet으로 배포되어 각 노드의 파일 시스템에 직접 접근하며, Control Plane 노드와 Worker Node에서 각각 다른 인증서 경로를 모니터링하도록 구성할 수 있습니다. 이 exporter는 ServiceMonitor를 통해 Prometheus와 통합되며, PrometheusRule을 사용하여 만료 임박 시 알림을 발송하도록 설정할 수 있습니다.
Worker Node에 label을 설정하여 DaemonSet이 올바른 노드에 배포되도록 준비합니다.
kubectl label node k8s-w1 worker="true" --overwrite
kubectl label node k8s-w2 worker="true" --overwrite
kubectl get nodes -l worker=true
Helm values 파일을 작성합니다. 이 설정은 두 개의 DaemonSet을 배포하며, 하나는 Control Plane 노드의 인증서를 모니터링하고 다른 하나는 Worker Node의 인증서를 모니터링합니다.
cat << EOF > cert-export-values.yaml
hostPathsExporter:
hostPathVolumeType: Directory
daemonSets:
cp:
nodeSelector:
node-role.kubernetes.io/control-plane: ""
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Exists
watchFiles:
- /var/lib/kubelet/pki/kubelet-client-current.pem
- /var/lib/kubelet/pki/kubelet.crt
- /etc/kubernetes/pki/apiserver.crt
- /etc/kubernetes/pki/apiserver-etcd-client.crt
- /etc/kubernetes/pki/apiserver-kubelet-client.crt
- /etc/kubernetes/pki/ca.crt
- /etc/kubernetes/pki/front-proxy-ca.crt
- /etc/kubernetes/pki/front-proxy-client.crt
- /etc/kubernetes/pki/etcd/ca.crt
- /etc/kubernetes/pki/etcd/healthcheck-client.crt
- /etc/kubernetes/pki/etcd/peer.crt
- /etc/kubernetes/pki/etcd/server.crt
watchKubeconfFiles:
- /etc/kubernetes/admin.conf
- /etc/kubernetes/controller-manager.conf
- /etc/kubernetes/scheduler.conf
nodes:
nodeSelector:
worker: "true"
watchFiles:
- /var/lib/kubelet/pki/kubelet-client-current.pem
- /etc/kubernetes/pki/ca.crt
prometheusServiceMonitor:
create: true
scrapeInterval: 15s
scrapeTimeout: 10s
extraLabels:
release: kube-prometheus-stack
prometheusRules:
create: true
warningDaysLeft: 28
criticalDaysLeft: 14
extraLabels:
release: kube-prometheus-stack
grafana:
createDashboard: true
secretsExporter:
enabled: false
EOF
Helm Chart를 배포합니다.
helm repo add enix https://charts.enix.io
helm install x509-certificate-exporter enix/x509-certificate-exporter \
-n monitoring --values cert-export-values.yaml
배포된 리소스를 확인할 수 있습니다. Control Plane 노드용 DaemonSet과 Worker Node용 DaemonSet이 각각 배포되며, 각 Pod은 해당 노드의 인증서 파일을 읽어 메트릭을 생성합니다.
 kubectl get ds -n monitoring -l app.kubernetes.io/instance=x509-certificate-exporter
kubectl get ds -n monitoring -l app.kubernetes.io/instance=x509-certificate-exporter
Grafana 대시보드가 자동으로 추가되었는지 확인합니다. kube-prometheus-stack의 Grafana는 sidecar 컨테이너를 통해 ConfigMap에서 대시보드를 자동으로 로드합니다.
kubectl get cm -n monitoring x509-certificate-exporter-dashboard
x509-certificate-exporter는 ServiceMonitor를 통해 Prometheus와 통합되며, PrometheusRule을 통해 알림 규칙을 정의합니다. Prometheus는 이 ServiceMonitor를 감지하여 자동으로 메트릭 수집 대상에 추가하고, 정의된 알림 규칙을 평가합니다. 인증서 만료까지 28일 미만일 때 Warning 알림이, 14일 미만일 때 Critical 알림이 발생하도록 구성되어 있습니다.
Service와 Endpoints를 확인합니다.
kubectl get svc,ep -n monitoring x509-certificate-exporter
 Endpoints
Endpoints
Endpoints에 표시된 IP 주소는 각 DaemonSet Pod의 IP이며, Prometheus는 이 엔드포인트에서 메트릭을 수집합니다.
메트릭이 정상적으로 노출되는지 확인합니다.
CONTROL_PLANE_POD_IP=$(kubectl get pod -n monitoring -o wide | grep x509-certificate-exporter-cp | awk '{print $6}')
curl -s $CONTROL_PLANE_POD_IP:9793/metrics | grep '^x509' | head -n 3
Prometheus에서 x509-certificate-exporter가 수집 대상으로 추가된 것을 볼 수 있습니다. Alerts 메뉴에서 인증서 만료 관련 알림 규칙이 로드되었는지 확인할 수 있습니다.
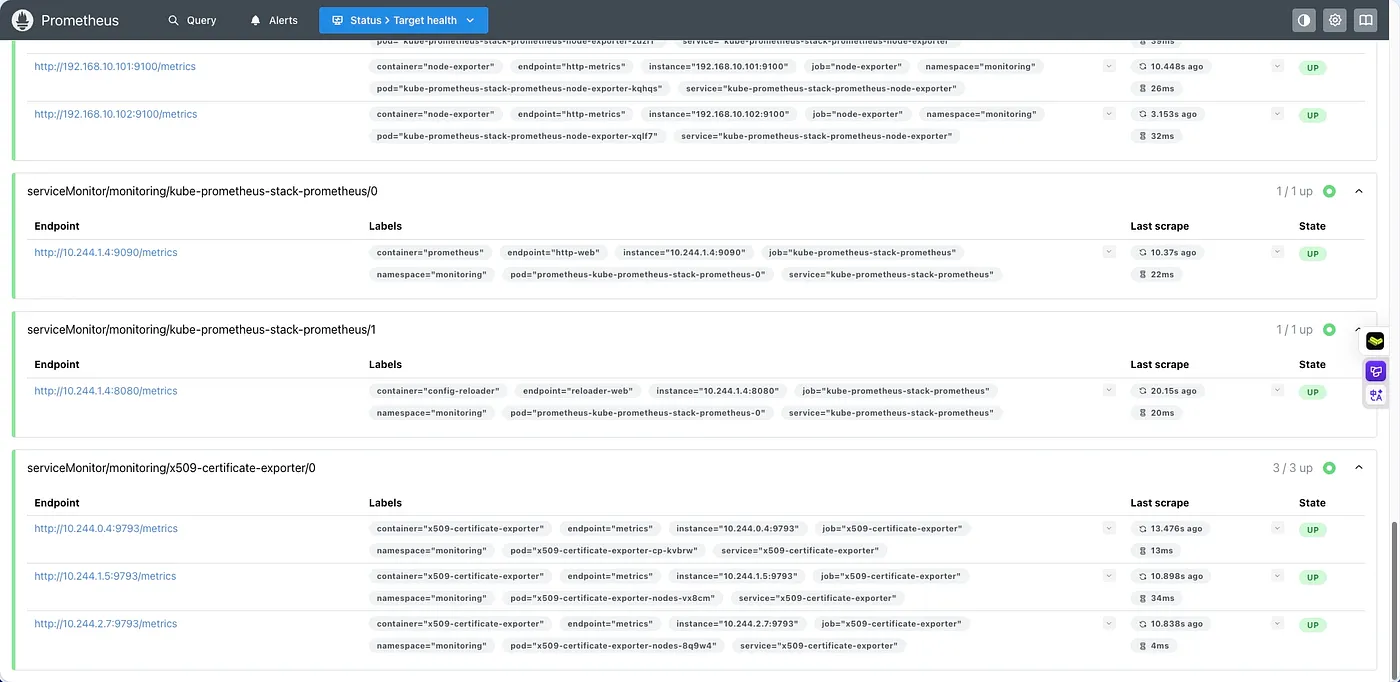 Targets
Targets
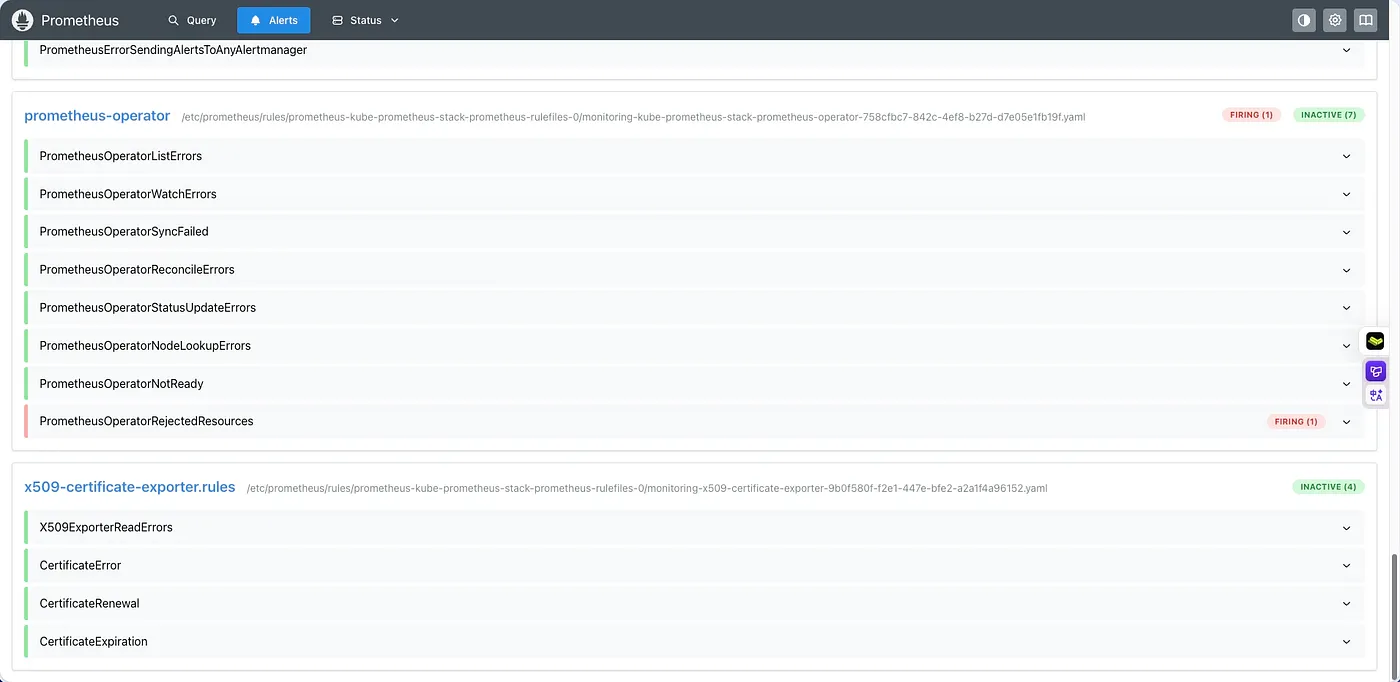 Alerts
Alerts
Grafana에서 x509-certificate-exporter 대시보드를 열어 인증서 만료 현황을 시각화합니다. Overview 섹션에서 전체 인증서의 만료 요약 정보를 제공하며, Expiration 섹션에서 각 인증서의 잔여 일수를 그래프로 표시합니다. Charts 섹션에서 발급자별, 인스턴스별 인증서 분포를 확인할 수 있습니다.
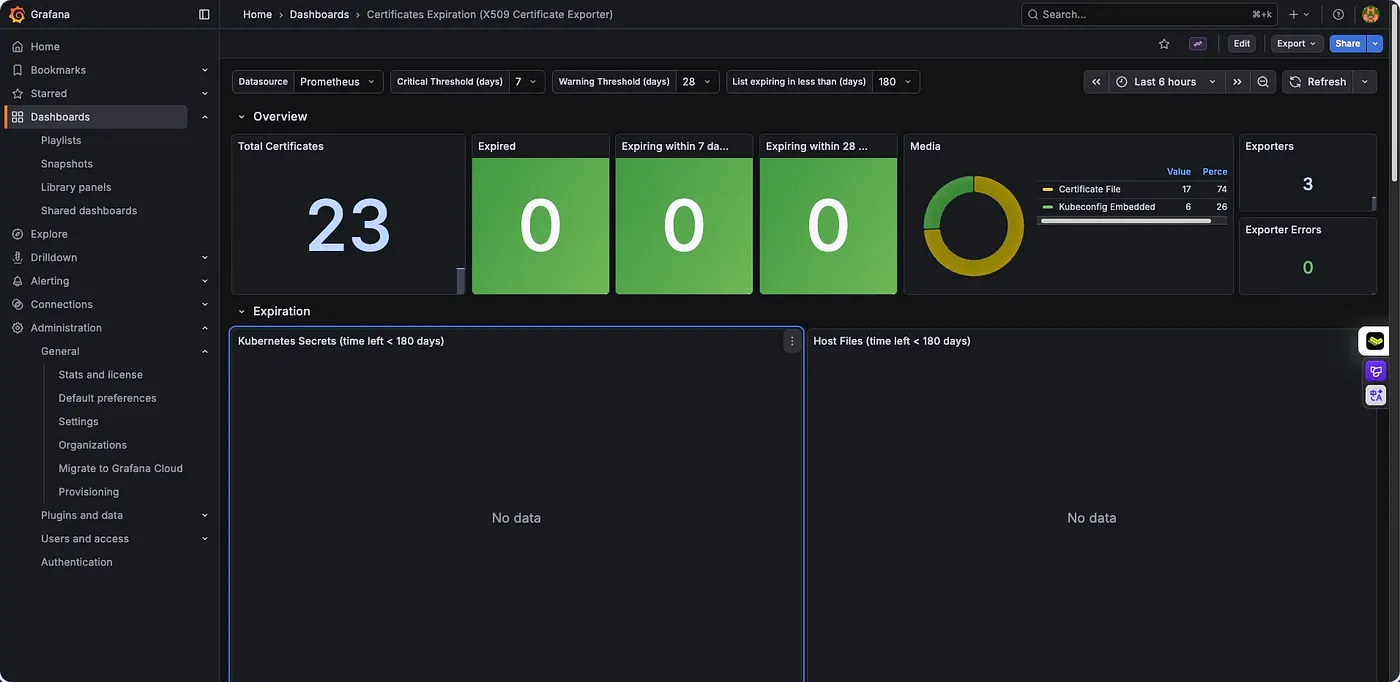 Dashboards
Dashboards
Certificate Renewal
클러스터의 컴포넌트 인증서는 제한된 유효 기간을 가지며, kubeadm이 생성하는 인증서의 기본 유효 기간은 1년입니다. Kubeadm은 인증서 갱신을 위한 명령을 제공하며, 이를 통해 CA는 유지한 채 개별 컴포넌트 인증서만 재서명할 수 있습니다.
kubeadm certs renew 명령은 기존 CA를 사용하여 개별 컴포넌트 인증서를 재서명합니다. 이 과정에서 기존 인증서 파일은 삭제되고 새로운 인증서가 생성되며, kubeconfig 파일도 새로운 인증서를 참조하도록 업데이트됩니다.
인증서 갱신 후에는 Control Plane의 Static Pod들을 재시작해야 합니다. Kubernetes는 동적 인증서 갱신을 지원하지 않으므로, 컴포넌트들이 새로운 인증서를 로드하려면 프로세스 재시작이 요구됩니다.
이에 따라 API Server가 재시작되는 동안 API 요청이 수초에서 수십 초간 중단되며, kubectl 명령이 일시적으로 실패합니다. 그러나 Worker Node에서 실행 중인 워크로드는 영향을 받지 않습니다. kubelet의 클라이언트 인증서는 자동 갱신되므로, Worker Node에서 추가 작업이 필요하지 않습니다. 단일 노드 etcd를 사용하는 경우 etcd 재시작으로 인해 API Server가 일시적으로 etcd에 접근할 수 없게 되지만, 다중 노드 etcd를 사용하는 경우 순차 갱신을 통해 일관성을 유지할 수 있습니다.
기존 인증서와 설정 파일을 백업합니다.
cp -r /etc/kubernetes/pki /etc/kubernetes/pki.backup.$(date +%F)
ls -l /etc/kubernetes/pki.backup.$(date +%F)
mkdir /etc/kubernetes/backup-conf.$(date +%F)
cp /etc/kubernetes/*.conf /etc/kubernetes/backup-conf.$(date +%F)
ls -l /etc/kubernetes/backup-conf.$(date +%F)
모든 인증서를 갱신합니다.
kubeadm certs renew all
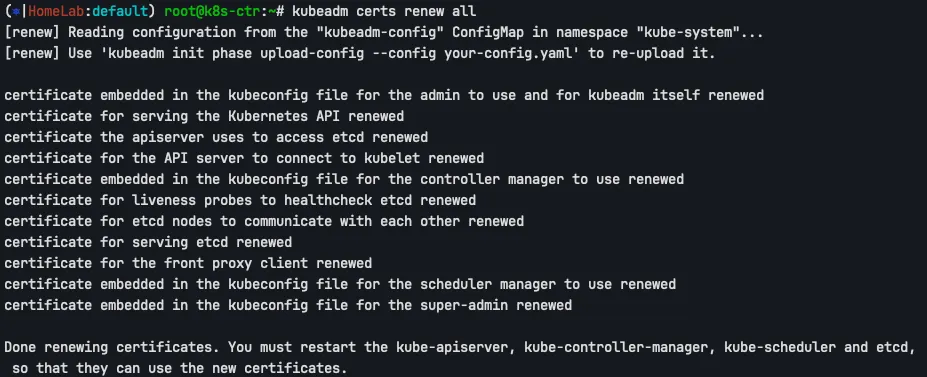 Renewal
Renewal
출력 메시지에서 각 인증서가 갱신되었음을 확인할 수 있으며, 마지막에 Static Pod 재시작이 필요하다는 안내가 표시됩니다.
갱신 후 만료 시점을 다시 확인합니다. 모든 컴포넌트 인증서의 만료 시점이 갱신 시점으로부터 1년 후로 변경되었으며, CA의 만료 시점은 변경되지 않은 것을 확인할 수 있습니다.
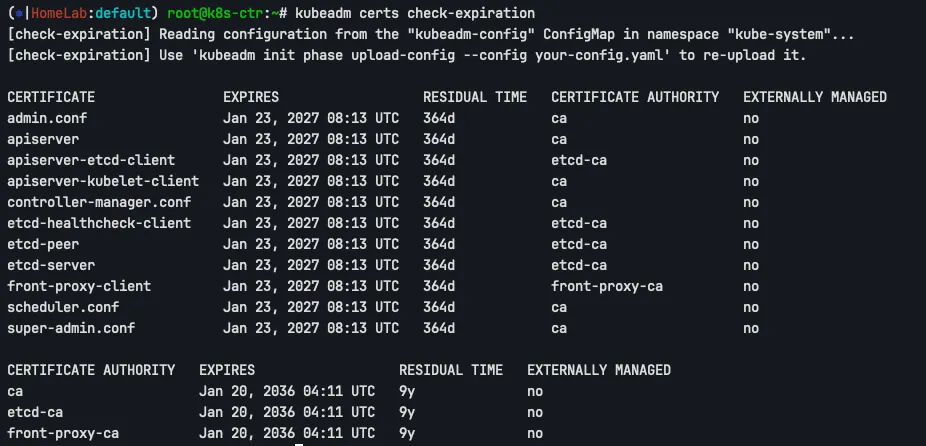 kubeadm certs check-expiration
kubeadm certs check-expiration
새로 생성된 인증서 파일을 확인합니다.
ls -lt /etc/kubernetes/pki/
ls -lt /etc/kubernetes/pki/etcd/
ca.crt, ca.key, sa.key, sa.pub, front-proxy-ca.crt, front-proxy-ca.key 파일은 원래 생성 시점을 유지하며, 나머지 인증서 파일들은 갱신 시점에 새로 생성되었습니다.
kubeconfig 역시 kubelet.conf를 제외하고 모두 업데이트되었음을 확인할 수 있습니다.
 ls -lt /etc/kubernetes/*.conf
ls -lt /etc/kubernetes/*.conf
백업된 admin.conf와 새로 생성된 admin.conf를 비교합니다.
vi -d /etc/kubernetes/backup-conf.$(date +%F)/admin.conf /etc/kubernetes/admin.conf
인증서 갱신 후 Control Plane 컴포넌트들이 새로운 인증서를 로드하려면 Static Pod을 재시작해야 합니다. kubelet은 /etc/kubernetes/manifests 경로를 주기적으로 스캔하며, 이 경로에서 manifest 파일이 제거되면 해당 Pod을 종료하고, 파일이 다시 나타나면 Pod을 재생성합니다. 이 메커니즘을 활용하여 Static Pod을 재시작할 수 있습니다.
Static Pod manifest 파일을 백업합니다.
cp -r /etc/kubernetes/manifests /etc/kubernetes/manifests.backup.$(date +%F)
ls -l /etc/kubernetes/manifests.backup.$(date +%F)
watch -d crictl ps로 Static Pod 상태를 모니터링하면서 manifest 파일을 제거하여 Static Pod을 종료합니다.
rm -rf /etc/kubernetes/manifests/*.yaml
백업한 manifest 파일을 복원합니다.
cp /etc/kubernetes/manifests.backup.$(date +%F)/*.yaml /etc/kubernetes/manifests
tree /etc/kubernetes/manifests
kubelet이 manifest 파일을 감지하여 Pod을 재생성합니다. 약 20초 후에 모든 컨테이너가 Running 상태로 전환됩니다.
admin.conf를 사용자의 kubeconfig로 복사합니다.
yes | cp /etc/kubernetes/admin.conf ~/.kube/config
chown $(id -u):$(id -g) ~/.kube/config
기존 ~/.kube/config 파일은 이전 인증서를 참조하므로, 새로운 admin.conf로 교체해야 kubectl 명령이 정상적으로 동작합니다.
Grafana의 Kubernetes 클러스터 대시보드를 확인하면, Static Pod 재시작 시점에 메모리 사용량과 CPU 메트릭 수집이 일시적으로 중단된 것을 볼 수 있습니다. 이는 API Server가 종료되어 Prometheus가 kubelet 및 기타 컴포넌트로부터 메트릭을 수집할 수 없었기 때문입니다.
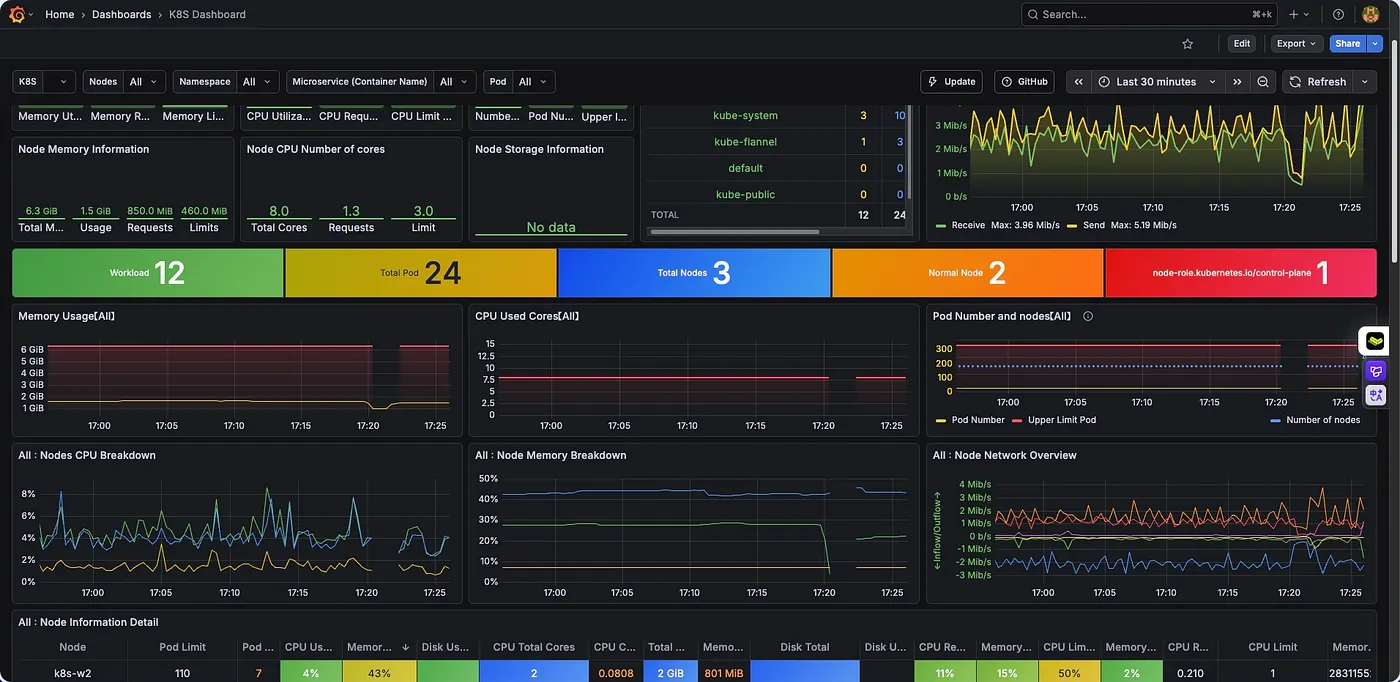 breakdown
breakdown
Comments