42 min to read
Bootstrap Kubernetes the hard way
Cloudnet@ K8S Deploy — Week1
아티클에서는 MacOS(Apple Silicon)를 기준으로 진행하였으며, Virtual Box가 아닌 최근 개인 사용자에게 무료로 제공되는 VM Ware Fusion와 Vagrant로 실습을 진행하였습니다.
Abstract
Kelsey Hightower의 Kubernetes the Hard Way는 자동화된 스크립트나 도구 없이, Kubernetes 클러스터를 직접 손으로 구축하며 내부 동작을 학습할 수 있도록 만든 대표적인 튜토리얼입니다. 이번 글에서는 VMware Fusion Pro와 Vagrant를 활용해 로컬 환경에서 실습하는 과정을 정리합니다.
Prerequisites
실습 환경 구성을 위해서는 VMware Fusion Pro (25H2)와 Vagrant 설치가 필요합니다.
VMware Fusion Pro는 macOS에서 가상 머신을 실행할 수 있는 강력한 도구입니다. 2024년부터 개인 사용자에게 무료로 제공되며, 공식 홈페이지에서 다운로드할 수 있습니다.
Vagrant는 VM 환경을 코드로 정의하고 관리할 수 있도록 돕는 도구입니다. 실습에서는 VM 인스턴스를 손쉽게 생성하고 관리하기 위해 사용합니다.
macOS 환경에서 Vagrant는 Homebrew를 통해 간단히 설치할 수 있습니다.
brew install --cask vagrant
vagrant version
앞서 VMware Fusion Pro와 Vagrant를 설치했다면, 이제 Vagrant가 VMware를 Hypervisor로 활용할 수 있도록 Vagrant VMware Provider를 추가해야 합니다. Vagrant는 직접 VM을 만들지 않고, Hypervisor를 추상화하는 Provider를 통해 VM을 생성하고 관리합니다.
Installation — VMware Provider 를 참고하여 Provider를 설치하도록 합니다.
Vagrant VMware Provider는 두 단계의 설치 과정이 필요합니다.
- Vagrant VMware Utility: 권한이 필요한 작업(네트워크 설정 등)을 처리하는 시스템 서비스
- Vagrant Plugin: Vagrant와 VMware 간의 실제 통신 담당하는 플러그인
아래의 명령어를 통해 쉽게 설치할 수 있습니다.
# Utility Installation
brew install --cask vagrant-vmware-utility
# Plugin Installation
vagrant plugin install vagrant-vmware-desktop
Architecture
구현하고자 하는 실습의 구성도는 아래와 같습니다.
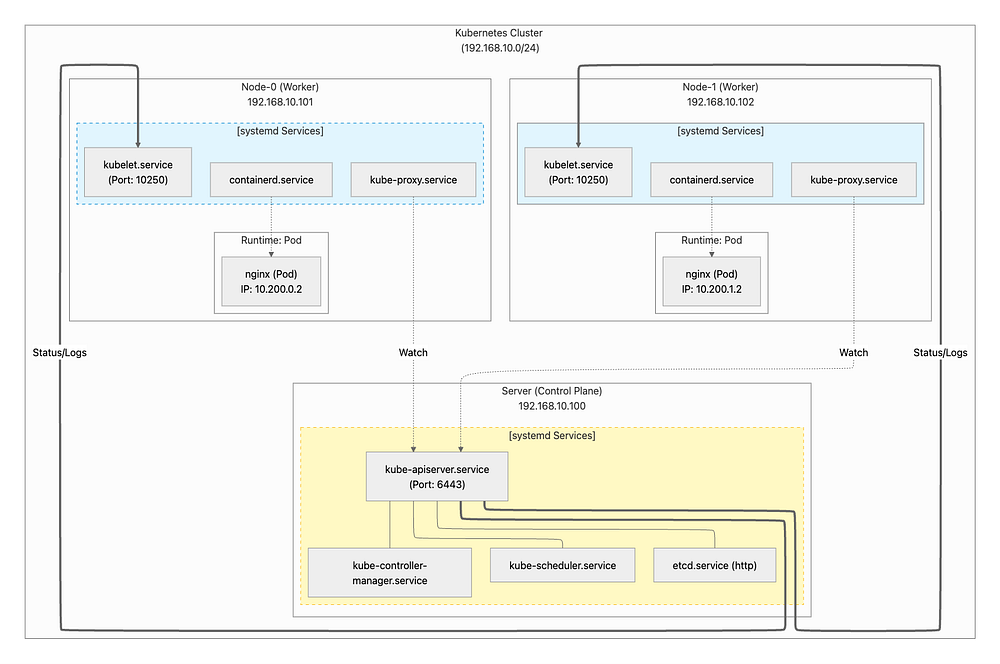 Architecture
Architecture
Components
Jumpbox는 Bastion Host로 클러스터 외부에서 클러스터를 관리하고 API Server(6443)으로 명령을 전달합니다.
Server는 Control Plane으로 etcd, kube-apiserver, kube-controller-manager, kube-scheduler등이 구성요소입니다.
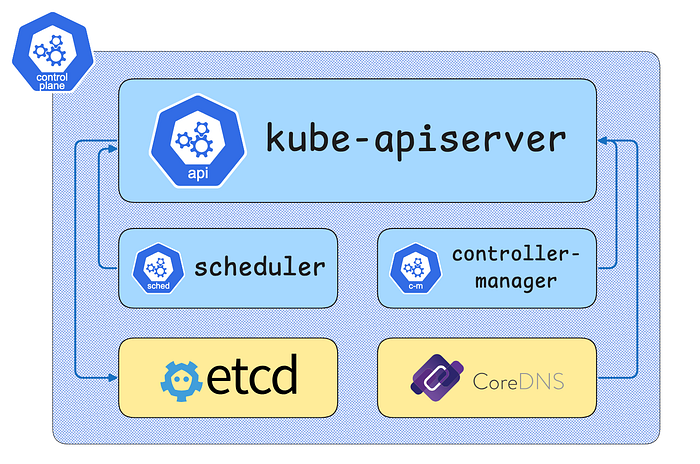 Control Plane | Kubernetes the Hard Way Playground | iximiuz Labs
Control Plane | Kubernetes the Hard Way Playground | iximiuz Labs
Node-0, Node-1은 실제 애플리케이션 컨테이너가 실행되는 Worker Node로 kubelet, containerd, runc, kube-proxy, CNI plugins등이 구성요소입니다.
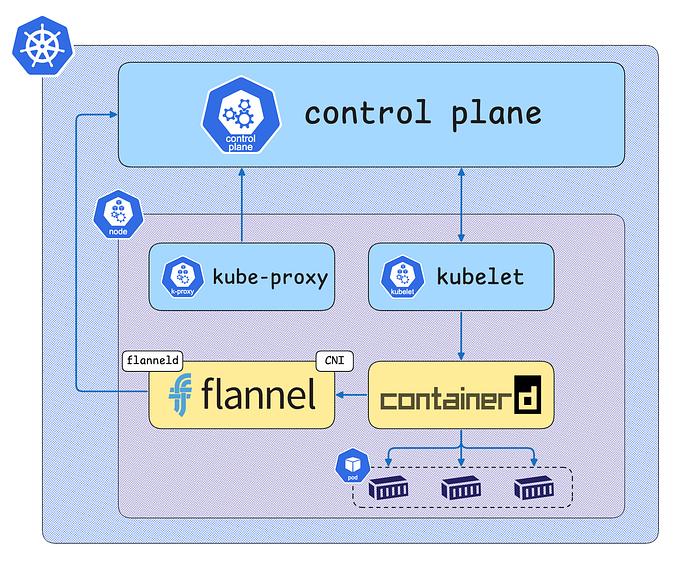 Worker Node | Kubernetes the Hard Way Playground | iximiuz Labs
Worker Node | Kubernetes the Hard Way Playground | iximiuz Labs
Set Up The Jumpbox
# Working Directory
mkdir k8s-hardway
cd k8s-hardway
# Download init_cfg.sh
curl -O https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/k8s-hardway/init_cfg.sh
가상 머신이 부팅된 직후 실행되는 init_cfg.sh는 쿠버네티스가 구동되기 위한 환경을 조성합니다. 필수 패키지 설치와 호스트 파일 구성등이 포함되어 있습니다.
Vagrantfile은 아래와 같이 작성합니다.
# Base Image : https://portal.cloud.hashicorp.com/vagrant/discover/bento/debian-12
BOX_IMAGE = "bento/debian-12"
BOX_VERSION = "202510.26.0"
Vagrant.configure("2") do |config|
# jumpbox
config.vm.define "jumpbox" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "vmware_desktop" do |v|
v.vmx["displayName"] = "jumpbox"
v.vmx["numvcpus"] = "2"
v.vmx["memsize"] = "1536"
v.linked_clone = true
v.vmx["ethernet0.pcislotnumber"] = "160"
end
subconfig.vm.host_name = "jumpbox"
subconfig.vm.network "private_network", ip: "192.168.10.10"
subconfig.vm.network "forwarded_port", guest: 22, host: 60010, auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh"
subconfig.vm.provision "shell", inline: <<-SHELL
# Add other VMs to /etc/hosts for easy communication
echo "# VM cluster hosts" >> /etc/hosts
# IPs will be filled after VMs are up
SHELL
end
# server
config.vm.define "server" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "vmware_desktop" do |v|
v.vmx["displayName"] = "server"
v.vmx["numvcpus"] = "2"
v.vmx["memsize"] = "2048"
v.linked_clone = true
v.vmx["ethernet0.pcislotnumber"] = "160"
end
subconfig.vm.host_name = "server"
subconfig.vm.network "private_network", ip: "192.168.10.100"
subconfig.vm.network "forwarded_port", guest: 22, host: 60100, auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh"
subconfig.vm.provision "shell", inline: <<-SHELL
# Add other VMs to /etc/hosts for easy communication
echo "# VM cluster hosts" >> /etc/hosts
SHELL
end
# node-0
config.vm.define "node-0" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "vmware_desktop" do |v|
v.vmx["displayName"] = "node-0"
v.vmx["numvcpus"] = "2"
v.vmx["memsize"] = "2048"
v.linked_clone = true
v.vmx["ethernet0.pcislotnumber"] = "160"
end
subconfig.vm.host_name = "node-0"
subconfig.vm.network "private_network", ip: "192.168.10.101"
subconfig.vm.network "forwarded_port", guest: 22, host: 60101, auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh"
subconfig.vm.provision "shell", inline: <<-SHELL
# Add other VMs to /etc/hosts for easy communication
echo "# VM cluster hosts" >> /etc/hosts
SHELL
end
# node-1
config.vm.define "node-1" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "vmware_desktop" do |v|
v.vmx["displayName"] = "node-1"
v.vmx["numvcpus"] = "2"
v.vmx["memsize"] = "2048"
v.linked_clone = true
v.vmx["ethernet0.pcislotnumber"] = "160"
end
subconfig.vm.host_name = "node-1"
subconfig.vm.network "private_network", ip: "192.168.10.102"
subconfig.vm.network "forwarded_port", guest: 22, host: 60102, auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh"
subconfig.vm.provision "shell", inline: <<-SHELL
# Add other VMs to /etc/hosts for easy communication
echo "# VM cluster hosts" >> /etc/hosts
SHELL
end
end
vagrant up
vagrant status
vagrant up 명령을 실행하면 정의된 4대의 VM이 순차적으로 생성되며, init_cfg.sh에 의해 모든 시스템 기본 설정이 완료됩니다. vagrant status를 통해 모든 노드가 running 상태임을 확인할 수 있습니다.
 vagrant status
vagrant status
쿠버네티스 클러스터를 실제 프로덕션 환경이나 엔터프라이즈 환경에서 운영한다고 가정해보면, 각 노드가 외부 인터넷에 직접 접근할 수 있는 경우는 드뭅니다. 보안상의 이유로 Control Plane이나 Worker Node들은 외부와의 연결이 차단되어 있거나, DMZ 구역 혹은 프라이빗 네트워크에만 연결되어 있는 경우가 많습니다. 이런 환경에서는 각 노드가 스스로 kubectl이나 etcd 같은 바이너리를 다운로드하기 어렵습니다.
따라서 Jumpbox는 외부 인터넷에도 접근할 수 있고 동시에 내부 클러스터 네트워크에도 연결되어 있는 관리 서버로, 일종의 게이트웨이 역할을 합니다.
관리자는 Jumpbox를 통해 필요한 모든 바이너리를 인터넷에서 다운로드하고, 이후 scp나 ansible 같은 도구를 사용해 각 노드로 파일을 전송합니다. Jumpbox는 모든 노드에 SSH 접근 권한을 가지고 있기 때문에, 중앙에서 통제된 방식으로 동일한 버전의 바이너리를 배포할 수 있습니다.
따라서 설치해야 할 주요 컴포넌트는 다음과 같습니다.
- Control Plane: kube-apiserver, kube-controller-manager, kube-scheduler, etcd
- Worker Node: kubelet, kube-proxy, containerd, runc, CNI plugins
- 관리 도구: kubectl, etcdctl, crictl
실습환경에서는 아래의 버전을 기준으로 합니다.
| Components | Version |
|---|---|
| Kubernetes | 1.32 |
| etcd | 3.6.0 |
| containerd | 2.1.0 |
| runc | 1.3.0 |
먼저 Vagrant를 통해 SSH로 Jumpbox에 접속합니다.
vagrant ssh jumpbox
가이드를 기반으로 프로젝트 레포지토리를 동기화하고, 시스템 환경에 맞는 바이너리를 설치하는 것부터 시작합니다.
git clone --depth 1 https://github.com/kelseyhightower/kubernetes-the-hard-way.git
cd kubernetes-the-hard-way
쿠버네티스 컴포넌트는 시스템 아키텍처에 민감하기 때문에 아키텍처를 명확히 구분하여 바이너리를 내려받아야 합니다. dpkg –print-architecture 명령을 통해 현재 Jumpbox의 아키텍처를 확인하고, 이에 대응하는 다운로드 목록을 선택합니다.
선택된 아키텍처에 맞는 URL 목록을 활용하여 wget으로 바이너리를 다운로드합니다.
# Check CPU Architecture
dpkg --print-architecture
# Check Components
cat downloads-$(dpkg --print-architecture).txt
# Download Binary
wget -q --show-progress \
--https-only \
--timestamping \
-P downloads \
-i downloads-$(dpkg --print-architecture).txt
# Extract the component binaries from the release archives and organize them under the downloads directory
ARCH=$(dpkg --print-architecture)
각 컴포넌트가 실행될 목적지에 따라 client, controller, worker, cni-plugins로 디렉터리를 세분화합니다. 이후 추출된 파일들을 mv 명령을 통해 사전에 정의한 목적지별 폴더로 이동시킵니다.
# Create directory structure
mkdir -p downloads/{client,cni-plugins,controller,worker}
# Extract crictl binary
tar -xvf downloads/crictl-v1.32.0-linux-${ARCH}.tar.gz \
-C downloads/worker/ && tree -ug downloads
# Extract containerd package
tar -xvf downloads/containerd-2.1.0-beta.0-linux-${ARCH}.tar.gz \
--strip-components 1 \
-C downloads/worker/ && tree -ug downloads
# Extract CNI plugins
tar -xvf downloads/cni-plugins-linux-${ARCH}-v1.6.2.tgz \
-C downloads/cni-plugins/ && tree -ug downloads
# Extract only etcdctl and etcd binaries from the etcd archive
tar -xvf downloads/etcd-v3.6.0-rc.3-linux-${ARCH}.tar.gz \
-C downloads/ \
--strip-components 1 \
etcd-v3.6.0-rc.3-linux-${ARCH}/etcdctl \
etcd-v3.6.0-rc.3-linux-${ARCH}/etcd && tree -ug downloads
# Move binaries
mv downloads/{etcdctl,kubectl} downloads/client/
mv downloads/{etcd,kube-apiserver,kube-controller-manager,kube-scheduler} downloads/controller/
mv downloads/{kubelet,kube-proxy} downloads/worker/
mv downloads/runc.${ARCH} downloads/worker/runc
# Remove compressed archives
rm -rf downloads/*gz
이동 후에는 아래와 같은 파일 구조를 가지게 됩니다.
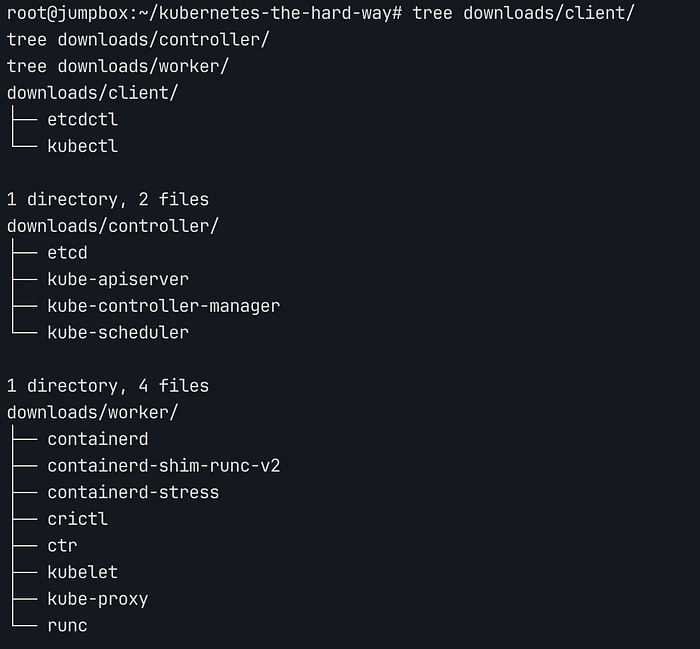 File Structure
File Structure
바이너리 배포 전, 마지막 단계는 실행 권한을 부여하고 파일의 소유권을 설정하는 것입니다.
root 사용자로 tar 압축 파일을 풀 때, 원본 빌드 환경의 소유자 정보가 그대로 복원됩니다. 따라서 tree -ug downloads를 확인해보면, etcd, etcdctl, crictl등은 root가 아닌 다른 소유자 정보를 가지고 있습니다.
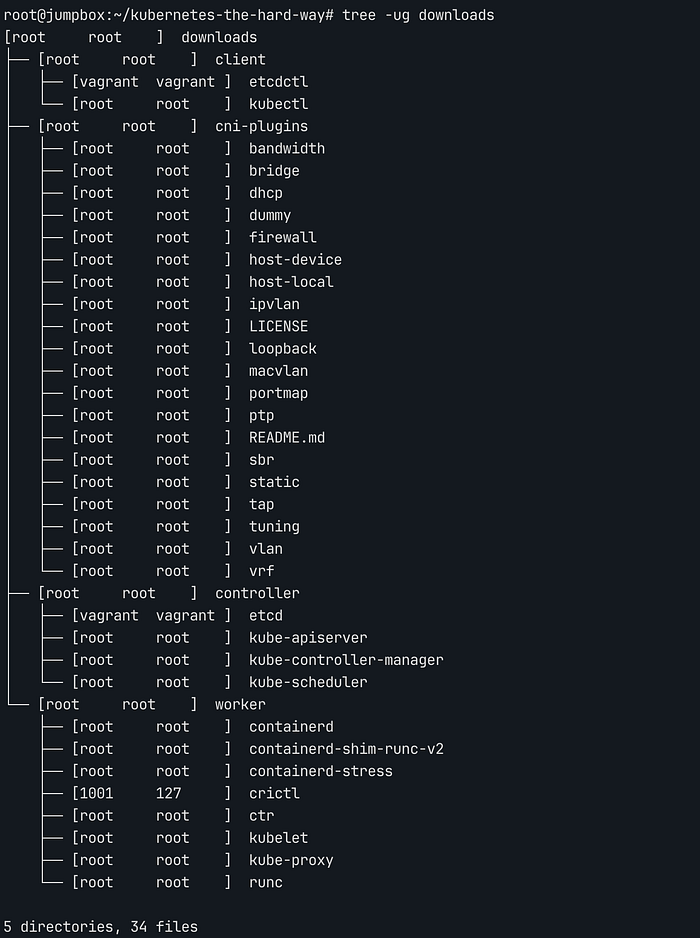 tree -ug downloads
tree -ug downloads
다른 바이너리들(kube-apiserver, kubelet 등)은 wget으로 직접 다운로드한 파일이라 이미 root:root 소유로 되어 있어서 별도로 chown을 할 필요가 없습니다.
# Change ownership
chown root:root downloads/client/etcdctl
chown root:root downloads/controller/etcd
chown root:root downloads/worker/crictl
마지막으로, Jumpbox 자체에서도 클러스터를 제어할 수 있도록 kubectl 바이너리를 시스템 경로인 /usr/local/bin/으로 복사합니다.
cp downloads/client/kubectl /usr/local/bin/
kubectl version --client 명령을 통해 정상적으로 버전이 출력된다면, 이제 Jumpbox는 각 노드에 바이너리를 배포하고 클러스터 전체를 제어할 수 있는 준비를 마친 상태가 됩니다.
Provisioning Compute Resources
쿠버네티스 클러스터를 구성하는 각 노드는 고유한 네트워크 식별자와 역할에 따른 서브넷 할당 정보를 가집니다. 이를 체계적으로 관리하기 위해 machines.txt 파일을 생성하여 관리 도구들이 참조할 수 있는 데이터 소스를 구축합니다.
machines.txt에는 각 노드의 IP 주소, 정규화된 도메인 이름(FQDN), 호스트네임, 그리고 각 워커 노드에 할당될 Pod Subnet 대역을 정의합니다.
cat <<EOF > machines.txt
192.168.10.100 server.kubernetes.local server
192.168.10.101 node-0.kubernetes.local node-0 10.200.0.0/24
192.168.10.102 node-1.kubernetes.local node-1 10.200.1.0/24
EOF
cat machines.txt
먼저 Jumpbox의 root 계정에서 RSA 알고리즘 기반의 SSH 키 쌍을 생성합니다. 생성된 공개키(id_rsa.pub)는 클러스터 내의 모든 노드에 배포되어 신뢰 관계를 형성하게 됩니다.
배포 과정에서는 sshpass 도구를 활용하여 초기 설정된 비밀번호를 자동으로 입력하고, StrictHostKeyChecking=no 옵션을 통해 호스트 키 검증을 생략함으로써 자동화 프로세스의 끊김을 방지합니다.
# Generate SSH Key
ssh-keygen -t rsa -N "" -f /root/.ssh/id_rsa
# Deploy public key from machines.txt
while read IP FQDN HOST SUBNET; do
sshpass -p 'qwe123' ssh-copy-id -o StrictHostKeyChecking=no root@${IP}
done < machines.txt
쿠버네티스 컴포넌트 간 통신은 종종 IP가 아닌 호스트네임이나 FQDN을 기반으로 이루어집니다. 따라서 각 노드가 자신의 이름과 클러스터 내 다른 노드의 이름을 정확히 인식하고 있는지 검증이 필요합니다.
이미 init_cfg.sh를 통해 각 노드의 /etc/hosts 파일에 클러스터 맵핑 정보가 주입되어 있기 때문에 Jumpbox에서는 이를 원격으로 조회하여 설정의 누락 여부를 확인합니다.
# Verify host mappings
while read IP FQDN HOST SUBNET; do
ssh -n root@${IP} cat /etc/hosts
done < machines.txt
# Verify fqdn
while read IP FQDN HOST SUBNET; do
ssh -n root@${IP} hostname --fqdn
done < machines.txt
# Verify connect by HOST
while read IP FQDN HOST SUBNET; do
sshpass -p 'qwe123' ssh -n -o StrictHostKeyChecking=no root@${HOST} hostname
done < machines.txt
TLS Certificates
쿠버네티스 클러스터는 분산 시스템이므로 각 컴포넌트가 서로를 신뢰할 수 있는 공통의 기준이 필요합니다. 이를 위해 가장 먼저 수행해야 할 작업은 Certificate Authority (CA)를 구축하는 것입니다. CA는 클러스터 내에서 발행되는 모든 인증서의 유효성을 보증하는 최상위 신뢰 루트(Root of Trust) 역할을 합니다.
실습 환경의 편의를 위해 미리 정의된 ca.conf 파일을 사용하지만, 그 본질은 클러스터 내 모든 통신의 신원을 보장하는 정책을 정의하는 데 있습니다.
일부 예시만 살펴보도록 하겠습니다.
[node-0]
distinguished_name = node-0_distinguished_name
prompt = no
req_extensions = node-0_req_extensions
[node-0_req_extensions]
basicConstraints = CA:FALSE
extendedKeyUsage = clientAuth, serverAuth # clientAuth: kubelet → apiserver & serverAuth: kubelet HTTPS 서버(10250)
keyUsage = critical, digitalSignature, keyEncipherment
nsCertType = client
nsComment = "Node-0 Certificate"
subjectAltName = DNS:node-0, IP:127.0.0.1
subjectKeyIdentifier = hash
[node-0_distinguished_name]
CN = system:node:node-0 # kubelet 사용자 , CN = system:node:<nodeName>
O = system:nodes # Node Authorizer 그룹 ,O = system:nodes
C = US
ST = Washington
L = Seattle
[Section]
- distinguished_name: 인증서의 주체(Subject) 정보를 어디서 가져올지 지정
- req_extensions: CSR을 만들 때, 추가할 확장(extension) 필드들이 어디 있는지 지정
[req_extensions]
- basicConstraints: CA인증서인지 확인
- extendedKeyUsage: 인증서 사용 용도 지정
- keyUsage: 키의 사용 방식 지정
- subjectAltName: 인증서가 유효한 DNS 이름과 IP주소 목록, SAN이 많은 경우 @를 통해서 별도의 섹션으로 구분 가능
[distinguished_name]
- CN (Common Name): kubernetes에서 사용자 이름으로 매핑되며, system:node:
등의 예약어 패턴이 있습니다. - O (Organization Name): kubernetes에서 그룹으로 매핑되며, system:nodes등의 예약어가 있습니다.
먼저 4096비트 RSA 알고리즘을 사용하여 CA 개인키(ca.key)를 생성합니다. 이후 openssl req -x509 명령어를 통해 CSR 과정 없이 즉시 자가 서명된 루트 인증서(ca.crt)를 발급합니다.
# Generate private key
openssl genrsa -out ca.key 4096
# Generate a self-signed Certificate Authority (CA) certificate
openssl req -x509 -new -sha512 -noenc \
-key ca.key -days 3653 \
-config ca.conf \
-out ca.crt
openssl을 사용하여 생성되는 ca.key는 절대 외부로 유출되어서는 안 되는 민감한 정보이며, ca.crt는 모든 노드에 배포되어 각 노드가 서로의 인증서를 검증하는 기준으로 활용됩니다.
관리자용 인증서는 쿠버네티스 클러스터에서 system:masters 그룹에 속하는 강력한 권한을 부여합니다. 이를 위해 CN=admin, O=system:masters 정보를 담은 CSR(인증서 서명 요청)을 생성합니다.
# Create Client and Server Certificates : admin
openssl genrsa -out admin.key 4096
# Generate admin certificate issuance process
openssl req -new -key admin.key -sha256 \
-config ca.conf -section admin \
-out admin.csr
# Sign the CSR with the CA to issue the admin certificates
openssl x509 -req -days 3653 -in admin.csr \
-copy_extensions copyall \
-sha256 -CA ca.crt \
-CAkey ca.key \
-CAcreateserial \
-out admin.crt
쿠버네티스는 컴포넌트마다 요구하는 권한과 식별 정보가 다르기 때문에 다수의 컴포넌트에서도 위와 같이 ca.conf 에 정의된 섹션을 통해 인증서를 생성합니다.
ca.conf 파일 내에서 system:kube-scheduler의 OU 정보가 중복 기재되어 있기 때문에 이를 먼저 수정합니다.
sed -i 's/system:system:kube-scheduler/system:kube-scheduler/' ca.conf
certs=(
"node-0"
"node-1"
"kube-proxy"
"kube-scheduler"
"kube-controller-manager"
"kube-api-server"
"service-accounts"
)
for i in ${certs[*]}; do
openssl genrsa -out "${i}.key" 4096
openssl req -new -key "${i}.key" -sha256 \
-config "ca.conf" -section ${i} \
-out "${i}.csr"
openssl x509 -req -days 3653 -in "${i}.csr" \
-copy_extensions copyall \
-sha256 -CA "ca.crt" \
-CAkey "ca.key" \
-CAcreateserial \
-out "${i}.crt"
done
모든 작업이 완료되면 ls -l *.crt *.key *.csr을 통해 아래와 같은 결과를 확인할 수 있습니다.
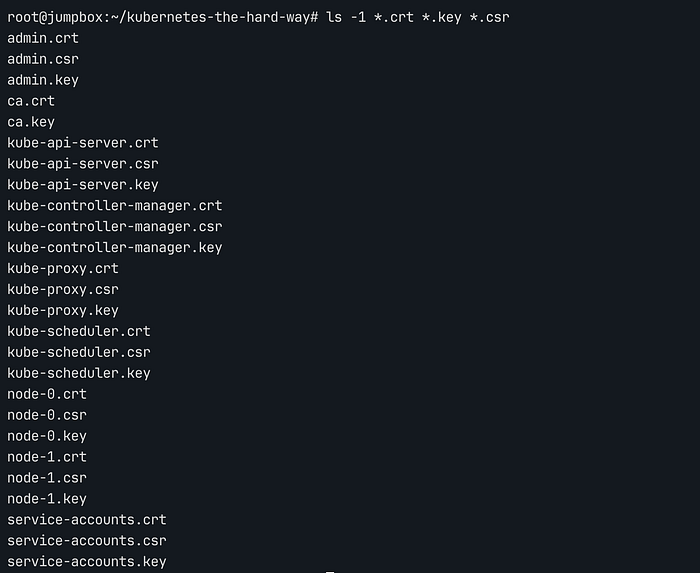 Certificate Files
Certificate Files
인증서 발급 절차가 완료되었다면 발급된 인증서와 개인키를 각 노드로 배포하는 과정입니다. 핵심은 최소 권한 원칙에 따라 각 컴포넌트가 작동하는 데 꼭 필요한 파일만 전송하는 것입니다.
Worker Node에서 동작하는 kubelet은 Kubernetes API Server와 통신을 시작할 때, TLS Handshake 과정을 수행합니다. 이 과정에서 kubelet은 API Server가 제시한 서버 인증서를 수신하며, 해당 인증서가 자신이 속한 클러스터에서 발급된 정당한 인증서인지 검증하기 위해 로컬에 저장된 /var/lib/kubelet/ca.crt를 기준으로 신뢰성을 확인합니다.
이후 각 노드의 kubelet.crt와 kubelet.key는 반대로 API 서버가 해당 노드의 신원을 확인하는 자격 증명으로 사용되어 양방향 인증(mTLS)을 완성합니다.
for host in node-0 node-1; do
ssh root@${host} mkdir -p /var/lib/kubelet/
scp ca.crt root@${host}:/var/lib/kubelet/
scp ${host}.crt \
root@${host}:/var/lib/kubelet/kubelet.crt
scp ${host}.key \
root@${host}:/var/lib/kubelet/kubelet.key
done
Control Plane 역할을 수행하는 server 노드 역시 자신이 API 서버로서의 신원을 증명하고, 클러스터 내부의 다양한 보안 작업을 수행해야 합니다.
이를 위해 이미 생성된 kube-api-server.crt와 kube-api-server.key는 API 서버가 구동될 때, 로드되어 외부 요청에 대한 응답 시 자신의 정당성을 입증하는 데 사용됩니다.
또한 service-accounts.key와 service-accounts.crt는 Pod 내 서비스 계정이 API 서버와 통신하기 위해 필요한 토큰을 생성하고 그 정합성을 서명하는 데 활용됩니다.
이러한 파일들을 Control Plane의 root 홈 디렉터리로 전송하는 것은 이후 시스템 서비스 설정 시, 해당 컴포넌트들이 이 경로를 참조하여 통신을 시작할 수 있게 하기 위함입니다.
scp \
ca.key ca.crt \
kube-api-server.key kube-api-server.crt \
service-accounts.key service-accounts.crt \
root@server:~/
Generating Kubernetes Configuration Files for Authentication
kubeconfig는 쿠버네티스 클러스터에 접속하기 위한 설정 파일로 kubectl이나 kubelet 같은 클라이언트들이 어떤 API Server에 접속해야 하는지, 어떤 인증서를 사용해야 하는지와 같은 정보를 가지고 있습니다.
즉 Kubeconfig 파일은 클러스터 접근 제어를 위한 세 가지 핵심 요소를 구조화한 데이터입니다.
- Clusters: 접속 대상이 되는 API 서버의 주소와 해당 서버의 인증서를 검증할 Root CA 정보를 포함합니다.
- Users: 통신 주체의 신원을 증명하는 클라이언트 인증서와 개인키를 정의합니다.
- Contexts: 위 두 요소를 결합하여 “어느 클러스터에 어떤 사용자로 접속할 것인가”를 정의하고 기본값(Current-context)을 설정합니다.
따라서 각 노드는 자신만의 고유한 kubeconfig를 소유합니다.
kubelet
# 1. Set cluster
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443 \
--kubeconfig=node-0.kubeconfig
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443 \
--kubeconfig=node-1.kubeconfig
# 2. Set credentials
kubectl config set-credentials system:node:node-0 \
--client-certificate=node-0.crt \
--client-key=node-0.key \
--embed-certs=true \
--kubeconfig=node-0.kubeconfig
kubectl config set-credentials system:node:node-1 \
--client-certificate=node-1.crt \
--client-key=node-1.key \
--embed-certs=true \
--kubeconfig=node-1.kubeconfig
# 3. Set context
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:node:node-0 \
--kubeconfig=node-0.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:node:node-1 \
--kubeconfig=node-1.kubeconfig
# 4. Use context
kubectl config use-context default \
--kubeconfig=node-0.kubeconfig
kubectl config use-context default \
--kubeconfig=node-1.kubeconfig
Worker Node에서 실행되는 kubelet은 클러스터의 상태를 보고하기 위해 API 서버와 상시 통신해야 합니다.
따라서 첫 번째 명령어로 API Server의 접속 정보를 등록해야 합니다. –embed-certs=true 옵션을 통해 ca.crt의 내용을 base64로 인코딩하여 kubeconfig 파일 내부에 직접 포함시키므로, 별도의 인증서 파일 없이도 이 파일 하나만으로 클러스터에 접속할 수 있습니다.
두 번째 명령어는 kubelet의 신원을 증명할 클라이언트 인증서와 개인키를 등록합니다. 여기서 사용자 이름은 system:node:node-0 형식을 따라야 하는데, 이는 Kubernetes의 Node Authorizer가 인식하는 특별한 패턴입니다. 이 형식을 지키지 않으면 노드로 인식되지 않아 권한이 부여되지 않습니다.
세 번째 명령어는 앞서 정의한 클러스터와 사용자를 연결하여 하나의 컨텍스트를 만듭니다.
마지막 명령어는 생성한 컨텍스트를 기본값으로 설정하여, kubelet이 이 kubeconfig를 참조할 때 자동으로 해당 설정을 사용하도록 합니다.
kube-proxy
# Generate a kubeconfig file for the kube-proxy service
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443 \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-credentials system:kube-proxy \
--client-certificate=kube-proxy.crt \
--client-key=kube-proxy.key \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
kubectl config use-context default \
--kubeconfig=kube-proxy.kubeconfig
kube-controller-manager
# Generate a kubeconfig file for the kube-controller-manager service
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443 \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=kube-controller-manager.crt \
--client-key=kube-controller-manager.key \
--embed-certs=true \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-controller-manager \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config use-context default \
--kubeconfig=kube-controller-manager.kubeconfig
kube-scheduler
# Generate a kubeconfig file for the kube-scheduler service
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443 \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-credentials system:kube-scheduler \
--client-certificate=kube-scheduler.crt \
--client-key=kube-scheduler.key \
--embed-certs=true \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-scheduler \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config use-context default \
--kubeconfig=kube-scheduler.kubeconfig
Admin
# Generate a kubeconfig file for the admin user
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://127.0.0.1:6443 \
--kubeconfig=admin.kubeconfig
kubectl config set-credentials admin \
--client-certificate=admin.crt \
--client-key=admin.key \
--embed-certs=true \
--kubeconfig=admin.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=admin \
--kubeconfig=admin.kubeconfig
kubectl config use-context default \
--kubeconfig=admin.kubeconfig
Distribute the kubeconfig files
위와 같이 각 컴포넌트에 대해 kubeconfig 파일을 설정하게 되면 ls -l *.kubeconfig를 통해 생성된 config들을 확인할 수 있습니다.
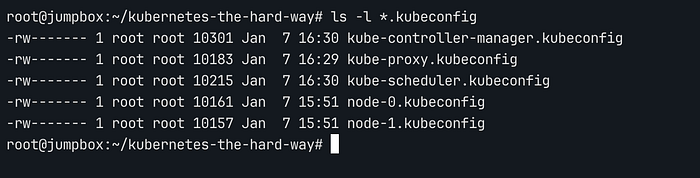 kubeconfig files
kubeconfig files
각 노드의 역할(Control Plane, Worker Node)에 따라 필요한 Kubeconfig 파일을 분류하고 표준 경로에서 파일을 참조할 수 있도록 배포하도록 합니다.
Worker Node(node-0, node-1)에는 해당 노드의 kubelet과 클러스터 네트워킹을 담당할 kube-proxy를 위한 설정 파일이 배포됩니다.
# Copy the kubelet and kube-proxy kubeconfig files to the node-0 and node-1 machines
for host in node-0 node-1; do
ssh root@${host} "mkdir -p /var/lib/{kube-proxy,kubelet}"
scp kube-proxy.kubeconfig \
root@${host}:/var/lib/kube-proxy/kubeconfig \
scp ${host}.kubeconfig \
root@${host}:/var/lib/kubelet/kubeconfig
done
배포가 완료되면 SSH를 통해 각 노드의 지정된 경로에 파일이 올바르게 위치했는지 최종 확인합니다.
 Worker Node 배포 확인
Worker Node 배포 확인
Control Plane(server) 노드에는 클러스터의 상태를 관리하고 스케줄링을 담당하는 핵심 컴포넌트들을 위한 설정 파일이 배포됩니다.
# Copy the kube-controller-manager and kube-scheduler kubeconfig files to the server machine
scp admin.kubeconfig \
kube-controller-manager.kubeconfig \
kube-scheduler.kubeconfig \
root@server:~/
 Control Plane 배포 확인
Control Plane 배포 확인
Generating the Data Encryption Config and Key
쿠버네티스의 상태 저장소인 etcd에 저장되는 데이터 중 Secret 리소스는 API 키, 패스워드, 인증서와 같은 민감한 정보를 포함합니다.
기본적으로 etcd는 데이터를 평문으로 저장하기 때문에, 물리적 저장소에 대한 접근 권한이 탈취될 경우 보안 침해 사고로 이어질 수 있습니다. 이를 방지하기 위해 쿠버네티스는 Encrypting Confidential Data at Rest 기능을 제공합니다. 이는 API Server가 etcd에 데이터를 쓸 때 자동으로 암호화하고, 읽을 때 복호화하는 방식으로 작동합니다.
먼저 Secret 데이터를 암호화할 때, 사용할 32바이트 키를 생성합니다. 이 키가 노출되거나 유실될 경우, 클러스터 내 모든 Secret 데이터를 복구할 수 없으므로 엄격하게 관리되어야 합니다.
# Generate an encryption key
export ENCRYPTION_KEY=$(head -c 32 /dev/urandom | base64)
echo $ENCRYPTION_KEY
API Server는 시작 시 –encryption-provider-config 플래그로 지정된 설정 파일을 읽어 암호화 정책을 적용합니다. 이 파일은 어떤 암호화 방식을 사용할지, 어떤 순서로 시도할지를 정의합니다.
kind: EncryptionConfiguration
apiVersion: apiserver.config.k8s.io/v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: ${ENCRYPTION_KEY}
- identity: {}
공식 문서에서 지원하는 여러 프로바이더 중, 본 실습에서는 aescbc와 identity를 조합하여 사용합니다.
- aescbc: AES-CBC 알고리즘과 PKCS7 패딩을 사용하는 방식입니다. 현재 쿠버네티스에서 가장 널리 사용되는 암호화 방식이며, etcd에 저장되는 데이터에 k8s:enc:aescbc:v1:key1:과 같은 식별 헤더를 추가하여 관리합니다.
- identity: 암호화를 수행하지 않는 평문(Plaintext) 방식을 의미합니다.
따라서 aescbc를 첫 번째에, identity를 두 번째에 배치하는 것은 “새로운 데이터는 무조건 암호화해서 저장하되, 이전에 평문으로 저장되었던 데이터도 문제없이 읽어 들이겠다”는 하위 호환성 전략을 의미합니다.
미리 정의된 템플릿 파일(configs/encryption-config.yaml) 내의 ${ENCRYPTION_KEY} 변수를 실제 생성한 키로 치환하여 최종 설정 파일을 생성합니다. 이후, API 서버가 구동될 Control Plane 으로 해당 파일을 배포합니다.
# Substitute environment variables in configs/encryption-config.yaml
envsubst < configs/encryption-config.yaml > encryption-config.yaml
# Copy the generated encryption-config.yaml file
scp encryption-config.yaml root@server:~/
Bootstrapping the etcd Cluster
etcd는 분산 키-값 저장소로, Raft 합의 알고리즘을 사용하여 고가용성을 보장합니다. Nodes, Pods, ConfigMaps, Secrets를 비롯한 모든 리소스의 현재 상태와 원하는 상태가 etcd에 보관되며, API Server는 etcd와 통신하는 유일한 컴포넌트입니다.
일반적인 운영 환경의 쿠버네티스에서 etcd는 반드시 TLS(HTTPS)로 보호되어야 합니다. 하지만 본 실습의 etcd.service 설정을 보면 모든 엔드포인트가 http://127.0.0.1로 정의된 것을 확인할 수 있습니다.
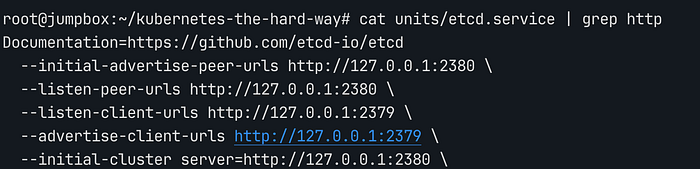 etcd HTTP 설정
etcd HTTP 설정
이는 loopback 주소로 내부에서만 도는 데이터이므로 굳이 복잡한 TLS(HTTPS)를 쓰지 않고 HTTP로도 안전하고 간결하게 구성한 것입니다.
따라서 server 노드 내에서만 유효한 고유한 etcd 멤버를 구성합니다. ${ETCD_NAME}을 실제 호스트네임인 server와 일치시켜 클러스터 내 식별자를 명확히 하고 이를 server 노드에 포함합니다.
# Set the environment variable
ETCD_NAME=server
# Create a systemd unit file for etcd
cat > units/etcd.service <<EOF
[Unit]
Description=etcd
Documentation=https://github.com/etcd-io/etcd
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd \\
--name ${ETCD_NAME} \\
--initial-advertise-peer-urls http://127.0.0.1:2380 \\
--listen-peer-urls http://127.0.0.1:2380 \\
--listen-client-urls http://127.0.0.1:2379 \\
--advertise-client-urls http://127.0.0.1:2379 \\
--initial-cluster-token etcd-cluster-0 \\
--initial-cluster ${ETCD_NAME}=http://127.0.0.1:2380 \\
--initial-cluster-state new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# Copy the etcd binary, etcdctl client tool, and the systemd unit file
scp \
downloads/controller/etcd \
downloads/client/etcdctl \
units/etcd.service \
root@server:~/
ssh root@server를 통해 server 노드 내부에서 바이너리를 /usr/local/bin/으로 배치합니다.
다음으로 etcd의 데이터가 저장될 /var/lib/etcd 디렉터리를 생성하고, chmod 700을 적용합니다. 이는 시스템의 다른 일반 사용자가 클러스터의 민감한 상태 정보에 접근하는 것을 원천 차단하기 위함입니다.
# Move etcd and etcdctl binaries into /usr/local/bin
mv etcd etcdctl /usr/local/bin/
# Create configuration and data directories for etcd
mkdir -p /etc/etcd /var/lib/etcd
# Set secure permissions on the data directory
chmod 700 /var/lib/etcd
# Move the systemd unit file for etcd into the systemd directory
mv etcd.service /etc/systemd/system/
설정 파일 배포가 완료되면, 리눅스 서비스 관리자인 Systemd를 통해 etcd 프로세스를 관리 시스템에 등록 후 시작합니다.
systemctl daemon-reload
systemctl enable etcd
systemctl start etcd
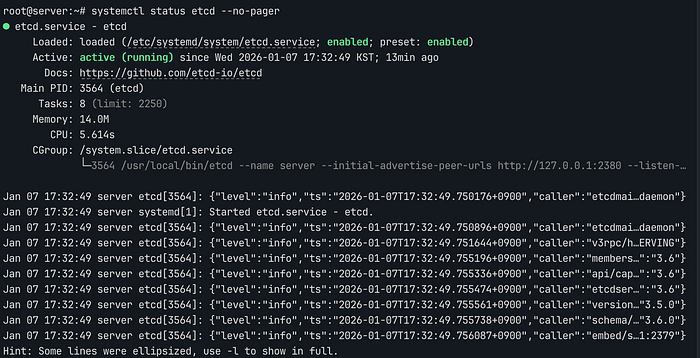 systemctl status etcd –no-pager
systemctl status etcd –no-pager
서비스가 구동된 후에는 시스템 수준과 애플리케이션 수준에서 각각 정합성을 검증합니다.
ss -tnlp 명령으로 2379(Client)와 2380(Peer) 포트가 127.0.0.1 주소에서 정상적으로 대기 중인지 확인합니다.
etcdctl member list -w table를 실행하여 server 멤버가 정상적으로 클러스터에 참여하여 started 상태가 되었는지 확인합니다.
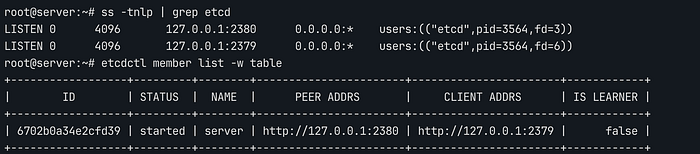 etcd 검증
etcd 검증
Bootstrapping the Kubernetes Control Plane
앞서 구축한 etcd 저장소를 기반으로, Control Plane을 구성하는 kube-apiserver, kube-scheduler, kube-controller-manager를 실제로 배포하고 설정하는 방법을 이해하는 것이 목표입니다.
Control Plane을 부트스트래핑하기 전에 먼저 네트워크 구성과 필수 파일들을 준비해야 합니다.
본 구성에서는 세 가지 주요 네트워크 대역을 사용하며, 각각의 역할이 명확히 구분됩니다.
Cluster CIDR은 10.200.0.0/16으로 설정되어 전체 Pod 네트워크 대역을 정의합니다. 이는 다시 각 노드별로 세분화됩니다.
- node-0은 10.200.0.0/24
- node-1은 10.200.1.0/24
의 Pod CIDR을 할당받아 해당 노드에서 실행되는 Pod들이 이 범위 내의 IP 주소를 사용하게 됩니다.
Service CIDR은 10.32.0.0/24로 구성되며, 이는 클러스터 내부에서 Service 객체들이 사용할 가상 IP 주소 범위를 정의합니다. 특히 이 범위의 첫 번째 IP인 10.32.0.1은 API Server 자체의 ClusterIP로 예약되어, 클러스터 내부에서 API Server에 접근할 때 사용됩니다.
이러한 네트워크 대역 설정을 확인하기 위해 먼저 CA 설정 파일에서 API Server의 Subject Alternative Name을 검증해야 합니다.
이는 앞서 발급한 인증서(SAN 항목)의 정보와 완벽히 일치해야 합니다.
cat ca.conf | grep '\[kube-api-server_alt_names' -A2
 네트워크 설정 확인
네트워크 설정 확인
여기서 IP.1의 값인 10.32.0.1이 Service CIDR의 첫 번째 주소와 일치하는지 확인해야 합니다. 이는 TLS 인증서의 SAN에 해당 IP가 포함되어야 API Server가 이 IP로 접근을 받을 때 인증서 검증이 성공하기 때문입니다. 만약 이 값이 일치하지 않으면 클러스터 내부의 Pod들이 Kubernetes Service를 통해 API Server에 접근할 때 TLS 검증 오류가 발생하게 됩니다.
설치하고자 하는 쿠버네티스 컴포넌트(etcd, apiserver, kubelet 등)는 정적으로 링크된 Go 언어 바이너리 실행 파일입니다. 이러한 바이너리들은 클러스터의 안정적인 운영을 위해서는 다음과 같은 요구사항을 충족해야 합니다.
- 서버가 재부팅될 때 자동으로 시작되어야 합니다. Control Plane이 수동으로 시작되어야 한다면 서버 장애 후, 복구 시간이 길어지고 운영 복잡도가 증가합니다.
- 프로세스가 예기치 않게 종료되었을 때, 자동으로 재시작되어야 합니다. 메모리 부족이나 버그로 인해 프로세스가 크래시될 수 있으며, 이러한 상황에서 자동 복구 메커니즘이 없다면 클러스터 전체가 다운될 수 있습니다.
- 각 컴포넌트는 독립적으로 시작, 중지, 재시작할 수 있어야 합니다. 특정 컴포넌트만 업데이트하거나 설정을 변경할 때 다른 컴포넌트에 영향을 주지 않아야 합니다.
따라서 이러한 요구사항을 충족하기 위한 솔루션으로 백그라운드 서비스 관리를 위해 systemd 설정을 위한 Unit file이 필요합니다.
Kubernetes 컴포넌트들은 바이너리 실행 파일이지만 각각 고유한 설정이 필요합니다. 이러한 설정은 주로 두 가지 방식으로 제공됩니다.
-
command-line flags로, systemd 유닛 파일의 ExecStart에 직접 지정됩니다. 이 방식은 간단한 설정에 적합하며 유닛 파일만 봐도 전체 설정을 파악할 수 있다는 장점이 있습니다. 예를 들어 kube-apiserver는 대부분의 설정을 명령줄 플래그로 받으며, authorization-mode, service-cluster-ip-range, tls-cert-file 등 수십 개의 플래그가 사용됩니다.
-
YAML 형식의 별도 파일에 설정을 정의하고 해당 파일의 경로를 명령줄 플래그로 전달합니다. 이 방식은 복잡한 설정 구조를 표현하기에 적합하며, 설정 파일만 교체하여 쉽게 설정을 변경할 수 있습니다.
kube-apiserver
kube-apiserver는 모든 API 요청의 진입점이자 클러스터 상태 관리의 중심입니다. 앞서 말한것과 같이 API Server의 설정은 systemd 유닛 파일을 통해 정의되며, 여러 중요한 파라미터들이 클러스터의 보안과 기능을 결정합니다.
이전 단계에서 정의한 Service CIDR(10.32.0.0/24)이나 API Server IP(10.32.0.1)와 같은 정보들은 바이너리 자체가 알 수 없는 정보이기 때문에 –service-cluster-ip-range 플래그를 추가합니다.
cat << EOF > units/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-apiserver \\
--allow-privileged=true \\
--apiserver-count=1 \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/var/log/audit.log \\
--authorization-mode=Node,RBAC \\
--bind-address=0.0.0.0 \\
--client-ca-file=/var/lib/kubernetes/ca.crt \\
--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \\
--etcd-servers=http://127.0.0.1:2379 \\
--event-ttl=1h \\
--encryption-provider-config=/var/lib/kubernetes/encryption-config.yaml \\
--kubelet-certificate-authority=/var/lib/kubernetes/ca.crt \\
--kubelet-client-certificate=/var/lib/kubernetes/kube-api-server.crt \\
--kubelet-client-key=/var/lib/kubernetes/kube-api-server.key \\
--runtime-config='api/all=true' \\
--service-account-key-file=/var/lib/kubernetes/service-accounts.crt \\
--service-account-signing-key-file=/var/lib/kubernetes/service-accounts.key \\
--service-account-issuer=https://server.kubernetes.local:6443 \\
--service-cluster-ip-range=10.32.0.0/24 \\
--service-node-port-range=30000-32767 \\
--tls-cert-file=/var/lib/kubernetes/kube-api-server.crt \\
--tls-private-key-file=/var/lib/kubernetes/kube-api-server.key \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
API 서버가 워커 노드의 kubelet에 접속하여 로그를 조회하거나 메트릭을 수집할 때, kubelet은 API 서버의 신원을 확인합니다.
API 서버의 클라이언트 인증서 CN은 kubernetes이며, 이 사용자가 kubelet의 API 엔드포인트에 접근할 수 있도록 권한 정의가 필요합니다.
이를 위해 system:kube-apiserver-to-kubelet이라는 ClusterRole을 통해 nodes/proxy, nodes/stats, nodes/log 등 노드의 하위 리소스에 대한 권한을 부여하는 configs/kube-apiserver-to-kubelet.yaml 이 아래와 같이 정의되어 있습니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
위와 같이 다른 컴포넌트들도 unit파일과 YAML파일등이 정의되어 있습니다.
# kube-scheduler
cat units/kube-scheduler.service ; echo
cat configs/kube-scheduler.yaml ; echo
# kube-controller-manager
cat units/kube-controller-manager.service ; echo
따라서 정의되어 있는 파일에 기반하여 jumpbox 서버에서 server 노드로 필요한 바이너리와 설정 파일들을 전송해야 합니다.
# Connect to the jumpbox and copy Kubernetes binaries and systemd unit files to the server machine
scp \
downloads/controller/kube-apiserver \
downloads/controller/kube-controller-manager \
downloads/controller/kube-scheduler \
downloads/client/kubectl \
units/kube-apiserver.service \
units/kube-controller-manager.service \
units/kube-scheduler.service \
configs/kube-scheduler.yaml \
configs/kube-apiserver-to-kubelet.yaml \
root@server:~/
Provision the Kubernetes Control Plane
모든 정적 설정 파일과 바이너리가 server 노드로 배포되었다면, 이제 전송된 바이너리와 설정 파일들을 정의된 경로로 정렬하고, 서비스로 등록합니다.
먼저 Kubernetes 핵심 바이너리를 실행 경로로 배치하고, 설정 파일들이 위치할 디렉터리 구조를 생성합니다.
# Create the Kubernetes configuration directory
mkdir -p /etc/kubernetes/config
# Install the Kubernetes binaries
mv kube-apiserver \
kube-controller-manager \
kube-scheduler kubectl \
/usr/local/bin/
각 컴포넌트의 Systemd 유닛 파일에 정의된 경로에 맞춰 인증서, 키, Kubeconfig 파일을 배치합니다.
# Configure the Kubernetes API Server
mkdir -p /var/lib/kubernetes/
# Configure the Kubernetes API Server
mv ca.crt ca.key \
kube-api-server.key kube-api-server.crt \
service-accounts.key service-accounts.crt \
encryption-config.yaml \
/var/lib/kubernetes/
# Register the Kubernetes API Server systemd unit file
mv kube-apiserver.service /etc/systemd/system/kube-apiserver.service
Controller Manager도 API 서버와 통신하기 위한 Kubeconfig와 유닛 파일을 배치합니다.
# Move the kube-controller-manager Kubeconfig file
mv kube-controller-manager.kubeconfig /var/lib/kubernetes/
# Register the Kubernetes Controller Manager systemd unit file
mv kube-controller-manager.service /etc/systemd/system/
Scheduler도 Kubeconfig와 YAML 설정 파일, 그리고 유닛 파일을 각각 지정된 경로로 이동합니다.
# Move the kube-scheduler kubeconfig file
mv kube-scheduler.kubeconfig /var/lib/kubernetes/
# Move the YAML file
mv kube-scheduler.yaml /etc/kubernetes/config/
# Register the Kubernetes Scheduler systemd unit file
mv kube-scheduler.service /etc/systemd/system/
파일 배치가 완료되면 Systemd 데몬을 갱신하고 서비스를 시작합니다.
systemctl daemon-reload
systemctl enable kube-apiserver kube-controller-manager kube-scheduler
systemctl start kube-apiserver kube-controller-manager kube-scheduler
서비스가 정상적으로 부트스트래핑되었는지 네트워크, 프로세스, API 세 단계로 검증합니다.
ss 명령어로 각 서비스가 정해진 포트에서 리스닝 중인지 확인합니다.
- 6443: API Server
- 10257: Controller Manager
- 10259: Scheduler
 네트워크 포트 확인
네트워크 포트 확인
Systemd 상태와 저널 로그를 통해 런타임 오류 여부를 점검합니다.
systemctl is-active kube-apiserver
systemctl status kube-apiserver --no-pager
journalctl -u kube-apiserver --no-pager
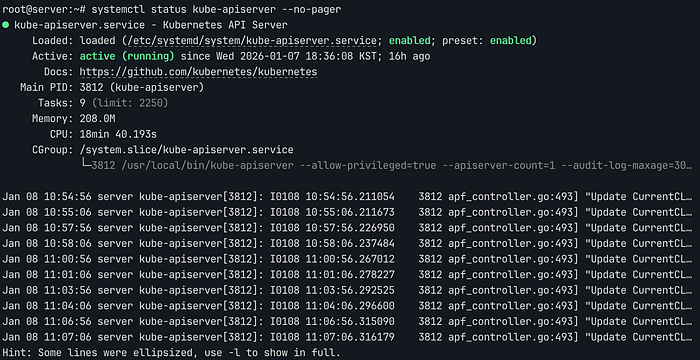 systemctl status kube-apiserver –no-pager
systemctl status kube-apiserver –no-pager
admin.kubeconfig를 사용하여 API 서버가 인지하는 클러스터 상태를 최종 확인합니다.
# Verify cluster information and API server endpoints
kubectl cluster-info --kubeconfig admin.kubeconfig
# Verify creation of default services and endpoints (check assignment of 10.32.0.1)
kubectl get service,ep --kubeconfig admin.kubeconfig
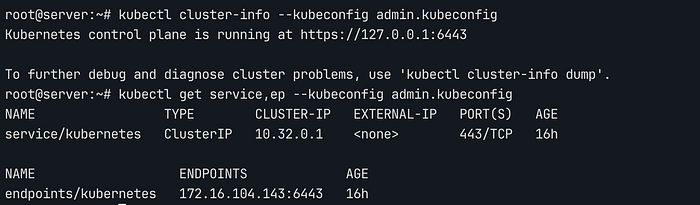 API Server 상태 확인
API Server 상태 확인
컨트롤 플레인이 구동되면 시스템 운영에 필요한 ClusterRole들이 자동 생성됩니다.
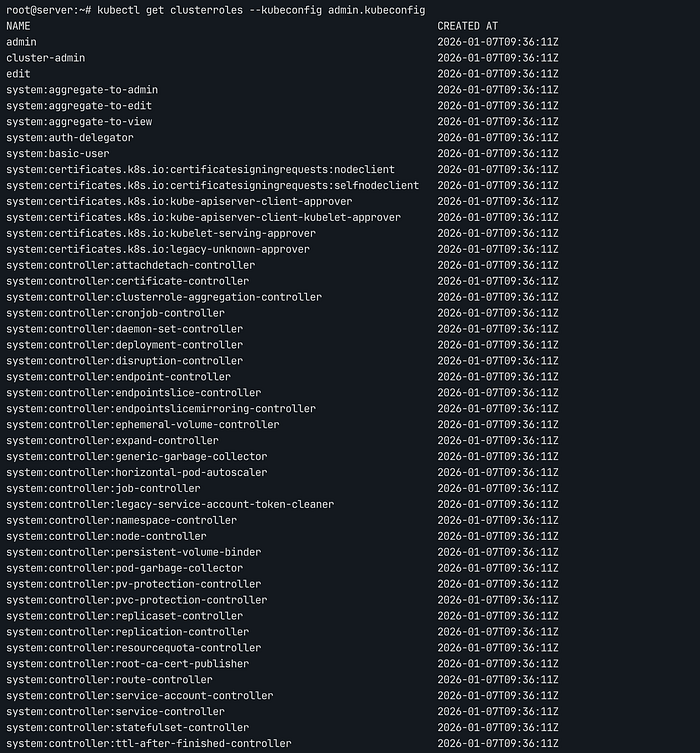 kubectl get clusterroles –kubeconfig admin.kubeconfig
kubectl get clusterroles –kubeconfig admin.kubeconfig
RBAC for Kubelet Authorization
Kubernetes API 서버가 각 워커 노드의 Kubelet API에 액세스할 수 있도록 인가(Authorization) 규칙을 정의합니다.
Kubelet은 –authorization-mode 플래그가 Webhook으로 설정됩니다. 이 모드에서 Kubelet은 자신에게 들어오는 요청(API 서버로부터의 호출)에 대해 권한이 있는지 결정하기 위해 SubjectAccessReview API를 사용하여 API 서버에 역으로 질의합니다. 따라서 API 서버가 사용하는 자격 증명에 적절한 권한이 부여되어 있어야 합니다.
이전에 Jumpbox에서 전송했던 kube-apiserver-to-kubelet.yaml 파일을 사용하여 ClusterRole과 ClusterRoleBinding을 생성합니다.
kubectl apply -f kube-apiserver-to-kubelet.yaml --kubeconfig admin.kubeconfig
생성된 리소스는 아래의 명령어로 조회할 수 있습니다.
kubectl get clusterroles system:kube-apiserver-to-kubelet --kubeconfig admin.kubeconfig
kubectl get clusterrolebindings system:kube-apiserver --kubeconfig admin.kubeconfig
Bootstrapping the Kubernetes Worker Nodes
해당 섹션에서는 쿠버네티스 클러스터의 실제 워크로드를 담당할 워커 노드(node-0, node-1)를 구성합니다. 각 노드에는 컨테이너를 실행하기 위한 runc, containerd, CNI 플러그인과 클러스터 에이전트인 kubelet, kube-proxy가 설치됩니다.
먼저 각 노드는 고유한 Pod CIDR 대역을 가져야 합니다. Jumpbox에서 각 노드의 서브넷 정보를 주입하여 설정 파일을 생성하고 배포합니다. machines.txt 에 정의되어 있는 서브넷 정보를 치환합니다.
보안을 위해 익명 인증을 비활성화하고, 모든 인증 및 인가 요청을 Webhook 모드를 통해 API 서버에 위임하도록 설정합니다. 이러한 설정은 configs/kubelet-config.yaml 에 위치하고 있습니다.
for HOST in node-0 node-1; do
SUBNET=$(grep ${HOST} machines.txt | cut -d " " -f 4)
sed "s|SUBNET|$SUBNET|g" configs/10-bridge.conf > 10-bridge.conf
sed "s|SUBNET|$SUBNET|g" configs/kubelet-config.yaml > kubelet-config.yaml
scp 10-bridge.conf kubelet-config.yaml root@${HOST}:~/
done
실제 워커 노드 내부에서 운영체제 종속성 설치 및 바이너리 배치를 수행합니다.
for HOST in node-0 node-1; do
scp \
downloads/worker/* \
downloads/client/kubectl \
configs/99-loopback.conf \
configs/containerd-config.toml \
configs/kube-proxy-config.yaml \
units/containerd.service \
units/kubelet.service \
units/kube-proxy.service \
root@${HOST}:~/
done
- configs/99-loopback.conf: 컨테이너 내부의 로컬 loopback(127.0.0.1) 네트워크를 생성하기 위한 CNI 설정입니다.
- configs/containerd-config.toml: kubelet의 요청을 받아 실제 컨테이너를 실행하는 containerd의 설정 파일입니다.
- configs/kube-proxy-config.yaml: iptables를 통해 Cluster IP를 실제 Pod IP로 변환하여 트래픽을 분산시킵니다.
- units/containerd.service: containerd를 systemd 서비스로 관리하기 위한 유닛 파일
- units/kubelet.service: API Server와 containerd 사이에서 Pod 생명주기를 관리하는 kubelet의 systemd 유닛 파일
- units/kube-proxy.service: kube-proxy를 systemd 서비스로 실행하는 유닛 파일
Jumpbox의 downloads/cni-plugins/ 디렉터리에 포함된 다양한 네트워크 플러그인(bridge, loopback, host-local, portmap 등)을 각 워커 노드의 디렉터리(~/cni-plugins/)로 일괄 전송합니다.
for HOST in node-0 node-1; do
scp \
downloads/cni-plugins/* \
root@${HOST}:~/cni-plugins/
done
Jumpbox에서 전송된 바이너리와 설정 파일을 기반으로 워커 노드(node-0)의 컨테이너 런타임 및 에이전트 서비스를 구성하고 활성화합니다.
노드 내부(ssh root@node-0)에서 컨테이너 운영 및 네트워크 관리에 필요한 필수 패키지를 설치하고 Swap을 비활성화합니다.
# Install OS dependencies
apt-get -y install socat conntrack ipset kmod psmisc bridge-utils
# Verify if swap is disabled
swapon --show
각 컴포넌트가 위치할 표준 디렉터리를 생성하고, 실행 파일들을 시스템 경로로 이동합니다.
# Create the installation directories
mkdir -p \
/etc/cni/net.d \
/opt/cni/bin \
/var/lib/kubelet \
/var/lib/kube-proxy \
/var/lib/kubernetes \
/var/run/kubernetes
# Install the worker binaries
mv crictl kube-proxy kubelet runc /usr/local/bin/
mv containerd containerd-shim-runc-v2 containerd-stress /bin/
mv cni-plugins/* /opt/cni/bin/
Pod 간 통신을 위한 브리지 네트워크를 구성하고, 리눅스 커널의 네트워크 필터링 기능을 활성화합니다.
# Install the CNI configuration files (Bridge & Loopback)
mv 10-bridge.conf 99-loopback.conf /etc/cni/net.d/
# Load and persist the kernel module
modprobe br-netfilter
echo "br-netfilter" >> /etc/modules-load.d/modules.conf
# Enable iptables processing for bridged traffic
echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.d/kubernetes.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
containerd, kubelet, kube-proxy의 설정 파일과 Systemd 유닛 파일을 경로에 배치하고, 데몬을 재시작합니다.
# Install the containerd configuration files
mkdir -p /etc/containerd/
mv containerd-config.toml /etc/containerd/config.toml
mv containerd.service /etc/systemd/system/
# Create the kubelet-config.yaml configuration file
mv kubelet-config.yaml /var/lib/kubelet/
mv kubelet.service /etc/systemd/system/
# Configure the Kubernetes Proxy
mv kube-proxy-config.yaml /var/lib/kube-proxy/
mv kube-proxy.service /etc/systemd/system/
# Start the Worker Services
systemctl daemon-reload
systemctl enable containerd kubelet kube-proxy
systemctl start containerd kubelet kube-proxy
정상적으로 수행되었다면 아래의 명령어로 상태를 확인할 수 있습니다.
# Check service status
systemctl status kubelet --no-pager
systemctl status containerd --no-pager
systemctl status kube-proxy --no-pager
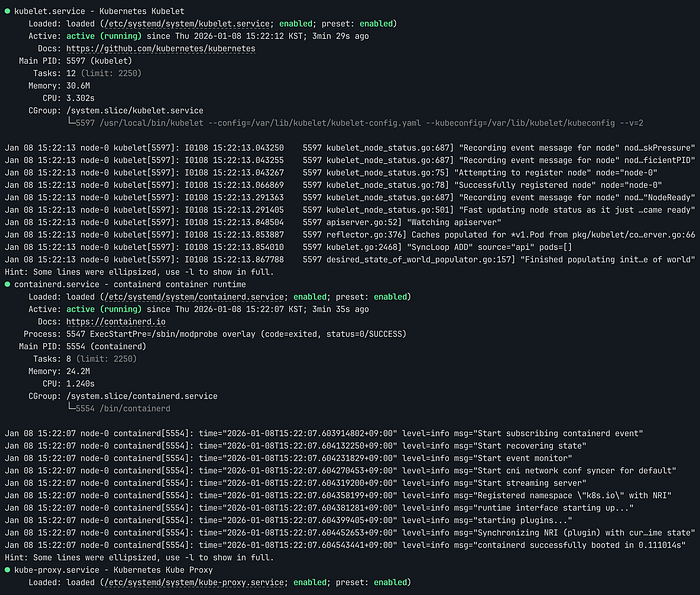 Worker Node 서비스 상태
Worker Node 서비스 상태
이 과정을 node-1에도 동일하게 반복해야 합니다.
Configuring kubectl for Remote Access
Control Plane과 Worker Node의 부트스트래핑이 완료되었다면, 이제 Jumpbox에서 클러스터를 원격 제어할 수 있도록 kubectl 도구를 설정해야 합니다. 이 과정은 클라이언트 인증서와 서버 정보를 ~/.kube/config 파일에 기록하여, 매번 인증 정보를 입력하지 않고도 클러스터 관리 명령을 수행할 수 있게 합니다.
설정을 시작하기 전, Jumpbox에서 원격 클러스터의 API 서버로 통신이 가능한지 확인합니다. 이전 실습에서 설정한 /etc/hosts의 DNS 항목을 통해 server.kubernetes.local 주소로 접근합니다.
curl -s --cacert ca.crt https://server.kubernetes.local:6443/version | jq
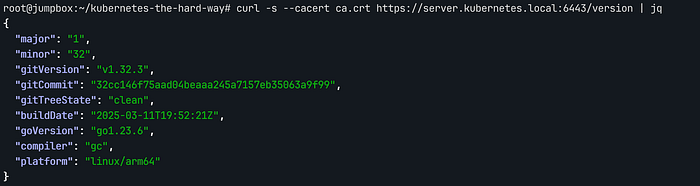 kubectl 원격 접속 확인
kubectl 원격 접속 확인
kubectl config 명령어를 사용하여 클러스터 정보, 사용자 인증 정보, 컨텍스트를 순차적으로 정의합니다.
# Configure cluster endpoint and CA certificate
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.crt \
--embed-certs=true \
--server=https://server.kubernetes.local:6443
# Configure admin user's client certificate and private key
kubectl config set-credentials admin \
--client-certificate=admin.crt \
--client-key=admin.key
# Set context
kubectl config set-context kubernetes-the-hard-way \
--cluster=kubernetes-the-hard-way \
--user=admin
# Switch context
kubectl config use-context kubernetes-the-hard-way
위 명령어들을 실행하면 kubectl 도구가 참조하는 기본 위치인 ~/.kube/config 파일이 생성되거나 업데이트됩니다.
Jumpbox에서 원격 클러스터의 리소스가 정상적으로 조회되는지 최종 검증합니다.
kubectl version
kubectl get nodes -o wide
 클러스터 노드 확인
클러스터 노드 확인
Provisioning Pod Network Routes
이 섹션에서는 각 노드의 Pod CIDR 대역 간 통신이 가능하도록 리눅스 커널 수준에서 정적 라우팅을 설정합니다.
현재 구성 중인 클러스터는 별도의 CNI 플러그인(BGP 등)이 자동으로 경로를 전파하지 않는 ‘Hard Way’ 방식이므로, 노드 간 포드 트래픽이 올바른 게이트웨이(각 노드의 IP)를 찾아갈 수 있도록 수동으로 경로를 지정해야 합니다.
먼저 machines.txt 파일에서 각 노드의 내부 IP와 서브넷 정보를 변수에 할당합니다.
SERVER_IP=$(grep server machines.txt | cut -d " " -f 1)
NODE_0_IP=$(grep node-0 machines.txt | cut -d " " -f 1)
NODE_0_SUBNET=$(grep node-0 machines.txt | cut -d " " -f 4)
NODE_1_IP=$(grep node-1 machines.txt | cut -d " " -f 1)
NODE_1_SUBNET=$(grep node-1 machines.txt | cut -d " " -f 4)
변수를 활용하여 각 노드의 커널 라우팅 테이블에 경로를 추가합니다.
# Configure routes on server
ssh root@server <<EOF
ip route add ${NODE_0_SUBNET} via ${NODE_0_IP}
ip route add ${NODE_1_SUBNET} via ${NODE_1_IP}
EOF
# Configure routes on node-0
ssh root@node-0 <<EOF
ip route add ${NODE_1_SUBNET} via ${NODE_1_IP}
EOF
# Configure routes on node-1
ssh root@node-1 <<EOF
ip route add ${NODE_0_SUBNET} via ${NODE_0_IP}
EOF
이로써 모든 구성을 완료하였습니다. 이후 Smoke Test를 통해 Deployments, Pod이 구동하는 것을 확인할 수 있습니다.
Comments