38 min to read
Kubespray HA Cluster: From Deployment to Disaster Recovery - 0
Cloudnet@ K8S Deploy — Week5
Overview
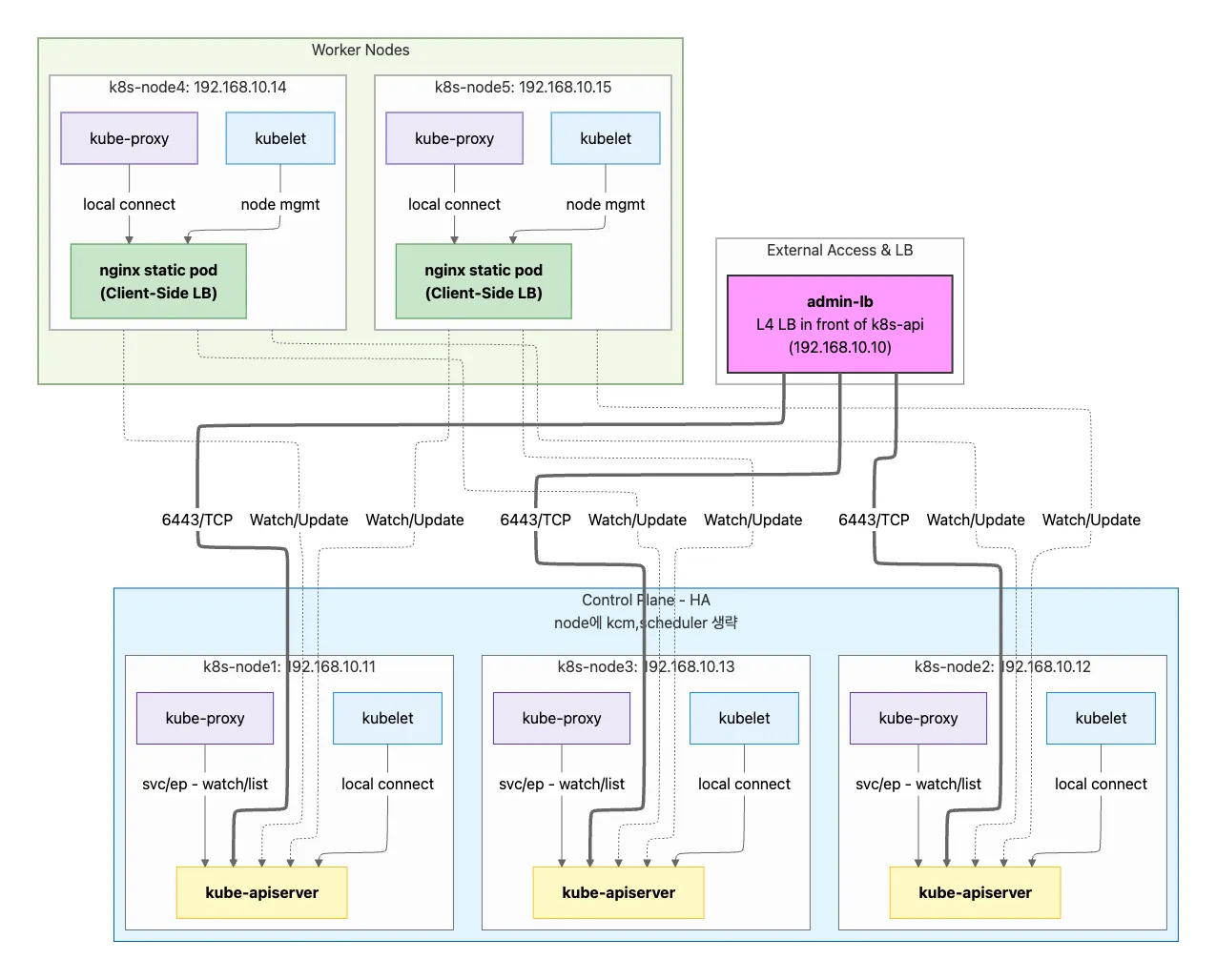
지금까지의 실습환경에서는 Control Plane 노드가 1개였지만 Kubespray를 활용한 Kubernetes 고가용성(HA) 클러스터 아키텍처는 이러한 단일 장애점(SPOF)을 제거하고 운영 중단 시간을 최소화하는 것을 핵심 목표로 합니다.
제공된 실습 환경에서는 3개의 Control Plane 노드와 2개의 Worker 노드로 구성된 HA 클러스터를 구축하며, 각 Control Plane 노드는 etcd 멤버로도 동작합니다.
이러한 환경에서 etcd cluster는 Control Plane과 동일한 노드에서 실행되며, 이는 리소스 효율성을 높이지만 노드 장애 시 etcd와 control plane 구성요소가 동시에 영향을받을 수 있다는 trade-off가 존재합니다.
아래의 이미지에서 볼 수 있듯이, Worker 노드에서는 nginx static pod를 통한 Client-Side Load Balancing이 구현되어 있으며, 이는 외부 LB(HAProxy)와 함께 사용하여 API Server 접근의 고가용성을 달성합니다.
 Architecture
Architecture
Control Plane & etcd HA
HA 아키텍처의 핵심은 etcd quorum 유지와 API Server Load Balancing입니다. etcd는 분산 key-value store로서 3-node cluster에서 최소 2개의 노드가 가동 중이어야 쓰기 연산을 수행할 수 있습니다.
Kubespray는 각 Control Plane 노드에 고유한 etcd_member_name(etcd1, etcd2, etcd3)을 할당하여 etcd membership을 구성하며, 이는 /etc/hosts파일과 inventory.ini의 hostvar를 통해 관리됩니다.
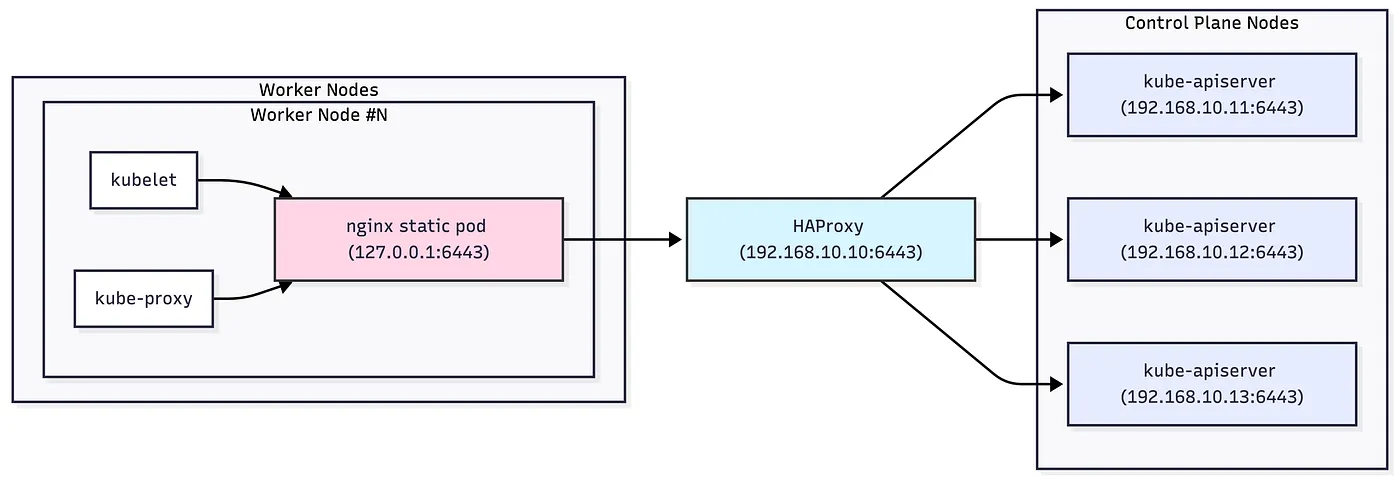
API Server는 각 Control Plane 노드에서 static pod로 실행되며, Worker 노드의 kubelet과 kube-proxy는 일반적으로 아래 중 하나의 Load Balancing모드를 통해 Control Plane 노드들의 API Server에 연결됩니다.
- Internal Loadbalancing: Worker Node의 nginx static pod가 Control Plane 노드들의 API Server에 연결됩니다.
- External Loadbalancing: HAProxy, kube-vip 등을 통해 API Server에 접근합니다.
실습 환경에서는 아래 이미지와 같이 두 경우 모두를 구성하여 확인합니다.
 Load Balancing
Load Balancing
Quorum & Rolling Upgrade
업그레이드 관점에서 HA 아키텍처는 rolling upgrade를 가능하게 합니다. etcd cluster는 Raft consensus algorithm을 사용하므로 한 번에 하나의 etcd 멤버만 업그레이드하면 quorum이 유지됩니다. Kubespray의 upgrade-cluster.ymlplaybook은 이러한 rolling upgrade를 자동화하며, Control Plane 구성요소(API Server, Controller Manager, Scheduler) 역시 순차적으로 업그레이드되어 서비스 가용성을 보장합니다. 그러나 실습 환경에서는 Worker 노드가 2개(k8s-node4, k8s-node5)로 설정되었으나 inventory-ini에서 k8s-node5가 주석처리되어 있어 실제로는 1-node Worker 구성으로 배포되었습니다. 이는 실습에서 노드를 추가하기 위함입니다.
etcd cluster는 Raft consensus algorithm을 사용하므로, quorum(N/2 + 1)의 노드가 가동 중이어야 쓰기 연산을 수행할 수 있습니다. 3-node cluster에서는 최소 2개의 노드가 가동 중이어야 합니다. 2개의 노드가 다운되면 quorum이 상실되어 쓰기 연산이 불가능하며, Kubernetes cluster는 새로운 object를 생성하거나 기존 object를 수정할 수 없습니다.
Lab Environment Setup with Vagrant
Vagrant와 VirtualBox를 활용하여 실습 환경이 구성됩니다. 실습 환경은 총 6개의 가상 머신으로 구성됩니다.
- admin-lb(HAProxy, Kubespray 실행)
- k8s-node1~3(Control Plane + etcd)
- k8s-node4~5(Worker)
각 VM은 Rocky Linux 10.0(bento/rockylinux-10.0)을 기반으로 하며, 2개의 네트워크 인터페이스를 가집니다. Host-only 네트워크는 VM 간 통신과 HAProxy를 통한 API Server 접근을 담당하며, NAT 네트워크는 외부 인터넷 접근(패키지 다운로드 등)을 위해 사용됩니다.
Vagrantfile 은 아래와 같습니다.
# Base Image https://portal.cloud.hashicorp.com/vagrant/discover/bento/rockylinux-10.0
BOX_IMAGE = "bento/rockylinux-10.0" # "bento/rockylinux-9"
BOX_VERSION = "202510.26.0"
N = 5 # max number of Node
Vagrant.configure("2") do |config|
# Nodes
(1..N).each do |i|
config.vm.define "k8s-node#{i}" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Kubespray-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "k8s-node#{i}"
vb.cpus = 4
vb.memory = 2048
vb.linked_clone = true
end
subconfig.vm.host_name = "k8s-node#{i}"
subconfig.vm.network "private_network", ip: "192.168.10.1#{i}"
subconfig.vm.network "forwarded_port", guest: 22, host: "6000#{i}", auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh", args: N.to_s
end
end
# Admin & LoadBalancer Node
config.vm.define "admin-lb" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Kubespray-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "admin-lb"
vb.cpus = 2
vb.memory = 1024
vb.linked_clone = true
end
subconfig.vm.host_name = "admin-lb"
subconfig.vm.network "private_network", ip: "192.168.10.10"
subconfig.vm.network "forwarded_port", guest: 22, host: "60000", auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "admin-lb.sh", args: N.to_s
end
end
실습 환경은 프로덕션 환경의 축소판이지만, 일부 제약이 존재합니다. VM의 리소스(2~4 CPU, 1~2GB RAM)는 실제 프로덕션 노드보다 제한적으로 적용하였습니다.
init_cfg.sh 는 아래와 같습니다.
#!/usr/bin/env bash
echo ">>>> Initial Config Start <<<<"
echo "[TASK 1] Change Timezone and Enable NTP"
timedatectl set-local-rtc 0
timedatectl set-timezone Asia/Seoul
echo "[TASK 2] Disable firewalld and selinux"
systemctl disable --now firewalld >/dev/null 2>&1
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
echo "[TASK 3] Disable and turn off SWAP & Delete swap partitions"
swapoff -a
sed -i '/swap/d' /etc/fstab
sfdisk --delete /dev/sda 2 >/dev/null 2>&1
partprobe /dev/sda >/dev/null 2>&1
echo "[TASK 4] Config kernel & module"
cat <<EOF >/etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
modprobe overlay >/dev/null 2>&1
modprobe br_netfilter >/dev/null 2>&1
cat <<EOF >/etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system >/dev/null 2>&1
echo "[TASK 5] Setting Local DNS Using Hosts file"
sed -i '/^127\.0\.\(1\|2\)\.1/d' /etc/hosts
echo "192.168.10.10 k8s-api-srv.admin-lb.com admin-lb" >>/etc/hosts
for ((i = 1; i <= $1; i++)); do echo "192.168.10.1$i k8s-node$i" >>/etc/hosts; done
echo "[TASK 6] Delete default routing - private NIC"
private_nic=$(nmcli -t -f DEVICE,TYPE device | awk -F: '$2=="ethernet" {print $1}' | grep enp0s | tail -1)
[ -n "$private_nic" ] && nmcli connection modify "$private_nic" ipv4.never-default yes
[ -n "$private_nic" ] && nmcli connection up "$private_nic" >/dev/null 2>&1
echo "[TASK 7] Setting SSHD"
echo "root:qwe123" | chpasswd
cat <<EOF >>/etc/ssh/sshd_config
PermitRootLogin yes
PasswordAuthentication yes
EOF
systemctl restart sshd >/dev/null 2>&1
echo "[TASK 8] Install packages"
dnf install -y git nfs-utils >/dev/null 2>&1
echo "[TASK 9] ETC"
echo "sudo su -" >>/home/vagrant/.bashrc
echo ">>>> Initial Config End <<<<"
admin-lb.sh 는 아래와 같습니다.
#!/usr/bin/env bash
echo ">>>> Initial Config Start <<<<"
echo "[TASK 1] Change Timezone and Enable NTP"
timedatectl set-local-rtc 0
timedatectl set-timezone Asia/Seoul
echo "[TASK 2] Disable firewalld and selinux"
systemctl disable --now firewalld >/dev/null 2>&1
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
echo "[TASK 3] Setting Local DNS Using Hosts file"
sed -i '/^127\.0\.\(1\|2\)\.1/d' /etc/hosts
echo "192.168.10.10 k8s-api-srv.admin-lb.com admin-lb" >>/etc/hosts
for ((i = 1; i <= $1; i++)); do echo "192.168.10.1$i k8s-node$i" >>/etc/hosts; done
echo "[TASK 4] Delete default routing - private NIC"
private_nic=$(nmcli -t -f DEVICE,TYPE device | awk -F: '$2=="ethernet" {print $1}' | grep enp0s | tail -1)
[ -n "$private_nic" ] && nmcli connection modify "$private_nic" ipv4.never-default yes
[ -n "$private_nic" ] && nmcli connection up "$private_nic" >/dev/null 2>&1
echo "[TASK 5] Install kubectl"
cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
exclude=kubectl
EOF
dnf install -y -q kubectl --disableexcludes=kubernetes >/dev/null 2>&1
echo "[TASK 6] Install HAProxy"
dnf install -y haproxy >/dev/null 2>&1
cat <<EOF >/etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
# utilize system-wide crypto-policies
ssl-default-bind-ciphers PROFILE=SYSTEM
ssl-default-server-ciphers PROFILE=SYSTEM
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option tcplog
option dontlognull
option http-server-close
#option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# ---------------------------------------------------------------------
# Kubernetes API Server Load Balancer Configuration
# ---------------------------------------------------------------------
frontend k8s-api
bind *:6443
mode tcp
option tcplog
default_backend k8s-api-backend
backend k8s-api-backend
mode tcp
option tcp-check
option log-health-checks
timeout client 3h
timeout server 3h
balance roundrobin
server k8s-node1 192.168.10.11:6443 check check-ssl verify none inter 10000
server k8s-node2 192.168.10.12:6443 check check-ssl verify none inter 10000
server k8s-node3 192.168.10.13:6443 check check-ssl verify none inter 10000
# ---------------------------------------------------------------------
# HAProxy Stats Dashboard - http://192.168.10.10:9000/haproxy_stats
# ---------------------------------------------------------------------
listen stats
bind *:9000
mode http
stats enable
stats uri /haproxy_stats
stats realm HAProxy\ Statistic
stats admin if TRUE
# ---------------------------------------------------------------------
# Configure the Prometheus exporter - curl http://192.168.10.10:8405/metrics
# ---------------------------------------------------------------------
frontend prometheus
bind *:8405
mode http
http-request use-service prometheus-exporter if { path /metrics }
no log
EOF
systemctl enable --now haproxy >/dev/null 2>&1
echo "[TASK 7] Install nfs-utils"
dnf install -y nfs-utils >/dev/null 2>&1
systemctl enable --now nfs-server >/dev/null 2>&1
mkdir -p /srv/nfs/share
chown nobody:nobody /srv/nfs/share
chmod 755 /srv/nfs/share
echo '/srv/nfs/share *(rw,async,no_root_squash,no_subtree_check)' >/etc/exports
exportfs -rav
echo "[TASK 8] Install packages"
dnf install -y python3-pip git sshpass >/dev/null 2>&1
echo "[TASK 9] Setting SSHD"
echo "root:qwe123" | chpasswd
cat <<EOF >>/etc/ssh/sshd_config
PermitRootLogin yes
PasswordAuthentication yes
EOF
systemctl restart sshd >/dev/null 2>&1
echo "[TASK 10] Setting SSH Key"
ssh-keygen -t rsa -N "" -f /root/.ssh/id_rsa >/dev/null 2>&1
sshpass -p 'qwe123' ssh-copy-id -o StrictHostKeyChecking=no root@192.168.10.10 >/dev/null 2>&1 # cat /root/.ssh/authorized_keys
for ((i = 1; i <= $1; i++)); do sshpass -p 'qwe123' ssh-copy-id -o StrictHostKeyChecking=no root@192.168.10.1$i >/dev/null 2>&1; done
ssh -o StrictHostKeyChecking=no root@admin-lb hostname >/dev/null 2>&1
for ((i = 1; i <= $1; i++)); do sshpass -p 'qwe123' ssh -o StrictHostKeyChecking=no root@k8s-node$i hostname >/dev/null 2>&1; done
echo "[TASK 11] Clone Kubespray Repository"
git clone -b v2.29.1 https://github.com/kubernetes-sigs/kubespray.git /root/kubespray >/dev/null 2>&1
cp -rfp /root/kubespray/inventory/sample /root/kubespray/inventory/mycluster
cat <<EOF >/root/kubespray/inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
#k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
EOF
echo "[TASK 12] Install Python Dependencies"
pip3 install -r /root/kubespray/requirements.txt >/dev/null 2>&1 # pip3 list
echo "[TASK 13] Install K9s"
CLI_ARCH=amd64
if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi
wget -P /tmp https://github.com/derailed/k9s/releases/latest/download/k9s_linux_${CLI_ARCH}.tar.gz >/dev/null 2>&1
tar -xzf /tmp/k9s_linux_${CLI_ARCH}.tar.gz -C /tmp
chown root:root /tmp/k9s
mv /tmp/k9s /usr/local/bin/
chmod +x /usr/local/bin/k9s
echo "[TASK 14] Install kubecolor"
dnf install -y -q 'dnf-command(config-manager)' >/dev/null 2>&1
dnf config-manager --add-repo https://kubecolor.github.io/packages/rpm/kubecolor.repo >/dev/null 2>&1
dnf install -y -q kubecolor >/dev/null 2>&1
echo "[TASK 15] Install Helm"
curl -fsSL https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | DESIRED_VERSION=v3.18.6 bash >/dev/null 2>&1
echo "[TASK 16] ETC"
echo "sudo su -" >>/home/vagrant/.bashrc
echo ">>>> Initial Config End <<<<"
HAProxy
HAProxy는 Kubernetes API Server의 고가용성을 담당하는 Layer 4 Load Balancer로, 모든 client 요청(Control Plane 노드의 kubelet/kube-proxy, Worker 노드의 kubelet, kube-proxy, kubectl)을 Control Plane 노드의 3개 API Server로 분산합니다.
Kubernetes API Server는 HTTPS endpoint를 제공하며, TLS termination을 직접 수행합니다. 따라서 HAProxy는 TCP mode로 설정하여 TLS passthrough를 수행해야 합니다. HTTP mode를 사용하면 HAProxy가 TLS connection을 검증하거나 HTTP request를 전송해야 하므로, self-signed 인증서를 사용하는 환경에서 문제가 발생할 수 있습니다.
따라서 admin-lb 노드(192.168.10.10)에서 실행되는 HAProxy는 TCP mode로 구성되어 있으며, LB는 TLS passthrough 역할만 수행하고 실제 인증서 검증은 API Server에서 이루어집니다.
frontend k8s-api
bind *:6443 # admin-lb의 6443 포트 listen
mode tcp # TCP mode (TLS passthrough)
option tcplog # TCP 연결 로그
default_backend k8s-api-backend
backend k8s-api-backend
mode tcp
option tcp-check # TCP 연결 검사
balance roundrobin # Round-robin load balancing
server k8s-node1 192.168.10.11:6443 check check-ssl verify none inter 10000
server k8s-node2 192.168.10.12:6443 check check-ssl verify none inter 10000
server k8s-node3 192.168.10.13:6443 check check-ssl verify none inter 10000
check-ssl verify none옵션은 HAProxy가 API Server의 TLS 연결을 검증하지만 서버 인증서를 검증하지 않음을 의미합니다. 이는 self-signed 인증서를 사용하는 테스트 환경에서 필요합니다. inter 10000은 health check 간격이 10초임을 나타내며, option tcp-check는 TCP 3-way handshake가 성공하면 healthy로 간주합니다.
- TCP 3-way Handshake: HAProxy가 API Server(192.168.10.11:6443)에 TCP 연결 시도
- Connection Establishment: SYN-ACK를 수신하면 healthy로 판단
- Health Check Interval: inter 10000 옵션으로 10초마다 반복
이는 Kubernetes API Server가 listen 중인 6443 포트에 TCP 연결이 가능하다면 healthy로 간주합니다. TLS handshake 과정은 client(kubectl, kubelet)가 API Server에 직접 수행합니다.
실습 환경 배포 초기에는 HAProxy 통계 페이지(http://192.168.10.10:9000/haproxy_stats)에서 모든 backend 서버가 DOWN 상태로 표시됩니다. 이는 API Server가 아직 배포되지 않았기 때문입니다. Kubespray 배포 완료 후, ss -tnlp \| grep haproxy 명령어로 HAProxy가 6443, 9000, 8405 포트를 listen 중인 것을 확인할 수 있습니다.
Kubespray Cluster Deployment
Kubespray는 Ansible playbook을 사용하여 Kubernetes 클러스터를 자동화된 방식으로 배포하며, 이는 수동으로 kubeadm을 실행하는 것보다 재현 가능하고 오류 가능성이 낮습니다.
cluster.yml playbook은 Control Plane 구성, etcd cluster 구성, Worker 노드 onboarding, CNI 플러그인 배포, addon(Metrics Server, CoreDNS) 설치 등의 전체 배포 과정을 순차적으로 수행합니다.
실습 환경에서는 /root/kubespray/inventory/mycluster 디렉토리에 inventory 파일과 group_vars를 구성하며, 이는 Ansible이 각 노드의 역할을 결정하고 적절한 role을 적용하는 데 사용됩니다.
노드의 역할을 아래와 같이 정의합니다.
Ansible inventory에서 :children 키워드는 그룹 상속을 의미합니다. [etcd:children] kube_control_plane 구문은 etcd 그룹이 kube_control_plane 그룹을 포함함을 나타냅니다. 즉, kube_control_plane 그룹에 속한 모든 호스트(k8s-node1, k8s-node2, k8s-node3)가 자동으로 etcd 그룹에도 속하게 됩니다.
[kube_control_plane]
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
#k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
Group_vars Customization
Kubernetes 클러스터의 초기 설정은 운영 환경의 안정성과 성능에 중요한 영향을 미칩니다. Kubespray는 기본적으로 안전한 설정을 제공하지만, 실습 환경에서는 테스트 및 학습 목적으로 일부 설정을 k8s-cluster/k8s-cluster.yml과 k8s-net-flannel.yml 파일을 통해 배포 설정을 커스터마이징했습니다.
# 컨테이너 runtime owner 변경 (kube → root)
sed -i 's|kube_owner: kube|kube_owner: root|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# CNI 플러그인 변경 (Calico → Flannel)
sed -i 's|kube_network_plugin: calico|kube_network_plugin: flannel|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# kube-proxy 모드 변경 (IPVS → iptables)
sed -i 's|kube_proxy_mode: ipvs|kube_proxy_mode: iptables|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# NodeLocal DNS 비활성화
sed -i 's|enable_nodelocaldns: true|enable_nodelocaldns: false|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
echo "enable_dns_autoscaler: false" >> inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# Flannel 네트워크 인터페이스 설정
echo "flannel_interface: enp0s9" >> inventory/mycluster/group_vars/k8s_cluster/k8s-net-flannel.yml
# Metrics Server 활성화 및 리소스 설정
sed -i 's|metrics_server_enabled: false|metrics_server_enabled: true|g' inventory/mycluster/group_vars/k8s_cluster/addons.yml
echo "metrics_server_requests_cpu: 25m" >> inventory/mycluster/group_vars/k8s_cluster/addons.yml
echo "metrics_server_requests_memory: 16Mi" >> inventory/mycluster/group_vars/k8s_cluster/addons.yml
Deployment
Ansible은 각 노드의 시스템 정보를 수집(facts gathering)하고 순차적으로 구성요소를 배포합니다.
ANSIBLE_FORCE_COLOR=true ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml -e kube_version="1.32.9" | tee kubespray_install.log
Kubespray는 local_release_dir: "/tmp/releases"를 통해 Kubernetes 바이너리를 다운로드하고 배포합니다. 각 노드는 /tmp/releases 디렉토리에서 kubelet, kubectl, etcdctl 등의 바이너리를 복사합니다.
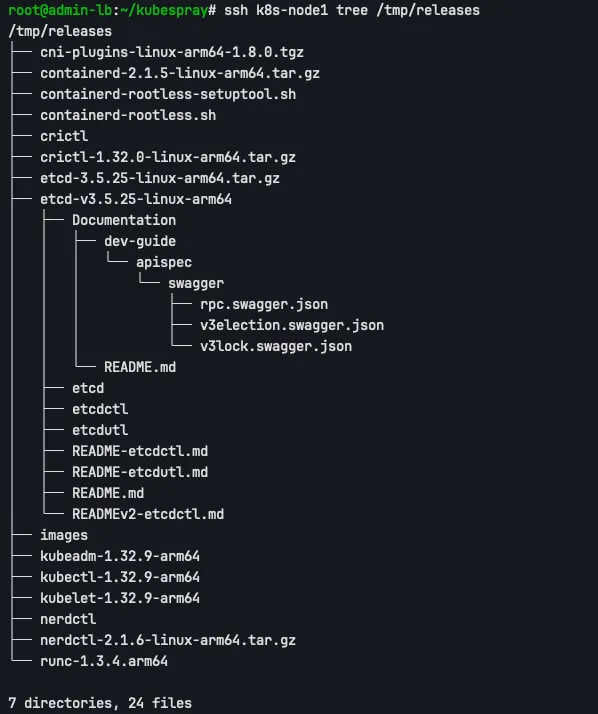 ssh k8s-node1 tree /tmp/releases
ssh k8s-node1 tree /tmp/releases
Kubespray는 각 노드의 kernel parameters를 /etc/sysctl.conf파일에 적용합니다.
ssh k8s-node1 grep "^[^#]" /etc/sysctl.conf
ssh k8s-node4 grep "^[^#]" /etc/sysctl.conf
etcd Cluster Configuration & Backup
etcd cluster는 Kubernetes의 state를 저장하는 핵심 구성요소입니다. Kubespray는 각 Control Plane 노드에 etcd를 설치하고 cluster를 구성합니다. 또한 /var/backups 디렉토리에 etcd 백업을 생성합니다.
# etcd 백업 확인
for i in {1..3}; do echo ">> k8s-node$i <<"; ssh k8s-node$i tree /var/backups; echo; done
Verification of HA Cluster Components
Kubespray 배포 완료 후, HA 클러스터의 각 구성요소가 올바르게 배포되었는지 검증합니다.
Control Plane 노드는 control-plane role과 node-role.kubernetes.io/control-plane:NoSchedule taint을 가집니다. 이는 Pod가 Control Plane 노드에 스케줄링되는 것을 방지합니다.
# Node 상태 확인
kubectl get node -owide
# Node taint 확인
kubectl describe node | grep -E 'Name:|Taints'
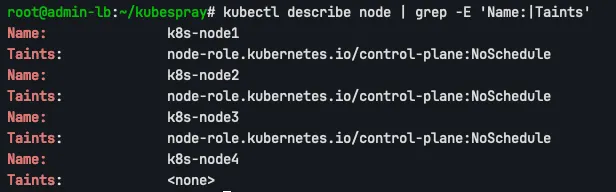 Taints
Taints
Control Plane Components Deep Dive
Control Plane 구성요소(kube-apiserver, kube-controller-manager, kube-scheduler)는 각각의 역할과 리더 선출(leader election) 메커니즘을 가집니다.
kube-apiserver
kube-apiserver는 Kubernetes cluster의 모든 REST API 요청을 처리합니다. HA 구성에서는 3개의 API Server가 각 Control Plane 노드에서 실행되며, HAProxy를 통한 load balancing을 통해 client 요청을 분산합니다.
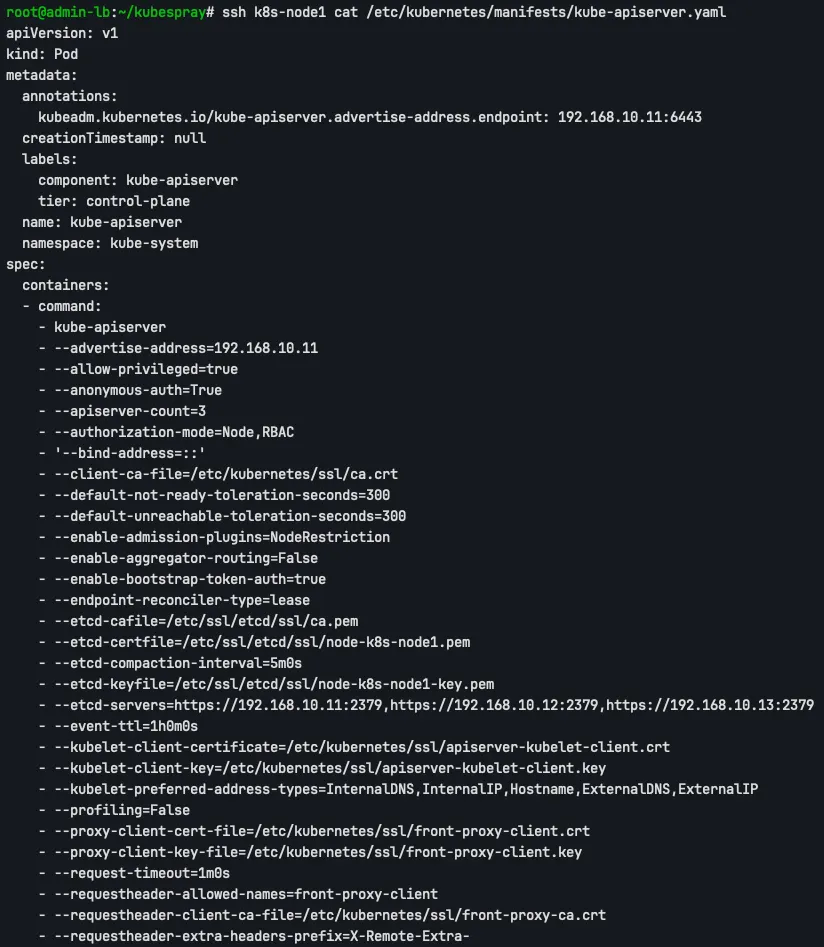 ssh k8s-node1 cat /etc/kubernetes/manifests/kube-apiserver.yaml
ssh k8s-node1 cat /etc/kubernetes/manifests/kube-apiserver.yaml
- advertise-address: API Server가 알린 IP 주소입니다.
- apiserver-count=3: cluster의 API Server 개수입니다.
- etcd-servers: etcd cluster의 endpoint 리스트입니다. kubeadm 직접 설치 시 https://127.0.0.1:2379를 사용하는 것과 달리, Kubespray는 모든 etcd endpoint를 명시합니다.
etcd는 분산 key-value store로서 Kubernetes의 state를 저장합니다. Kubespray HA Mode 문서에 따르면 etcd clients(kube-api-masters)는 모든 etcd peers 리스트로 구성되므로, etcd cluster가 여러 인스턴스를 가지면 이미 HA로 구성됩니다.
The etcd clients (kube-api-masters) are configured with list of all etcd peers. If etcd-cluster has multiple instances, it’s configured in HA already
Leader Election
kube-controller-manager와 kube-scheduler는 active-passive 모드로 작동하며, 리더 선출(leader election)을 통해 하나의 인스턴스만 활성 상태(active)로 동작합니다. 리더는 Kubernetes API Server의 Lease resource를 통해 선출됩니다.
 kubectl get lease -n kube-system
kubectl get lease -n kube-system
- kube-apiserver: 모든 인스턴스가 Active로 동작합니다. 각 인스턴스는 독립적으로 요청을 처리하며, etcd를 통해 consistency를 보장합니다.
- kube-controller-manager: 리더 하나만 Active로 동작하며, ReplicaSet, Deployment, Namespace 등의 controller를 실행합니다.
- kube-scheduler: 리더 하나만 Active로 동작하며, Pod를 Node에 스케줄링합니다.
kube-controller-manager
kube-controller-manager는 cluster의 control loop를 담당하며, Node Controller, Replication Controller, Endpoint Controller 등을 실행합니다.
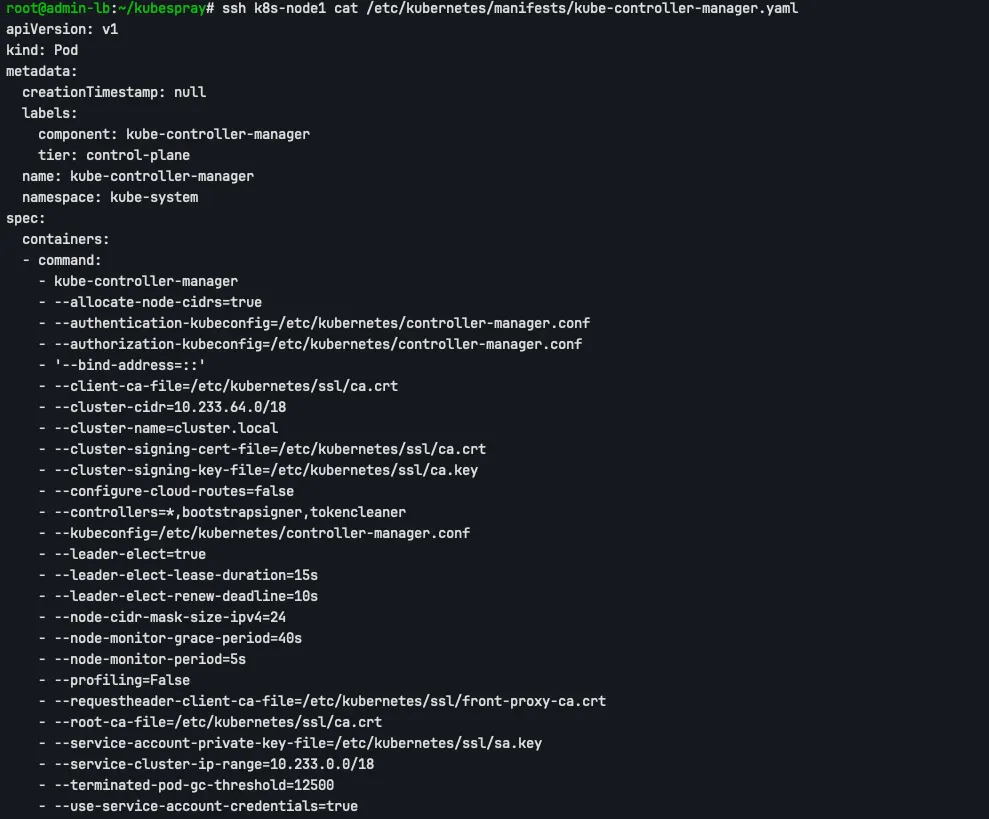 ssh k8s-node1 cat /etc/kubernetes/manifests/kube-controller-manager.yaml
ssh k8s-node1 cat /etc/kubernetes/manifests/kube-controller-manager.yaml
- bind-address: : 모든 주소에서 listen합니다.
- allocate-node-cidrs=true: Node Controller가 각 Node에 Pod CIDR을 할당합니다.
- cluster-cidr=10.233.64.0/18: 전체 Pod CIDR 대역입니다.
- node-cidr-mask-size-ipv4=24: 각 Node에 할당되는 Pod CIDR의 마스크 크기입니다. /18 대역에서 /24 크기로 분할하면 최대 64개의 Node를 지원할 수 있습니다.
- service-cluster-ip-range=10.233.0.0/18: Service ClusterIP 대역입니다.
- leader-elect=true: 리더 선출을 활성화합니다.
Certificate
Kubernetes cluster는 각 구성요소 간의 통신을 위한 인증서를 사용합니다. kubeadm은 기본적으로 1년 유효기간의 인증서를 생성하며, Kubespray는 caCertificateValidityPeriod: 87600h0m0s(10년), certificateValidityPeriod: 8760h0m0s(1년)으로 설정합니다.
# 인증서 정보 확인: ctrl1번 노드만 super-admin.conf 확인
for i in {1..3}; do echo ">> k8s-node$i <<"; ssh k8s-node$i ls -l /etc/kubernetes/super-admin.conf ; echo; done
# 인증서 만료 확인
for i in {1..3}; do echo ">> k8s-node$i <<"; ssh k8s-node$i kubeadm certs check-expiration ; echo; done
super-admin.conf는 k8s-node1에만 존재합니다. 이는 Kubespray가 첫 번째 Control Plane 노드에만 관리자 인증서를 생성하기 때문입니다. 인증서 만료 확인은 업그레이드 전 인증서 갱신 필요성을 판단하는 데 사용됩니다.
Kubespray Variable Precedence
Kubespray는 Ansible을 기반으로 하므로, Ansible의 variable precedence 규칙을 따릅니다. 이 우선순위 구조는 설정의 유연함을 제공하지만, 올바르게 이해하지 않으면 예상치 못한 동작을 유발할 수 있습니다.
- Command-line values (예:
-u my_user) → 가장 낮은 우선순위 - Role defaults (
role/*/defaults/main.yml) → role 기본값 - Inventory file or script group vars → inventory 파일의 그룹 변수
- Inventory group_vars/all (
inventory/mycluster/group_vars/all/*.yml) - Playbook group_vars/all → playbook의 group_vars/all
- Inventory group_vars/* (
inventory/mycluster/group_vars/k8s_cluster/*.yml) - Playbook group_vars/* → playbook의 group_vars
- Inventory file or script host vars → inventory 파일의 호스트 변수
- Inventory host_vars/* (
inventory/mycluster/host_vars/<node>.yml) - Playbook host_vars/* → playbook의 host_vars
- Host facts and cached set_facts → 호스트 facts
- Play vars → playbook의 vars
- Play vars_prompt → playbook의 vars_prompt
- Play vars_files → playbook의 vars_files
- Role vars (
role/*/vars/main.yml) → role 내부 강제 변수 - Block vars → block 내부의 vars
- Task vars → task 내부의 vars
- include_vars → include_vars로 로드한 변수
- Registered vars and set_facts → 등록된 변수 및 set_facts
- Role (and include_role) params → role 매개변수
- include params → include 매개변수
- Extra vars (
-e) → 가장 높은 우선순위
Kubespray에서의 변수 우선순위 구조는 아래와 같습니다.
 Kubespray Variable
Kubespray Variable
Kubespray는 Role Defaults의 기본값을 Inventory Scope에서 오버라이드하는 구조입니다.
- inventory/mycluster/group_vars/all/*.yml
- inventory/mycluster/group_vars/k8s_cluster/*.yml
- inventory/mycluster/group_vars/etcd.yml
특정 노드 하나에만 적용되는 설정이 필요하다면, Host Vars로 오버라이드 할 수 있습니다.
업그레이드 호환성을 위해 Role Scope 내의 roles/*/vars 내부는 수정하지 않고, 모든 변경사항은 inventory/ 디렉토리 내에서 설정되는 것이 권장됩니다.
Kubespray 변수의 선언 위치와 사용 위치를 검색하려면 아래의 명령어를 수행할 수 있습니다.
# 특정 변수 선언 및 사용 검색
grep -Rn "allow_unsupported_distribution_setup" inventory/mycluster/ playbooks/ roles/ -A1 -B1
# dns autoscaler 변수 검색
grep -Rni "autoscaler" inventory/mycluster/ playbooks/ roles/ --include="*.yml" -A2 -B1
Load Balancing
Kubernetes 고가용성(HA) 구성을 위해, 클러스터 내 여러 kube-apiserver 인스턴스에 대한 안정적인 접근 경로는 필수 요소로 Kubernetes의 주요 구성 요소들(kubelet, kube-proxy 등)은 단일 엔드포인트를 통해 apiserver에 접근하도록 설계되어 있으며, 이를 위해 Reverse Proxy 기반의 Load Balancer가 필요합니다.
Localhost(internal) LoadBalancing
Kubespray의 HA 모드에서는 각 Worker 노드마다 nginx 기반의 reverse proxy가 배포됩니다. 이 프록시는 일반적으로 Static Pod 형태로 실행되며, Worker 노드의 localhost 주소(예: 127.0.0.1)를 통해 kube-apiserver 요청을 수신합니다.
“Kubespray includes support for an nginx-based proxy that resides on each non-master Kubernetes node. This is referred to as localhost loadbalancing. It is less efficient than a dedicated load balancer because it creates extra health checks on Kubernetes apiserver, but is more practical for scenarios where an external LB or virtual IP management is inconvenient.”
실습 환경에서는 loadbalancer_apiserver_localhost가 기본값(True)이므로, Worker Node(k8s-node4)에 nginx static pod가 배포됩니다.
# nginx static pod 확인
ssh k8s-node4 crictl ps
# nginx configuration 확인
ssh k8s-node4 cat /etc/nginx/nginx.conf
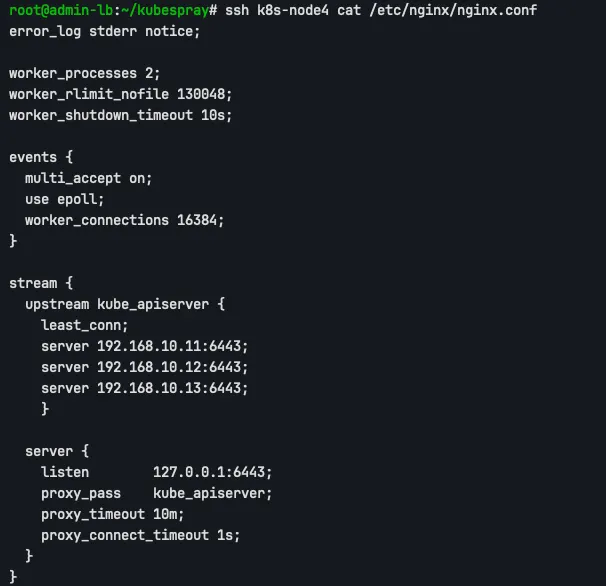 nginx.conf
nginx.conf
nginx는 127.0.0.1:6443을 listen하고, least_conn 알고리즘을 사용하여 Control Plane 노드들의 API Server로 트래픽을 분산합니다.
least_conn은 현재 연결 수가 가장 적은 서버로 요청을 분배합니다. Kubernetes API Server는 watch, streaming, exec 등의 기능으로 인해 다수의 long-lived connection을 사용합니다. 이러한 환경에서는 요청 수 기반 분산 방식(round-robin)보다, 현재 활성 연결 수를 기준으로 분산하는 least_conn 방식이 부하 분산에 더 적합합니다.
long-lived connection은 한 번 연결을 맺은 뒤 짧게 끝나지 않고 오랫동안 유지되는 네트워크 연결
nginx configuration에서는 worker_rlimit_nofile을 130048로 설정하지만, containerd는 OCI spec에 정의된 rlimit(65535)을 따르므로, nginx가 원하는 worker_rlimit_nofile(130048)을 설정할 수 없습니다. 따라서 아래와 같이 alert가 발생하게 됩니다.
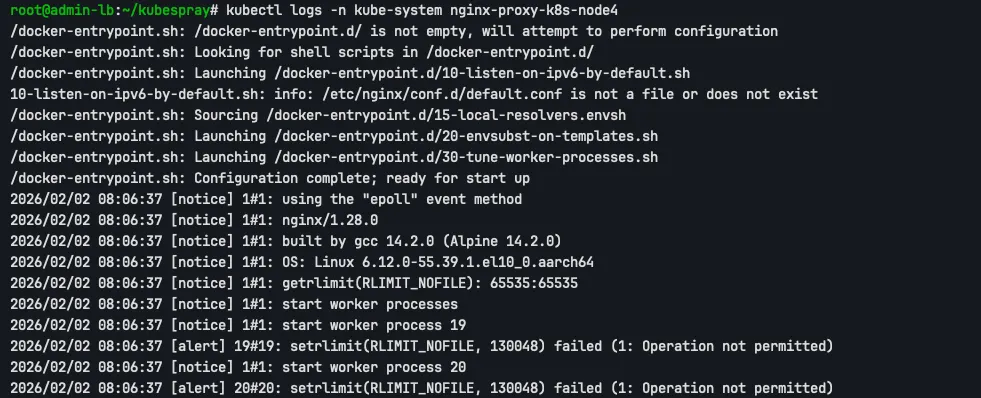 kubectl logs -n kube-system nginx-proxy-k8s-node4
kubectl logs -n kube-system nginx-proxy-k8s-node4
alert 해결을 위해 containerd의 OCI spec rlimit 제한을 제거하여 nginx가 원하는 RLIMIT_NOFILE을 설정할 수 있게 합니다. rlimit 리스트를 비우면, containerd가 default rlimit을 적용하지 않고 container가 rlimit을 자유롭게 설정할 수 있게 합니다.
# 기본 OCI Spec(Runtime Spec)을 수정(Patch)
cat << EOF >> inventory/mycluster/group_vars/all/containerd.yml
containerd_default_base_runtime_spec_patch:
process:
rlimits: []
EOF
# containerd role 재실행 (k8s-node4만)
ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml --tags "containerd" --limit k8s-node4 -e kube_version="1.32.9"
적용을 위해서 ssh k8s-node4 내부에서 컨테이너를 재시작시킵니다.
crictl pods --namespace kube-system --name 'nginx-proxy-*' -q | xargs crictl rmp -f
kube-apiserver는 --bind-address=:: 로 설정되어 모든 네트워크 인터페이스에서 listen합니다. 따라서 Control Plane 노드의 모든 IP 주소로 접근 가능합니다.
Control Plane의 kubelet, kube-proxy 등 로컬 구성요소는 kubeconfig에서 127.0.0.1:6443으로 설정되어 있어 localhost를 통해 접근합니다. 이는 kube-apiserver가 static pod로 같은 노드에서 실행되고 있기 때문에 가능합니다.
따라서 Control Plane 노드 하나가 다운되면, 해당 노드의 구성요소도 함께 다운되므로 Control Plane의 경우에는 Internal LoadBalancing이 의미가 없습니다.
# kube-apiserver bind-address 확인
kubectl describe pod -n kube-system kube-apiserver-k8s-node1 | grep -E 'address|secure-port'
# kube-apiserver listen 확인
ssh k8s-node1 ss -tnlp | grep 6443
# API Server 호출 확인 (multiple interfaces)
ssh k8s-node1 curl -sk https://127.0.0.1:6443/version | grep gitVersion
ssh k8s-node1 curl -sk https://192.168.10.11:6443/version | grep gitVersion
ssh k8s-node1 curl -sk https://10.0.2.15:6443/version | grep gitVersion
같은 Control Plane 노드 내부에서는 localhost, 클러스터 네트워크 IP, NAT IP 등 어떤 주소로 접근해도 kube-apiserver가 응답합니다. 하지만 다른 노드에서 접근할 때는 네트워크 라우팅이 가능한 IP로만 연결할 수 있습니다.
External LoadBalancing
Localhost Load Balancing은 각 Worker Node에 nginx 기반 reverse proxy를 배포하여 kube-apiserver 접근을 분산하는 방식으로 외부 인프라 의존성을 최소화한다는 장점이 있으나, 다음과 같은 구조적 한계를 가집니다.
- 각 Worker Node마다 nginx static pod가 배포되므로, 클러스터 규모가 확장될수록 proxy 인스턴스 수가 선형적으로 증가합니다.
- 각 Worker Node의 nginx는 kube-apiserver에 대해 독립적으로 health check를 수행하기 때문에 Worker Node 수가 많아질수록 동일한 health check 요청이 반복적으로 발생합니다. 결과적으로 Control Plane(API Server)에 부하를 유발할 수 있습니다.
- nginx proxy 설정은 모든 Worker Node에 분산 배포되기 때문에 설정 변경이나 정책 수정 등의 작업이 필요한 경우 노드 단위로 관리가 필요합니다.
장애 상황을 기반으로 왜 External LB가 필요한지 확인해보겠습니다. 먼저 k8s-node1을 장애시키고 Worker Node의 nginx LB 동작을 확인합니다.
# [admin-lb] kubeconfig 자격증명 사용 시 정보 확인
cat /root/.kube/config | grep server
# 모니터링
while true; do curl -sk https://192.168.10.12:6443/version | grep gitVersion ; sleep 1; echo ; done
 context
context
admin-lb는 kubectl 실행 시, k8s-node1로 직접 접근합니다. VirtualBox에서 테스트를 위해 임시로 k8s-node1을 Power Off합니다.
 Power Off
Power Off
이후 Worker Node의 nginx LB 로그를 확인해보면 nginx가 health check를 수행하며, k8s-node1이 다운된 것을 감지하고 제외합니다. 즉 nginx가 자동으로 node1을 upstream pool에서 일시적으로 제외하여 자동으로 FailOver됩니다.
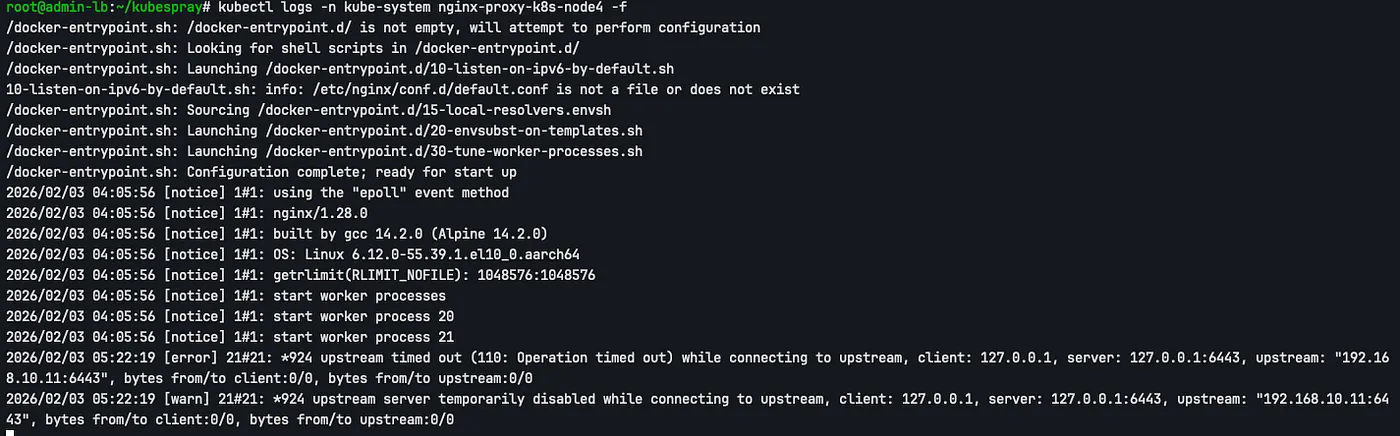 kubectl logs -n kube-system nginx-proxy-k8s-node4 -f
kubectl logs -n kube-system nginx-proxy-k8s-node4 -f
Worker Node의 API의 호출을 확인해보면 k8s-node2, k8s-node3로 트래픽을 전송하므로, API 호출이 정상입니다.
admin-lb에서는 kubeconfig의 server 주소를 장애가 발생하지 않은 Control Plane 노드로 수정하면 API 호출이 정상적으로 성공하는 것을 확인할 수 있습니다.
# [k8s-node4] 백엔드 대상 서버가 나머지 2대가 있으니 아래 요청 처리 정상
while true; do curl -sk https://127.0.0.1:6443/version | grep gitVersion ; date; sleep 1; echo ; done
# kubeconfig를 node2만 가리키도록 수정
sed -i 's/192.168.10.11/192.168.10.12/g' /root/.kube/config
# [admin-lb] 서버 정보 수정 필요
while true; do kubectl get node ; echo ; curl -sk https://192.168.10.12:6443/version | grep gitVersion ; sleep 1; echo ; done
k8s-node1이 NotReady 상태로 변경된 것을 확인할 수 있습니다. 하지만 2개의 Control Plane 노드가 Ready 상태이므로, quorum이 유지되고 API Server가 정상 작동합니다.
 kubectl get nodes -o wide
kubectl get nodes -o wide
다시 VirtualBox에서 k8s-node1을 작동시키면 Ready 상태로 원복합니다.
이를 통해 알 수 있던 점은 Internal LB가 있으면 Worker 통신은 내부적으로 HA를 보장한다는 것입니다. 하지만 External LB가 없는 경우에는 외부 접근 시 HA가 보장되지 않으며, 특정 노드가 Down된 경우 수동으로 kubeconfig를 수정해야 합니다.
External Load Balancer 방식은 kube-apiserver 앞단에 Dedicated Load Balancer 또는 EntryPoint(Virtual IP a.k.a. VIP)를 배치하는 구조입니다.
따라서 Dedicated Load Balancer가 모든 요청을 처리하므로, Worker Node 수 증가와 무관하게 proxy 관련 리소스 오버헤드가 최소화됩니다.
이러한 방식들은 일반적으로 아래 두 가지 방식의 솔루션을 사용합니다.
1. kube-vip
kube-vip은 VIP 관리와 Load Balancing을 하나의 Static Pod로 통합한 Kubernetes native 솔루션입니다. Control Plane Node에 Static Pod 형태로 배포되며, IPVS(IP Virtual Server)를 활용한 커널 레벨 Load Balancing을 제공합니다.
2. HAProxy + Keepalived
HAProxy는 TCP Layer 4 Load Balancing을 담당하고, Keepalived는 VRRP 프로토콜을 통해 VIP를 관리하는 조합입니다. 별도 노드 또는 Control Plane Node에 Static Pod로 배포하며, Keepalived의 health check script가 HAProxy 상태를 모니터링하여 VIP를 Active/Standby 구조로 관리합니다.
Scenarios
Internal / External Load Balancing을 다양한 환경에서 구축해보고 어떻게 작동하는지 확인해보도록 합니다.
이를 위해 먼저 실습을 위한 환경을 구성합니다.
kube-ops-view는 Kubernetes cluster의 시각화 도구로서, cluster 상태를 모니터링하는 데 사용됩니다.
# helm repo 추가
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
# macOS 사용자
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 \
--set service.main.type=NodePort,service.main.ports.http.nodePort=30000 \
--set env.TZ="Asia/Seoul" --namespace kube-system \
--set image.repository="abihf/kube-ops-view" --set image.tag="latest"
# 배포 확인
kubectl get deploy,pod,svc,ep -n kube-system -l app.kubernetes.io/instance=kube-ops-view
# kube-ops-view 접속 URL 확인
open "http://192.168.10.14:30000/#scale=1.5"
webpod 애플리케이션을 배포하여 API Server의 load balancing을 테스트합니다.
# 샘플 애플리케이션 배포
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: webpod
spec:
replicas: 2
selector:
matchLabels:
app: webpod
template:
metadata:
labels:
app: webpod
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- sample-app
topologyKey: "kubernetes.io/hostname"
containers:
- name: webpod
image: traefik/whoami
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: webpod
labels:
app: webpod
spec:
selector:
app: webpod
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30003
type: NodePort
EOF
# 배포 확인
kubectl get deploy,svc,ep webpod -o wide
Control Plane Node에서 DNS resolution을 테스트합니다.
ssh k8s-node1 cat /etc/resolv.conf
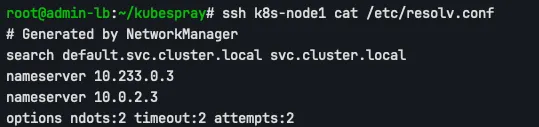 ssh k8s-node1 cat /etc/resolv.conf
ssh k8s-node1 cat /etc/resolv.conf
ndots:2 설정은 최소 2개의 dot을 포함한 domain 이름만 쿼리를 수행합니다.
# 성공: FQDN
ssh k8s-node1 curl -s webpod -I
# 성공: default namespace
ssh k8s-node1 curl -s webpod.default -I
# 실패: webpod.default.svc (svc만, ndots=3 이상 필요)
ssh k8s-node1 curl -s webpod.default.svc -I
# 성공: webpod.default.svc.cluster.local (cluster.local search)
ssh k8s-node1 curl -s webpod.default.svc.cluster.local -I
External LB + Worker Client-Side LoadBalancing
실습 시나리오는 다음과 같습니다.
- External LB: admin-lb 노드의 HAProxy(192.168.10.10:6443)
- Control Plane: 3-node HA cluster (k8s-node1~3)
- Worker Node: Client-Side LB(nginx static pod) 유지
External LB(HAProxy)를 사용하여 API Server에 접근하려면, API Server 인증서에 LB 주소가 포함되어야 합니다.
# External LB를 통한 API Server 호출
curl -sk https://192.168.10.10:6443/version | grep gitVersion
# kubeconfig를 External LB 주소로 수정
sed -i 's/192.168.10.12/192.168.10.10/g' /root/.kube/config
kubectl get node 호출 시, API Server 인증서(apiserver.crt)는 192.168.10.10(HAProxy 주소)를 포함하지 않으므로, TLS handshake가 실패합니다.
이는 인증서의 SAN으로도 확인할 수 있습니다.
# 인증서 SAN list 확인
ssh k8s-node1 kubectl get cm -n kube-system kubeadm-config -o yaml
# 인증서에 SAN 정보 확인
ssh k8s-node1 cat /etc/kubernetes/ssl/apiserver.crt | openssl x509 -text -noout
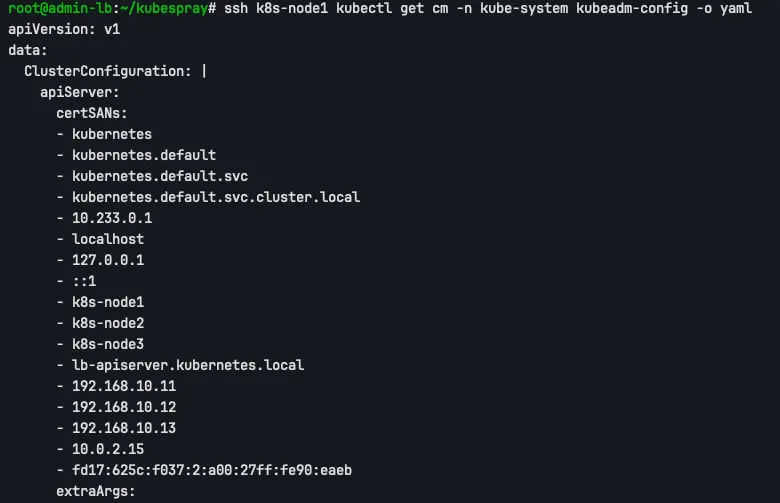 SAN
SAN
Kubespray는 supplementary_address_in_ssl_keys 변수를 통해 인증서 SAN에 추가 주소를 포함합니다.
# 인증서 SAN 에 'IP, Domain' 추가
echo "supplementary_addresses_in_ssl_keys: [192.168.10.10, k8s-api-srv.admin-lb.com]" >> inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
grep "^[^#]" inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
--tags "control-plane"을 사용하여 API Server 인증서를 갱신합니다.
# API Server 인증서 재생성
ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml --tags "control-plane" --limit kube_control_plane -e kube_version="1.32.9"
이는 Kubespray의 roles/kubernetes/control-plane/tasks/kubeadm-setup.yml에서 아래 로직을 통해 처리됩니다.
# roles/kubernetes/control-plane/tasks/kubeadm-setup.yml
- name: Kubeadm | aggregate all SANs
set_fact:
apiserver_sans: "{{ (sans_base + groups['kube_control_plane'] + sans_lb + sans_lb_ip + sans_supp + sans_access_ip + sans_ip + sans_ipv4_address + sans_ipv6_address + sans_override + sans_hostname + sans_fqdn + sans_kube_vip_address) | unique }}"
vars:
sans_base:
- "kubernetes"
- "kubernetes.default"
- "kubernetes.default.svc"
- "kubernetes.default.svc.{{ dns_domain }}"
- "{{ kube_apiserver_ip }}"
- "localhost"
- "127.0.0.1"
- "::1"
sans_lb: "{{ [apiserver_loadbalancer_domain_name] if apiserver_loadbalancer_domain_name is defined else [] }}"
sans_lb_ip: "{{ [loadbalancer_apiserver.address] if loadbalancer_apiserver is defined and loadbalancer_apiserver.address is defined else [] }}"
sans_supp: "{{ supplementary_addresses_in_ssl_keys if supplementary_addresses_in_ssl_keys is defined else [] }}"
sans_supp 변수가 supplementary_address_in_ssl_keys를 참조하며, 이 값이 최종 apiserver_sans 리스트에 병합됩니다. 이 리스트는 kubeadm의 ClusterConfiguration에서 certSANs 필드로 전달되며, kubeadm init phase certs apiserver 명령어가 이를 사용해 인증서를 생성합니다.
이후 상태를 확인해보면 정상적으로 조회가 되는 것을 확인할 수 있습니다.
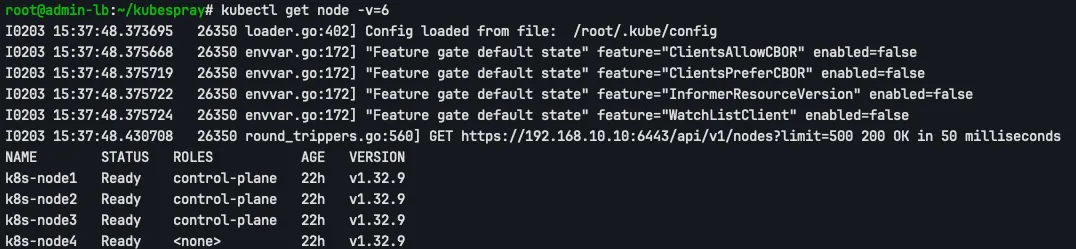 kubectl get node -v=6
kubectl get node -v=6
인증서에도 추가된 것을 확인할 수 있습니다.
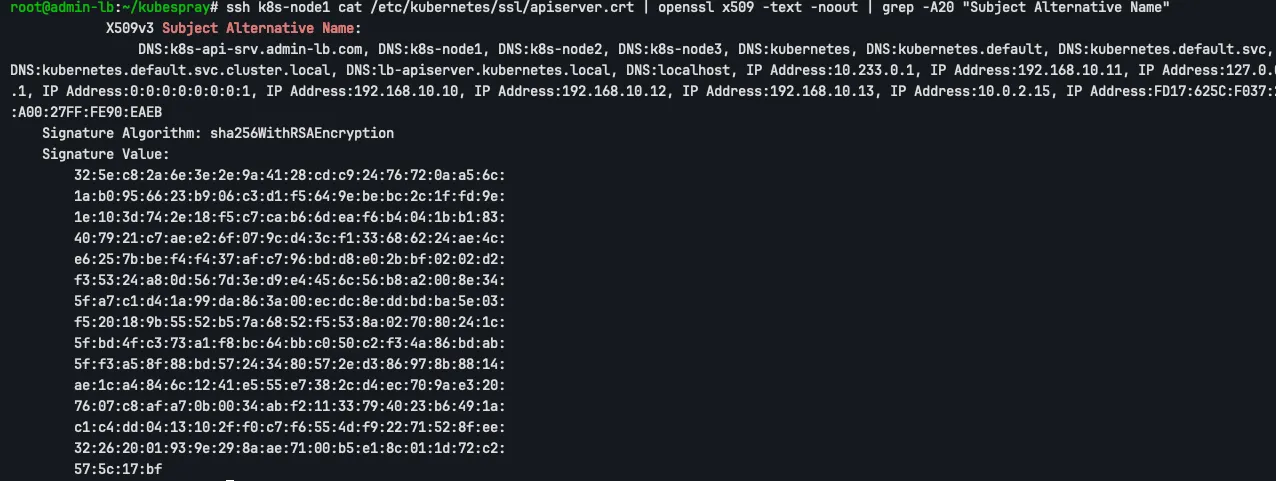 ssh k8s-node1 cat /etc/kubernetes/ssl/apiserver.crt | openssl x509 -text -noout | grep -A20 “Subject Alternative Name”
ssh k8s-node1 cat /etc/kubernetes/ssl/apiserver.crt | openssl x509 -text -noout | grep -A20 “Subject Alternative Name”
인증서 SAN에 도메인 이름(k8s-api-srv.admin-lb.com)이 포함되었으므로, kubeconfig를 FQDN으로 수정합니다. FQDN을 사용하면 IP가 변경되더라도 인증서 갱신 없이 계속 사용할 수 있습니다.
# ip, domain 둘 다 확인
sed -i 's/192.168.10.10/k8s-api-srv.admin-lb.com/g' /root/.kube/config
External LB Single Endpoint
이번 실습에서는 모든 노드가 External LB 단일 엔드포인트를 사용하도록 전환하며, 이 과정에서 Kubespray의 loadbalancer_apiserver_localhost 변수가 어떻게 nginx-proxy 배포를 제어하고, kubeconfig 생성 로직을 변경하는지 확인하도록 하겠습니다.
Kubernetes API Server는 TLS를 통해 모든 통신을 암호화하며, 클라이언트(kubelet, kube-proxy, kubectl 등)는 API Server가 제시한 인증서의 Subject Alternative Name(SAN) 필드를 검증하여 중간자 공격(Man-in-the-Middle Attack)을 방지합니다. SAN 필드는 인증서가 유효한 도메인 이름 또는 IP 주소를 나열하며, 클라이언트가 접근하는 엔드포인트가 이 목록에 포함되지 않으면 TLS 검증이 실패하게 됩니다.
TLS Handshake 과정에서의 SAN 검증
- 클라이언트 요청: kubelet이 https://k8s-api-srv.admin-lb.com:6443/api/v1/nodes 에 요청을 보냅니다.
- 인증서 제시: API Server가
/etc/kubernetes/pki/apiserver.crt인증서를 클라이언트에게 전송합니다. - SAN 검증: kubelet의 TLS 라이브러리(Go의
crypto/tls)가 인증서의 SAN 필드에 “k8s-api-srv.admin-lb.com”이 포함되어 있는지 확인합니다. - 검증 실패 : SAN에 해당 도메인이 없으면, 오류가 발생하게 됩니다.
RFC 2818(HTTP Over TLS) 및 RFC 6125(TLS Certificate Validation)에서는 CN 필드를 deprecated하고 SAN을 표준으로 권장하고 있습니다. CN은 단일 값만 가질 수 있지만, SAN은 여러 도메인과 IP를 포함할 수 있어 HA 환경에 적합합니다. Kubernetes API Server는 여러 엔드포인트(각 Control Plane 노드 IP, LoadBalancer IP, 서비스 FQDN 등)에서 접근 가능하므로, SAN을 통해 모든 경로를 인증서에 포함시킨다.
kubeadm은 클러스터 초기화 시 사용된 설정을 kube-system 네임스페이스의 kubeadm-config ConfigMap에 저장합니다. 이 ConfigMap에는 인증서 SAN 목록이 포함되어 있지 않지만, ClusterConfiguration의 apiServer.certSANs 필드를 확인할 수 있습니다.
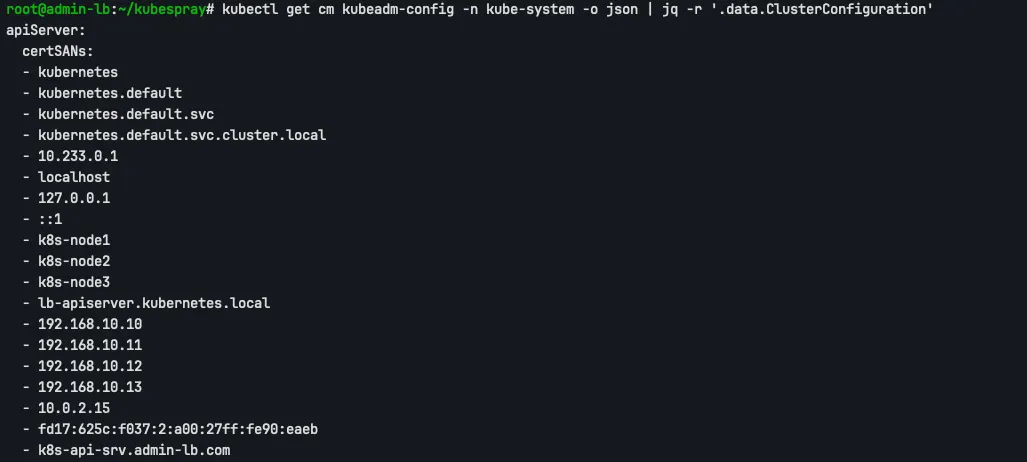 kubectl get cm kubeadm-config -n kube-system -o json | jq -r ‘.data.ClusterConfiguration’
kubectl get cm kubeadm-config -n kube-system -o json | jq -r ‘.data.ClusterConfiguration’
단, kubeadm-config ConfigMap은 초기 배포 시 생성된 후 자동으로 업데이트되지 않으므로, 최신 상태를 반영하지 않을 수 있습니다. 따라서 실제 인증서 파일을 직접 검사하는 것이 더 정확합니다.
openssl 명령어를 사용하여 /etc/kubernetes/pki/apiserver.crt 의 SAN 필드를 확인합니다.
ssh k8s-node1 "openssl x509 -in /etc/kubernetes/ssl/apiserver.crt -text -noout | grep -A20 'Subject Alternative Name'"
k8s-api-srv.admin-lb.com과 192.168.10.10이 포함되어 있으면, 이전 실습이 성공적으로 완료된 것으로 간주할 수 있습니다.
단일 External LB구조로 전환하기 위해서는 Kubespray의 loadbalancer_apiserver_localhost 변수를 false로 설정해야 합니다. 이 변수는 Kubespray 내 Worker Node의 nginx-proxy 배포 여부와 kubeconfig의 server필드 값을 결정합니다.
이를 위해 아래 설정을 추가합니다.
# false 적용
cat << EOF >> inventory/mycluster/group_vars/all/all.yml
apiserver_loadbalancer_domain_name: "k8s-api-srv.admin-lb.com"
loadbalancer_apiserver:
address: 192.168.10.10
port: 6443
loadbalancer_apiserver_localhost: false # Client-Side LB 미사용, 즉 kubelet/kube-proxy 도 External LB(HAProxy) 단일 사용
EOF
# roles/kubespray_defaults/defaults/main/main.yml 내 기본값 확인
loadbalancer_apiserver_localhost: "{{ loadbalancer_apiserver is not defined }}"
이에 따라 배포 시, kube_apiserver_endpoint 는 아래 로직으로 계산됩니다.
kube_apiserver_endpoint: |-
{% if loadbalancer_apiserver is defined -%}
https://{{ apiserver_loadbalancer_domain_name }}:{{ loadbalancer_apiserver.port | default(kube_apiserver_port) }}
{%- elif ('kube_control_plane' not in group_names) and loadbalancer_apiserver_localhost -%}
https://localhost:{{ loadbalancer_apiserver_port | default(kube_apiserver_port) }}
{%- elif 'kube_control_plane' in group_names -%}
https://{{ kube_apiserver_bind_address | regex_replace('::', '127.0.0.1') | ansible.utils.ipwrap }}:{{ kube_apiserver_port }}
{%- else -%}
https://{{ first_kube_control_plane_address | ansible.utils.ipwrap }}:{{ kube_apiserver_port }}
{%- endif %}
| Condition | Endpoint | Applied To |
|---|---|---|
| loadbalancer_apiserver가 정의된 경우 | https://k8s-api-srv.admin-lb.com:6443 | 모든 노드의 kubelet, kube-proxy, kubectl |
| loadbalancer_apiserver_localhost가 true이면서 kube_control_plane 그룹에 속하지 않는 경우 (Worker 노드) |
https://localhost:6443 | Worker 노드의 nginx-proxy → Control Plane API Server로 전달 |
| kube_control_plane 그룹에 속하는 경우 (Control Plane 노드) |
https://127.0.0.1:6443 | Control Plane 노드의 kubelet (로컬 API Server) |
| 그 외의 경우 (fallback) | https://192.168.10.11:6443 | 첫 번째 Control Plane 노드로 직접 접속 |
구성을 적용하기 위해 Kubespray Playbook을 실행하면, Control Plane과 Worker Node에서 각각 다른 변경 사항이 발생합니다. 이를 위해서는 3가지 Role이 필요합니다.
| Role | 작업 내용 |
|---|---|
| Control Plane (kubernetes/control-plane) | • kubeadm_config_api_fqdn 설정 • kubeadm-config.yaml의 controlPlaneEndpoint를 External LB로 변경 • External LB를 참조하는 /etc/kubernetes/admin.conf 생성 |
| Client (kubernetes/client) | • /etc/kubernetes/admin.conf를 /root/.kube/config로 복사 |
| Kubeadm (kubernetes/kubeadm) | • Worker Node의 /etc/kubernetes/kubelet.conf 업데이트 • kube-proxy ConfigMap 업데이트 • kube-proxy Pod 재시작 |
따라서 이를 위한 최소 태그는 control-plane, client, kubeadm이 필요합니다.
# control-plane + client + kubeadm 태그만 실행
ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml --tags "control-plane,client,kubeadm" -e kube_version="1.32.9"
Playbook 실행 후, Worker Node의 kubelet이 External LB를 참조하는지 확인합니다.
# Kubelet.conf 확인
ssh k8s-node4 "cat /etc/kubernetes/kubelet.conf | grep server"
# kube-proxy ConfigMap 확인
kubectl get cm -n kube-system kube-proxy -o yaml | grep 'kubeconfig.conf:' -A18 | grep server
하지만 nginx-proxy는 여전히 실행중으로 이 역시 삭제가 필요합니다.
# 1. Static Pod manifest 삭제
ansible -i inventory/mycluster/inventory.ini kube_node -m shell -a "rm -f /etc/kubernetes/manifests/nginx-proxy.yml"
# 2. 10초 대기 (kubelet이 자동으로 Pod 종료 및 제거)
sleep 10
# 3. 제거 확인
ansible -i inventory/mycluster/inventory.ini kube_node -m shell -a "crictl ps | grep nginx-proxy || echo 'nginx-proxy removed'"
실행이 완료되었다면 모든 Control Plane 노드에서 kubectl이 External LB를 참조하는지 확인합니다.
for i in {1..3}; do echo ">> k8s-node$i <<"; ssh k8s-node$i kubectl cluster-info -v=6; echo; done
이후, 관리 노드(admin-lb)에서 kubectl을 사용하려면 Control Plane 노드에서 kubeconfig를 복사해야 합니다.
# admin-lb에서 실행
mkdir -p /root/.kube
scp k8s-node1:/root/.kube/config /root/.kube/
cat /root/.kube/config | grep server
로그에서 GET https://k8s-api-srv.admin-lb.com:6443을 확인할 수 있으면, admin-lb가 External LB를 통해 API Server에 접근하는 것입니다.
 kubectl get node -owide -v=6
kubectl get node -owide -v=6
Comments