22 min to read
Sparse Computation and Memory Management for Efficient LLM Inference
Introduction
이전 글에서는 MQA, GQA, FlashAttention을 통해 Attention 메커니즘의 메모리와 연산 병목을 어떻게 해결하는지 살펴봤습니다. Attention 쪽 비용이 줄어들고 나면, LLM 추론에서 비중이 커지는 다른 두 병목이 보입니다.
하나는 FFN(Feed-Forward Network) 레이어의 파라미터와 연산량입니다. Transformer 한 블록에서 Attention의 $Q, K, V, O$ 선형 변환은 $4d^2$의 파라미터를 차지하는 반면, FFN은 $W_1 \in \mathbb{R}^{d \times 4d}$와 $W_2 \in \mathbb{R}^{4d \times d}$로 약 $8d^2$를 차지합니다. 즉 블록 파라미터의 약 2/3가 FFN이며, LLaMA 3 70B처럼 dense하게 설계된 대형 모델에서는 전체 파라미터에서 FFN이 차지하는 비중이 80% 이상으로 올라갑니다.
다른 하나는 KV Cache 메모리의 공간 낭비입니다. 이전 글에서 KV Cache가 시퀀스 길이에 선형 비례하여 커진다는 점을 다뤘는데, 실제 프로덕션 환경에서는 그 안에서 추가적인 낭비가 발생합니다. SOSP 2023에서 발표된 vLLM 논문(Kwon et al.)은 기존 LLM 서빙 시스템에서 실제 토큰을 저장하는 데 사용되는 KV Cache 메모리가 전체 할당량의 20.4 ~ 38.2% 수준이라고 측정했습니다. 나머지 60% 이상은 메모리 단편화로 인해 사용되지 못한 채 남아 있다는 의미입니다.
이 두 병목을 각각 다루는 기법이 Mixture of Experts(MoE)와 PagedAttention(vLLM)입니다. 본 글에서는 두 기법이 제안된 논문을 차례로 살펴보며, 수식과 아키텍처, 그리고 실제 모델 수치까지 정리해보겠습니다.
이 글에서 다루는 기법은 이전 글의 MQA, GQA, FlashAttention과 서로 다른 축을 공략합니다. MoE는 모델 아키텍처 차원에서, PagedAttention은 서빙 시스템 차원에서 작동하며, Attention 메커니즘 자체의 최적화와는 성격이 다릅니다. 현대 프로덕션 스택에서는 이 기법들이 함께 조합되어 사용됩니다.
Background: Why FFN Becomes the Next Bottleneck
MoE 이야기를 본격적으로 시작하기 전에, 왜 FFN이 다음 최적화 대상이 되는지 짚어보겠습니다. Hidden dimension을 $d$, 시퀀스 길이를 $N$이라 할 때, Transformer 한 블록의 연산 비용은 다음과 같이 정리됩니다 (행렬곱 leading-order 기준, bias와 LayerNorm 같은 부수항은 생략).
| 구성 요소 | 곱셈 대상 | 파라미터 수 | 토큰당 FLOPs |
|---|---|---|---|
| Attention 선형 변환 | 입력 × 가중치 ($W_Q, W_K, W_V, W_O$) | $4d^2$ | $8d^2$ |
| Attention Score/Output | 텐서 × 텐서 ($QK^\top$, $\cdot V$) | 0 | $4Nd$ |
| FFN | 입력 × 가중치 ($W_1 \in \mathbb{R}^{d \times 4d}$, $W_2 \in \mathbb{R}^{4d \times d}$) | $8d^2$ | $16d^2$ |
표의 첫 행과 셋째 행은 입력을 학습된 가중치 행렬과 곱하는 연산이고, 둘째 행은 입력에서 만들어진 텐서끼리 곱하는 Attention 메커니즘의 핵심 연산입니다. 둘째 행만 학습 파라미터가 없고 시퀀스 길이 $N$에 비례합니다.
FFN은 블록 전체 파라미터의 약 2/3를 차지하고, 토큰당 FLOPs도 Attention 선형 변환의 2배입니다. Score/Output 항은 $N$에 비례하지만 Decode 단계에서는 $N$이 작아, 결국 FFN이 토큰당 연산의 대부분을 차지합니다. 따라서 GQA로 KV 헤드를 줄이고 FlashAttention으로 HBM 왕복을 줄여도, FFN을 손대지 않으면 더 가속할 여지가 줄어듭니다.
MoE의 핵심 아이디어는 단순합니다. FFN을 $N$개의 전문가(Expert)로 늘리되, 각 토큰마다 그중 $k$개($k \ll N$)만 활성화하는 것입니다. 그러면 총 파라미터 수는 늘어나 모델 용량(capacity)이 커지지만, 토큰당 실제 연산량은 작은 모델 수준으로 유지됩니다.
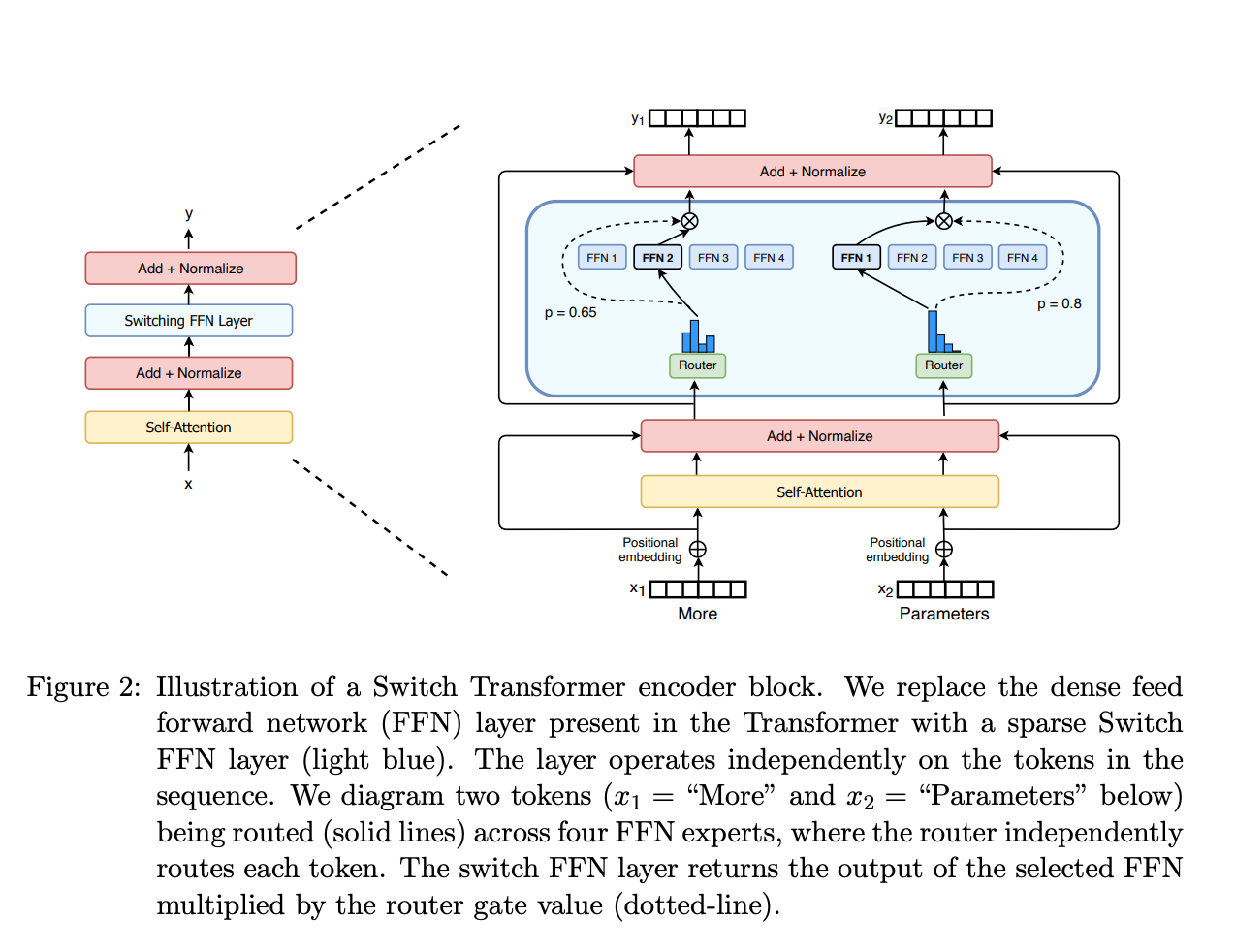 Switch Transformer의 MoE 레이어 구조 (https://huggingface.co/blog/moe)
Switch Transformer의 MoE 레이어 구조 (https://huggingface.co/blog/moe)
Sparsely-Gated MoE
ICLR 2017의 Outrageously Large Neural Networks 논문에서 Shazeer 등은 LSTM 사이에 최대 137억 파라미터의 MoE 레이어를 끼워 넣었습니다. 그 결과 모델 용량은 1000배 이상 늘었지만, 토큰당 연산량은 비슷한 수준으로 유지되었습니다.
작동 방식은 간단합니다. MoE 레이어 안에는 전문가 $E_1, E_2, \ldots, E_N$이 있고, 그 위에 어떤 전문가를 쓸지 결정하는 작은 신경망인 라우터(Router) 또는 게이팅 함수(Gating function) $G$가 있습니다. 입력 토큰 $x$가 들어오면 라우터가 각 전문가에 대해 가중치 $G(x)_i$를 계산하고, 출력은 그 가중합으로 만들어집니다.
\[y = \sum_{i=1}^{N} G(x)_i \cdot E_i(x)\]여기서 핵심은 $G(x)_i = 0$인 전문가는 아예 계산하지 않는다는 점입니다. 즉 $N$개 중 가중치가 0이 아닌 일부 전문가만 forward pass에 참여하므로, 전문가 수가 늘어나도 토큰당 실제 연산량은 작게 유지됩니다.
그렇다면 라우터는 어떻게 일부 전문가만 골라낼까요? Shazeer 등은 Noisy Top-K Gating이라는 방법을 제안했습니다. 이름 그대로 노이즈를 더한 뒤 상위 $k$개만 남기는 방식이며, 세 단계로 나누어 보면 직관이 잡힙니다.
1단계. 각 전문가에 대한 점수 계산
\[s_{i} = (x W_g)_{i}\]그냥 일반적인 Linear 레이어입니다. $W_g$는 $d \times N$ 크기의 학습 가능한 가중치이고, 입력 $x$를 $N$차원으로 변환하면 각 차원이 전문가 $i$의 점수 $s_i$가 됩니다. 여기까지는 평범한 분류기와 똑같습니다. $x$가 어느 전문가에 가야 할지를 점수로 매기는 단계입니다.
2단계. 점수에 노이즈 추가
\[H(x)_{i} = (x W_g)_{i} + \mathcal{N}(0, 1) \cdot \mathrm{Softplus}((x W_{\mathrm{noise}})_{i})\]원래 점수에 가우시안 노이즈를 더하되, 노이즈의 크기 자체도 별도 가중치 $W_{\text{noise}}$로 학습합니다. 핵심은 모델이 라우팅 결정을 얼마나 확률적으로 둘지를 스스로 조절한다는 점입니다. 노이즈는 학습 초기에 라우터가 특정 전문가에 고착되지 않도록 탐색을 유도하고, 부하 균형에도 기여합니다.
3단계. 상위 K개만 남기고 softmax
\[G(x) = \mathrm{Softmax}(\mathrm{KeepTopK}(H(x), k))\]KeepTopK는 단순한 마스킹 함수입니다. 점수 $H(x)$ 중 상위 $k$개만 그대로 두고 나머지는 음의 무한대($-\infty$)로 만듭니다. 그 다음 softmax를 취하면 $-\infty$였던 값들은 자동으로 0이 되어, 정확히 $k$개만 0이 아닌 값으로 살아남습니다. 이렇게 만들어진 $G(x)$가 1단계 가중합의 가중치가 되고, 0이 아닌 $k$개의 전문가만 실제로 계산됩니다.
마지막으로 한 가지 디테일이 있습니다. 저자들은 $k$를 1이 아니라 최소 2 이상으로 두어야 한다고 설명합니다. $k=1$이면 라우터는 선택한 전문가의 출력 한 가지만 보게 되어, 다른 전문가를 골랐다면 결과가 더 좋았을지를 비교할 수 없습니다. 즉 라우터의 가중치를 어떻게 조정해야 할지에 대한 학습 신호가 끊깁니다. 두 전문가를 동시에 활용해야 라우터에 의미 있는 그래디언트가 흐른다는 것이 논문의 설명입니다 (이 제약을 뒤에서 살펴볼 Switch Transformer가 다른 방식으로 뒤집습니다).
GShard and Switch Transformer
Shazeer의 원형이 LSTM 기반이었다면, GShard(2020)와 Switch Transformer(2021)가 이를 Transformer에 이식하면서 현대 MoE의 뼈대를 만들었습니다. 두 논문이 도입한 핵심 변경 세 가지를 차례로 정리합니다.
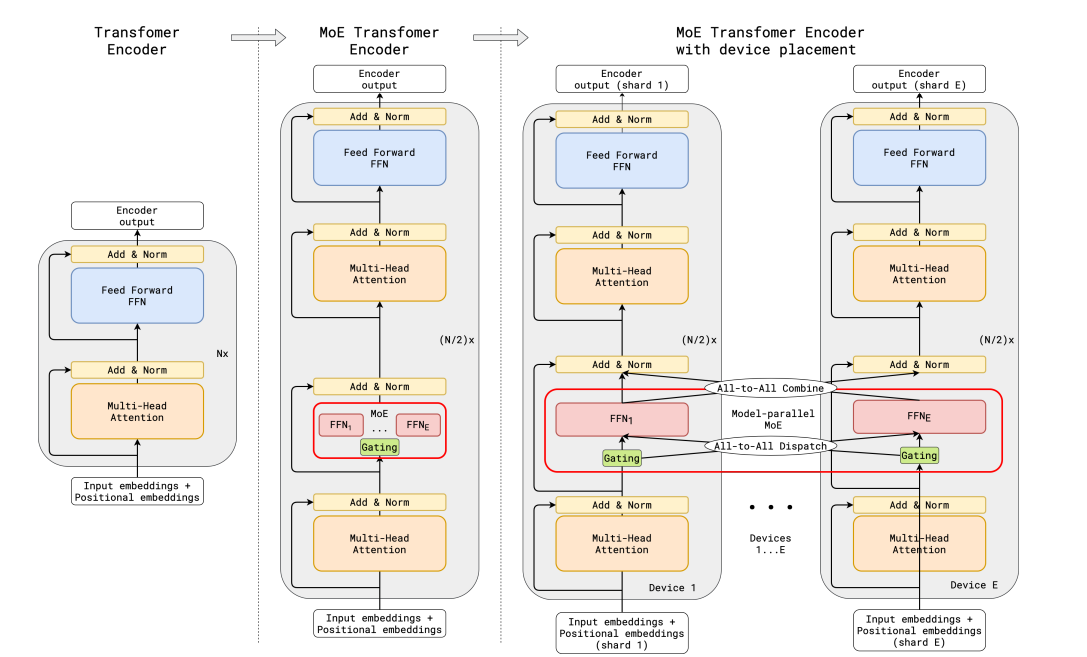 GShard의 MoE Transformer 인코더 구조. 블록 두 개당 한 번씩 FFN이 MoE 레이어로 치환됩니다. (https://huggingface.co/blog/moe)
GShard의 MoE Transformer 인코더 구조. 블록 두 개당 한 번씩 FFN이 MoE 레이어로 치환됩니다. (https://huggingface.co/blog/moe)
1. MoE 레이어 배치와 Expert Capacity (GShard)
GShard는 모든 블록이 아니라 한 칸 건너 FFN을 MoE로 교체했습니다. 동시에 Expert Capacity 개념을 도입해, 한 전문가가 한 배치에서 받을 수 있는 토큰의 최대 개수 $C = \lceil T/N \rceil \cdot \text{capacity_factor}$를 미리 정해둡니다. 어떤 전문가가 이미 $C$개의 토큰을 받았는데 또 토큰이 라우팅되면, 그 토큰은 해당 전문가를 건너뛰고 residual connection으로 우회합니다. 텐서 컴파일러가 각 전문가의 입력 텐서 크기를 컴파일 타임에 고정해야 하기 때문에 도입된 메커니즘입니다.
2. Top-1 라우팅 (Switch Transformer)
GShard가 Top-2 라우팅을 유지한 반면, Switch Transformer는 Top-1으로 단순화해도 품질이 유지된다는 것을 보였습니다. 동일 FLOPs/token 기준 T5 대비 7배의 사전학습 속도 향상을 달성했습니다.
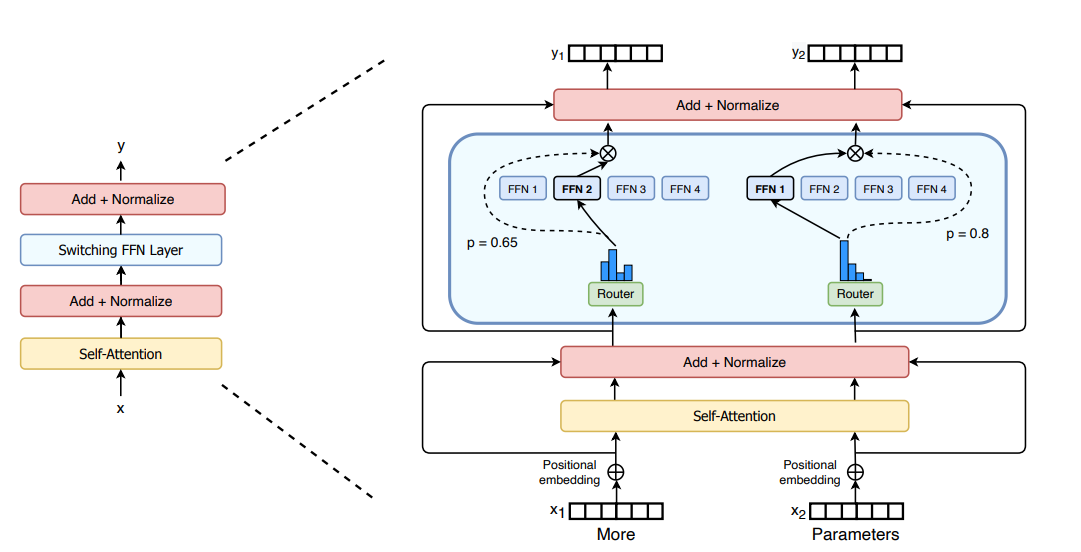 Switch Transformer 레이어. 각 토큰이 단 하나의 전문가로만 라우팅됩니다. (https://huggingface.co/blog/moe)
Switch Transformer 레이어. 각 토큰이 단 하나의 전문가로만 라우팅됩니다. (https://huggingface.co/blog/moe)
3. Load Balancing Loss (Switch Transformer)
Top-1 라우팅에서는 부하 불균형 문제가 특히 심각합니다. 특정 전문가에 토큰이 몰리기 시작하면, 그 전문가만 학습이 잘 되어 출력 품질이 올라가고, 그러면 라우터는 더 강하게 그 전문가를 선택하게 되는 악순환이 발생합니다. 결국 수십~수백 개의 전문가 중 1~2개만 쓰이고 나머지는 유휴 상태가 되어 MoE를 도입한 의미가 사라집니다.
Switch Transformer는 이 문제를 보조 손실(auxiliary loss)로 완화합니다. 한 전문가에 토큰이 몰릴수록 손실이 커지도록 만들어, 학습 과정에서 라우터가 자연스럽게 균등 분배 쪽으로 유도되는 방식입니다.
\[\mathcal{L}_{\text{aux}} = \alpha \cdot N \cdot \sum_{i=1}^{N} f_i \cdot P_i\]이 손실은 불균형을 서로 다른 두 가지 방식으로 측정한 뒤 곱하는 구조입니다. 먼저 $f_i$는 배치 안에서 전문가 $i$로 실제 라우팅된 토큰의 비율입니다.
\[f_i = \frac{1}{T} \sum_{x \in \mathcal{B}} \mathbb{1}\{\arg\max p(x) = i\}\]예를 들어 배치에 토큰이 1000개, 전문가가 8명일 때 $E_2$가 600개의 토큰을 받았다면 $f_2 = 0.60$입니다. 균등하다면 모두 $1/8 = 0.125$여야 하므로 큰 불균형이죠.
반면 $P_i$는 라우터가 배치 내 모든 토큰에 대해 매긴 전문가 $i$의 softmax 확률을 평균한 값입니다.
\[P_i = \frac{1}{T} \sum_{x \in \mathcal{B}} p_i(x)\]각 토큰에 대해 라우터가 전문가별 확률을 매기는데(예: $E_1$에 0.05, $E_2$에 0.70, …), 이를 배치 전체에서 평균낸 값입니다. $P_2 = 0.55$라면 라우터가 평균적으로 $E_2$를 가장 선호한다는 뜻입니다.
두 값의 성격이 다릅니다. $f_i$는 argmax로 어떤 전문가에 갔는지를 세는 결과로, 이산적이라 미분이 불가능합니다. $P_i$는 라우터가 각 전문가를 얼마나 선호하는지를 나타내는 의도로, 연속적이라 미분이 가능합니다. 균등 상태에서는 둘 다 $1/N$이고, 불균형이면 둘 다 한쪽으로 쏠립니다.
$f_i$만으로도 불균형을 측정할 수 있으니 $P_i$를 곱할 필요가 없어 보입니다. 하지만 $f_i$는 argmax에 기반한 지시함수라 미분이 불가능합니다. 즉 학습 신호를 보낼 수 없습니다. 그래서 $f_i$는 단순히 가중치로만 쓰고, 그래디언트는 미분 가능한 $P_i$를 통해서만 흐르게 합니다. 실제 구현에서도 $f_i$에 해당하는 항을 명시적으로 detach()해 gradient를 끊습니다.
$P_i$에 대해 미분하면 $\frac{\partial \mathcal{L}_{\text{aux}}}{\partial P_i} = \alpha N \cdot f_i$가 됩니다. 즉 전문가 $i$에 라우팅된 토큰이 많을수록($f_i$가 클수록), 그 전문가의 라우터 확률 $P_i$를 줄이는 그래디언트가 강해집니다. 반대로 $f_i$가 작은 전문가는 그래디언트가 약해서 softmax 정규화에 의해 상대적으로 확률이 올라갑니다. 결과적으로 토큰이 몰린 전문가는 라우터 확률이 줄어들고, 다른 전문가는 확률이 올라가는 피드백 루프가 만들어집니다.
수식 앞에 곱해진 $N$은 스케일 정규화를 위한 것입니다. 완벽한 균등 상태($f_i = P_i = 1/N$)에서 $\sum_i f_i \cdot P_i$를 계산하면 $N \cdot (1/N)^2 = 1/N$이 되어, 전문가 수가 많아질수록 손실값이 작아 보입니다.
그러면 $\alpha$ 튜닝이 $N$에 의존하게 됩니다. 따라서 앞에 $N$을 곱하면 균등 상태의 손실값이 항상 1로 고정되어, 같은 $\alpha$를 $N = 8$이든 $N = 128$이든 일관되게 쓸 수 있습니다. 반대로 극단적 불균형에서는 손실이 $N$까지 커지므로, 균등(1)과 완전 쏠림($N$) 사이에서 값이 변하게 됩니다. $\alpha$는 $10^{-2}$가 논문 표준값으로, 부하 균형을 보장할 만큼 크면서 주요 cross-entropy 손실을 압도하지 않을 만큼 작은 값입니다.
Modern MoE Architectures
Shazeer 2017, GShard, Switch Transformer를 거치면서 현대 MoE의 설계 공간이 정리됩니다.
- 전문가 수와 top-k
- 공유 전문가(shared expert) 유무
- 부하 균형 방법
- MoE 레이어 배치
| 모델 | 총 파라미터 | 활성 파라미터 | 전문가 구성 (shared + routed) | Top-K | MoE 레이어 |
|---|---|---|---|---|---|
| Mixtral 8x7B | 46.7B | 12.9B | 0 + 8 | 2 | 32 (전체) |
| Mixtral 8x22B | 141B | 39B | 0 + 8 | 2 | 56 (전체) |
| DeepSeek-V3 | 671B | 37B | 1 + 256 | 8 | 58 / 61 |
| gpt-oss-120b | 116.8B | 5.1B | 0 + 128 | 4 | 36 |
| gpt-oss-20b | 20.9B | 3.6B | 0 + 32 | 4 | 24 |
| Qwen3-235B-A22B | 235B | 22B | 0 + 128 | 8 | 94 |
| Llama 4 Maverick | 400B | 17B | 1 + 128 | 1 routed | alt. dense/MoE |
Mixtral 8x7B
Mistral AI의 Mixtral of Experts 논문은 각 토큰이 47B의 파라미터에 접근할 수 있지만 추론 시에는 13B만 사용한다고 설명합니다. 정확한 수치는 총 46.7B / 활성 12.9B이며, 32개 레이어 전부가 MoE이고 Attention은 GQA(32 Q heads / 8 KV heads)로 구성되어 있습니다.
추론 FLOPs는 13B 규모의 dense 모델과 비슷하지만, 8개 전문가 전부를 추론 시점에 VRAM에 올려두어야 하기 때문에 FP16 기준 약 93.4 GB의 메모리가 필요합니다.
DeepSeek-V3
DeepSeek-V3 Technical Report는 지금까지 살펴본 MoE 설계 요소들을 한 모델에 집약한 사례입니다. 61개 레이어 중 처음 3개만 dense이고 나머지 58개가 MoE입니다. 초기 레이어에서는 토큰 임베딩에 대한 일반적인 변환이 중요해서 dense FFN을 쓰고, 이후 레이어부터는 특화된 처리를 위해 MoE로 전환하는 구조입니다.
각 MoE 레이어는 1개의 Shared 전문가와 256개의 Routed 전문가로 구성됩니다. 토큰 하나가 거치는 전문가는 Shared 1명 + Routed 중 Top-8 = 총 9명이며, 256명 중 9명만 활성화되니 매우 sparse합니다.
한 MoE 레이어의 출력은 세 항의 합으로 정의됩니다.
\[\mathbf{h}_t' = \underbrace{\mathbf{u}_t}_{\text{residual}} + \underbrace{\sum_{i=1}^{N_s} \text{FFN}_i^{(s)}(\mathbf{u}_t)}_{\text{Shared 전문가}} + \underbrace{\sum_{i=1}^{N_r} g_{i,t} \cdot \text{FFN}_i^{(r)}(\mathbf{u}_t)}_{\text{Routed 전문가}}\]풀어서 보면 단순합니다. 첫 번째는 residual connection으로 입력을 그대로 보존합니다. 두 번째는 Shared 전문가의 출력인데, $N_s = 1$이므로 사실상 FFN 하나를 토큰마다 무조건 통과시키는 것입니다. 세 번째는 Routed 전문가들의 가중합인데, $N_r = 256$이지만 $g_{i,t}$가 0이 아닌 8개만 실제로 계산됩니다. 즉 입력 그대로 + Shared 전문가 처리 + 선택된 8명의 Routed 전문가 처리를 합하는 게 전부입니다.
Affinity는 $s_{i,t} = \text{Sigmoid}(\mathbf{u}_t^\top \mathbf{e}_i)$로 계산됩니다. 각 전문가에 centroid 벡터 $\mathbf{e}_i$가 있고, 토큰과의 내적으로 어울리는 정도를 측정하는데, 이전 DeepSeek-V2가 softmax를 썼던 것과 달리 V3에서는 sigmoid로 바뀌었습니다. Softmax는 256명의 점수 합이 1이어야 해서 전문가가 많아질수록 점수가 너무 분산되는데(평균 1/256 ≈ 0.004), sigmoid는 각 전문가를 독립적으로 평가하므로 더 안정적입니다.
부하 균형도 Switch Transformer와 다른 접근을 취합니다. Switch Transformer에서는 보조 손실이 부하 균형의 주축이었지만, 라우터가 균형을 위해 품질이 낮은 전문가에 토큰을 보내는 부작용이 있었습니다. DeepSeek-V3는 부하 균형의 주축을 보조 손실에서 bias 기반으로 옮겼습니다. 각 전문가에 bias $b_i$를 더해 Top-8 선택만 보정하는 방식으로, 과부하 전문가는 bias를 줄여 덜 뽑히게, 저부하 전문가는 늘려 더 뽑히게 합니다. 보조적으로 작은 sequence-wise auxiliary loss가 함께 동작하지만, 라우터 학습을 지배하지는 않습니다.
여기에 이전 글에서 다룬 MLA(Multi-head Latent Attention)로 KV Cache를 압축하고 FP8 학습을 결합해, 671B 모델을 2.788M H800 GPU 시간(약 558만 달러)에 학습시켰습니다.
Trade-offs
MoE의 장점은 연산은 작은 모델 수준이면서 용량은 큰 모델 수준이라는 점입니다. 하지만 모든 전문가의 가중치를 VRAM에 올려두어야 하고, 토큰을 전문가에게 보내고 결과를 모으는 All-to-All 통신도 추가로 발생합니다. DeepSeek-V3를 예로 들면 토큰당 연산은 37B 수준이지만, 671B 전체를 VRAM에 상주시켜야 합니다.
| Dense 모델 | MoE 모델 | |
|---|---|---|
| 토큰당 연산 | 총 파라미터에 비례 | 활성 파라미터에만 비례 (훨씬 적음) |
| VRAM | 모델 크기만큼 | 모든 전문가가 상주해야 해서 총 파라미터만큼 |
| GPU 간 통신 | 없음 | 토큰 디스패치 + 결과 수집 (All-to-All) |
| 학습 효율 | 기준 | 같은 perplexity에 2~7배 적은 시간 |
그래서 MoE는 여러 GPU로 큰 배치를 처리하는 환경에 잘 맞고, 단일 GPU 메모리 제약이 큰 환경에서는 불리합니다. 이 한계를 완화하기 위해 전문가 오프로딩(MoE-Infinity, Mixtral-Offloading), MXFP4 양자화 같은 후속 기법들이 이어집니다.
이제 두 번째 병목인 KV Cache 메모리 낭비 문제로 넘어가보겠습니다.
The Hidden Waste of KV Cache
이전 글에서 디코드 단계가 Memory-bound이며 KV Cache가 시퀀스 길이에 선형 비례한다고 다뤘습니다. PagedAttention 논문(Kwon et al., SOSP 2023)은 여기서 한 발 더 나아가, KV Cache 자체가 실제로는 얼마나 비효율적으로 쓰이고 있었는지를 보고했습니다.
“Only 20.4% – 38.2% of the KV cache memory is used to store the actual token states in the existing systems.”
기존 시스템들이 KV Cache로 잡아둔 메모리 중 60% 이상이 단편화(fragmentation)로 사용되지 못한 채 남아 있다는 의미입니다.
Three Sources of Waste
낭비의 출처는 세 가지로 분해됩니다.
1. Reserved (예약된 슬롯)
LLM 추론에서는 출력 시퀀스의 최종 길이를 미리 알 수 없습니다. 그래서 기존 시스템들은 요청이 들어오면 max_tokens만큼의 KV Cache 공간을 미리 잡아둡니다. 이 공간은 요청이 끝날 때까지 다른 요청에 쓰일 수 없으며, 실제 생성이 짧게 끝나면 큰 낭비가 됩니다.
2. Internal Fragmentation
예약한 공간 중에서 실제로 사용되지 않은 끝부분입니다. 예약 시점에 보수적으로 큰 값을 잡았다가 실제 생성이 짧으면 그 차이만큼 그대로 버려집니다.
3. External Fragmentation
서로 다른 크기의 요청이 들어오고 나가는 동안, buddy allocator 같은 메모리 할당자가 블록 사이에 만들어내는 빈 공간입니다.
Mixtral 8x7B의 경우, GQA(32 Q heads / 8 KV heads, head_dim 128) 구성에서 토큰당 KV 크기는 다음과 같습니다.
\[\underbrace{2}_{K\text{와 }V} \times \underbrace{8}_{\text{KV heads}} \times \underbrace{128}_{\text{head dim}} \times \underbrace{32}_{\text{layers}} \times \underbrace{2}_{\text{FP16 bytes}} = 131{,}072\,\text{B} \approx 128\,\text{KB/token}\]최대 32K 컨텍스트까지 가면 요청 하나당 최대 약 4 GB의 KV Cache가 필요합니다. Mixtral 8x7B를 2대의 A100 80GB에 FP16으로 분산 적재하면(모델 가중치 약 93 GB), 남는 GPU 메모리를 KV Cache에 쓸 수 있는데 기존 시스템에서는 그 중 60% 이상이 단편화로 낭비됩니다. 이 낭비를 구조적으로 제거하기 위해 제안된 것이 PagedAttention입니다.
PagedAttention: Borrowing from Operating Systems
PagedAttention의 핵심 통찰은 한 문장으로 요약됩니다.
KV cache blocks are pages, tokens are bytes, requests are processes.
운영체제가 가상 메모리를 페이지 단위로 관리하듯, KV Cache도 고정 크기 블록(기본 $B = 16$ 토큰) 단위로 잘라 물리 메모리의 비연속적인 위치에 분산 배치하고, 블록 테이블(=페이지 테이블)로 논리 블록과 물리 블록을 매핑하는 방식입니다.
 https://blog.vllm.ai
https://blog.vllm.ai
Block-level Attention Formulation
기존 Attention은 개별 토큰 단위로 계산합니다.
\[a_{ij} = \frac{\exp(q_i^\top k_j / \sqrt{d})}{\sum_{t=1}^{i} \exp(q_i^\top k_t / \sqrt{d})}, \quad o_i = \sum_{j=1}^{i} a_{ij} v_j\]그런데 이 수식은 $k_1, k_2, \ldots$가 메모리에 연속으로 놓여 있다고 가정합니다. 블록들이 물리 메모리상 흩어져 있으면 그대로 적용할 수 없으므로, 수식을 블록 단위로 다시 쓰는 작업이 필요합니다. 아이디어는 단순합니다. $B$개 토큰씩 묶어서 블록을 만듭니다.
\[K_j = (k_{(j-1)B+1}, \ldots, k_{jB}), \quad V_j = (v_{(j-1)B+1}, \ldots, v_{jB})\]$B = 4$라면 $K_1 = (k_1, k_2, k_3, k_4)$, $K_2 = (k_5, k_6, k_7, k_8)$, … 이런 식입니다. 각 블록 $K_j$는 $B \times d$ 행렬이 되고, 한 블록이 한 페이지에 들어갑니다.
이제 Attention도 블록 단위로 다시 쓸 수 있습니다.
\[A_{ij} = \frac{\exp(q_i^\top K_j / \sqrt{d})}{\sum_{t=1}^{\lceil i/B \rceil} \exp(q_i^\top K_t \mathbf{1} / \sqrt{d})}, \quad o_i = \sum_{j=1}^{\lceil i/B \rceil} V_j A_{ij}^\top\]원래 $a_{ij}$가 토큰 i→토큰 j의 스칼라 가중치였다면, $A_{ij}$는 토큰 i→블록 j 안의 $B$개 토큰에 대한 가중치 벡터입니다. $q_i^\top K_j$를 계산하면 블록 안의 $B$개 키와의 내적이 한 번에 나오고, 분모는 모든 블록에 걸쳐 합산됩니다. 출력 $o_i$는 각 블록의 $V_j$를 $A_{ij}$로 가중합한 뒤 모든 블록을 더한 것입니다.
수학적으로는 토큰 단위 수식과 동일한 결과를 냅니다. 달라지는 것은 계산 단위뿐입니다. 블록 내부만 메모리상 연속이면 되고, 블록끼리는 흩어져 있어도 됩니다. 이것이 KV Cache를 페이지 단위로 비연속 할당할 수 있게 해주는 수학적 근거입니다. GPU 구현에서는 워프(32 스레드) 하나가 블록 하나를 맡아, 블록 내부의 연속 메모리를 coalesced read로 효율적으로 읽습니다.
Memory Allocation Pseudocode
def allocate_for_new_token(seq):
last = seq.logical_blocks[-1]
if last.num_filled < B: # 현재 블록에 여유가 있으면
last.num_filled += 1
write_kv(block_table[seq][last.id], last.num_filled - 1)
else: # 가득 찼으면 새 물리 블록 할당
new_id = len(seq.logical_blocks)
seq.logical_blocks.append(LogicalBlock(num_filled=1))
phys = block_engine.allocate()
block_table[seq][new_id] = phys
write_kv(phys, 0)
블록은 왼쪽에서 오른쪽으로 채워지고, 새 물리 블록은 이전 블록이 가득 찼을 때만 할당됩니다. 그 결과 요청당 낭비는 최대 한 블록 이내로 제한됩니다. vLLM 블로그는 실제 낭비를 4% 미만으로 보고합니다.
 PagedAttention의 블록 단위 KV Cache 관리. 논리 블록이 블록 테이블을 통해 비연속적인 물리 블록에 매핑됩니다. (https://blog.vllm.ai)
PagedAttention의 블록 단위 KV Cache 관리. 논리 블록이 블록 테이블을 통해 비연속적인 물리 블록에 매핑됩니다. (https://blog.vllm.ai)
Memory Waste Comparison Example
gpt-oss-20B(GQA 8 KV heads, head_dim 64, 24 layers)에서 평균 시퀀스 길이 512, 최대 4096, 배치 64인 워크로드를 가정해보겠습니다.
토큰당 KV 크기는 다음과 같습니다.
\[\underbrace{2}_{K\text{와 }V} \times \underbrace{8}_{\text{KV heads}} \times \underbrace{64}_{\text{head dim}} \times \underbrace{24}_{\text{layers}} \times \underbrace{2}_{\text{FP16 bytes}} = 49{,}152\,\text{B} \approx 48\,\text{KB/token}\]기존 시스템 (정적 예약):
max_tokens 기준으로 미리 잡아두면:
\[48\,\text{KB} \times 4096 \text{ tokens} \times 64 \text{ batch} \approx 12\,\text{GB}\]하지만 실제 사용은 평균 시퀀스 길이 기준:
\[48\,\text{KB} \times 512 \times 64 \approx 1.5\,\text{GB}\]낭비율: 약 87.5% — 12 GB 중 10.5 GB가 사용되지 못한 채 남습니다.
PagedAttention:
블록 크기 $B=16$인 경우, 각 시퀀스의 마지막 블록에서만 평균 절반 정도가 낭비됩니다.
\[\text{낭비} \approx \frac{B/2}{512} = \frac{8}{512} \approx 1.6\%\]추가로 메모리 단편화가 거의 없으므로 전체 낭비는 약 4% 이내에서 유지됩니다.
Copy-on-Write
페이지 단위 KV Cache는 단편화 해소 외에 또 다른 이점을 제공합니다. 바로 참조 카운트 기반 메모리 공유입니다. 동일한 프롬프트로 여러 샘플을 생성하는 parallel sampling이나 beam search에서, 모든 후보는 처음에는 같은 물리 블록을 가리키고 참조 카운트가 분기 수만큼 올라갑니다. 한 후보가 블록을 수정해야 할 때만 OS의 fork()처럼 Copy-on-Write가 일어납니다.
 동일한 프롬프트에서 여러 출력을 동시에 생성하는 parallel sampling. 프롬프트 부분은 모든 출력이 공유합니다. (https://blog.vllm.ai)
동일한 프롬프트에서 여러 출력을 동시에 생성하는 parallel sampling. 프롬프트 부분은 모든 출력이 공유합니다. (https://blog.vllm.ai)
PagedAttention에서는 이 공유가 물리 블록 수준에서 일어납니다. 모든 시퀀스의 논리 블록이 같은 물리 블록을 가리키고, 한 후보가 블록을 수정해야 할 때만 Copy-on-Write로 복사합니다.
 Seq A와 Seq B의 논리 블록이 동일한 물리 블록을 가리킵니다. 분기 시점에 해당 블록만 복사되어 각 시퀀스가 독립적으로 확장됩니다. (https://blog.vllm.ai)
Seq A와 Seq B의 논리 블록이 동일한 물리 블록을 가리킵니다. 분기 시점에 해당 블록만 복사되어 각 시퀀스가 독립적으로 확장됩니다. (https://blog.vllm.ai)
def append_kv_with_cow(seq, logical_id, new_kv):
phys = block_table[seq][logical_id]
if ref_count[phys] > 1: # 공유 중인 블록은 복사 후 수정
new_phys = block_engine.allocate()
fused_block_copy(phys, new_phys)
ref_count[phys] -= 1
ref_count[new_phys] = 1
block_table[seq][logical_id] = new_phys
phys = new_phys
write_kv(phys, seq.logical_blocks[logical_id].num_filled)
vLLM: The Inference Engine
PagedAttention이 KV Cache의 단편화를 해결했지만, 이것만으로 프로덕션 서빙 시스템이 되지는 않습니다. 실제 서빙에서는 여러 요청이 동시에 들어오고, 각 요청의 생성 길이가 다르며, 언제 끝날지 미리 알 수 없습니다. 이런 환경에서 GPU를 효율적으로 쓰려면 PagedAttention 위에 스케줄링과 메모리 관리가 추가로 필요합니다. vLLM은 이를 하나의 엔진으로 묶은 시스템입니다.
Engine Loop
vLLM의 핵심은 처리할 요청이 남아 있는 한 반복되는 3단계 루프입니다.
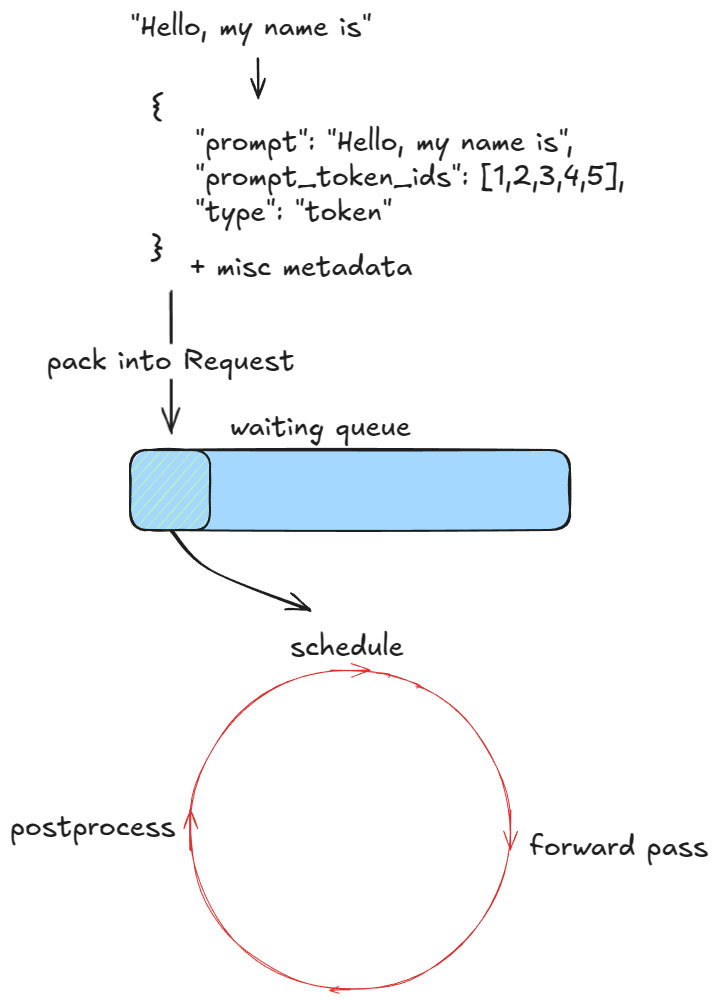 vLLM 엔진의 3단계 루프. 매 step마다 스케줄링 → forward pass → 후처리를 반복합니다. (https://vllm.ai/blog/anatomy-of-vllm)
vLLM 엔진의 3단계 루프. 매 step마다 스케줄링 → forward pass → 후처리를 반복합니다. (https://vllm.ai/blog/anatomy-of-vllm)
1단계. Schedule — 이번 step에서 어떤 요청을 처리할지 결정합니다. 이미 생성 중인 decode 요청을 우선 처리하고, 여유가 있으면 대기 큐의 새 prefill 요청을 추가합니다. 이때 KV Cache Manager가 free block queue에서 물리 블록을 꺼내 할당합니다.
2단계. Forward pass — 선택된 요청들을 하나의 배치로 묶어 모델을 실행하고 다음 토큰을 샘플링합니다. 여러 시퀀스가 하나로 flatten되지만, position index와 attention mask로 각 시퀀스가 자기 토큰에만 attend하도록 구분됩니다. 여기서 PagedAttention 커널이 비연속 물리 블록을 블록 테이블로 찾아가며 KV를 읽습니다.
3단계. Postprocess — 생성된 토큰을 각 요청에 붙이고, 종료 조건(EOS, max_tokens)을 확인합니다. 끝난 요청은 빠지고 그 블록은 free block queue로 반환됩니다.
Continuous Batching
이 루프가 매 step마다 배치를 재구성한다는 점이 핵심입니다. 기존 서빙 시스템의 static batching에서는 배치 안의 모든 시퀀스가 끝날 때까지 기다린 뒤 다음 배치를 시작합니다. 한 시퀀스가 10 토큰만에 끝나도, 같은 배치의 다른 시퀀스가 500 토큰을 생성할 때까지 GPU가 그 자리를 비워두지 못합니다.
vLLM은 Orca(OSDI ‘22)에서 빌려온 iteration 단위 스케줄링으로 이 문제를 해결합니다. 매 step의 Schedule 단계에서 종료된 시퀀스는 즉시 빠지고 대기 중인 새 요청이 합류하므로, 패딩 없이 GPU를 계속 활용할 수 있습니다. 메모리가 부족해지면 가장 늦게 들어온 요청의 KV 블록을 CPU RAM으로 옮기거나(swap), 버리고 나중에 재계산(recompute)하는 방식으로 선점합니다.
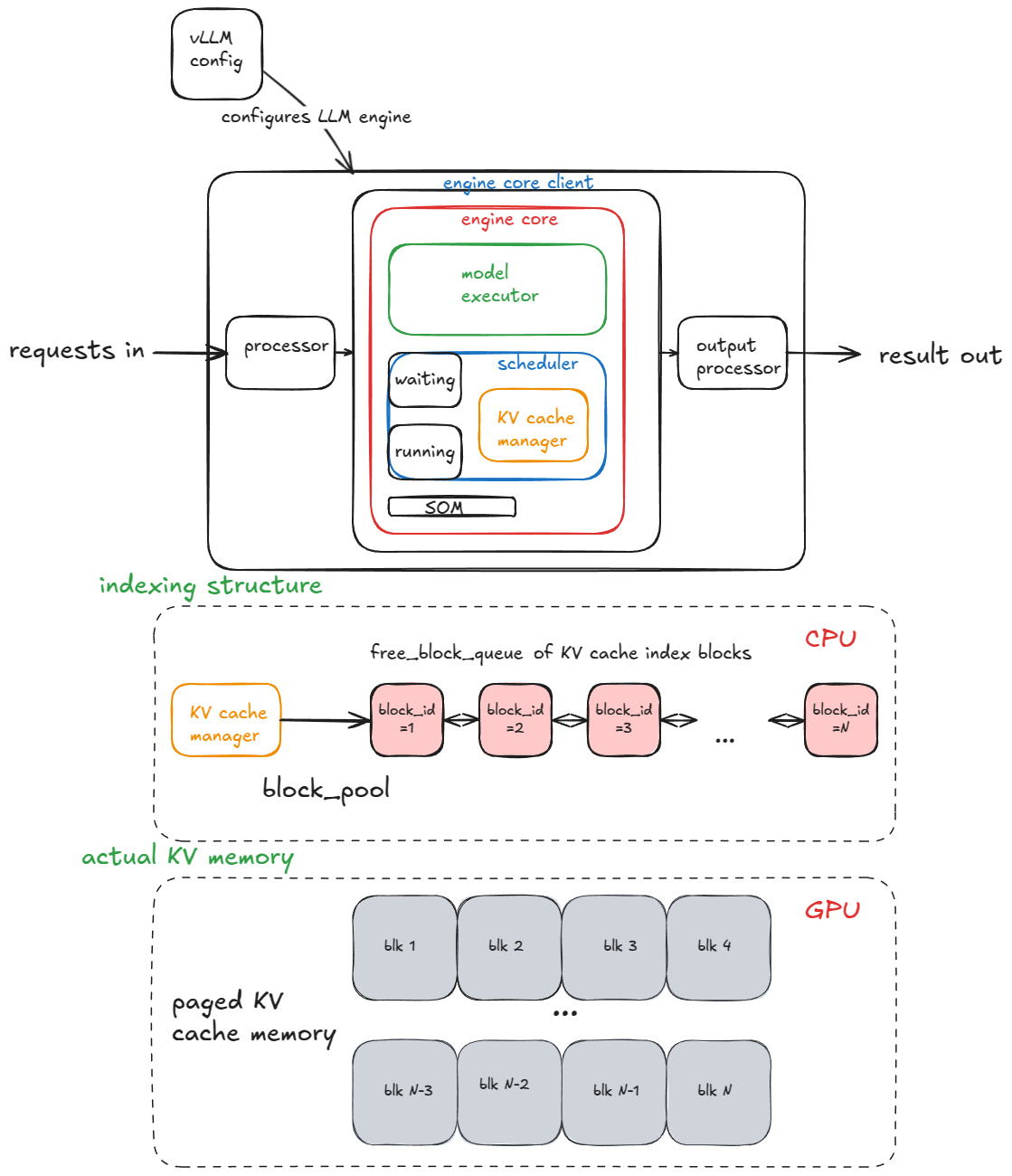 vLLM 엔진의 컴포넌트 구조. Scheduler가 waiting/running 큐로 요청을 관리하고, KV Cache Manager가 free block queue에서 물리 블록을 할당합니다. 아래쪽에 GPU의 paged KV cache memory가 실제 KV를 저장합니다. (https://vllm.ai/blog/anatomy-of-vllm)
vLLM 엔진의 컴포넌트 구조. Scheduler가 waiting/running 큐로 요청을 관리하고, KV Cache Manager가 free block queue에서 물리 블록을 할당합니다. 아래쪽에 GPU의 paged KV cache memory가 실제 KV를 저장합니다. (https://vllm.ai/blog/anatomy-of-vllm)
Throughput
PagedAttention으로 메모리 낭비를 줄이고, continuous batching으로 GPU 유휴를 없앤 것의 효과는 처리량으로 드러납니다. 논문은 동일 지연 시간 기준으로 기존 시스템 대비 2 ~ 4배의 처리량 향상을 보고하며, vLLM 0.1 블로그 기준 HuggingFace Transformers 대비 14 ~ 24배, TGI 대비 2.2 ~ 3.5배입니다.
 LLaMA-13B / A100 환경에서 요청 속도(Request/s)를 높여가며 측정한 처리량. vLLM이 HuggingFace Transformers와 TGI를 큰 폭으로 앞서며, 특히 요청이 몰리는 구간에서 차이가 벌어집니다. (https://blog.vllm.ai)
LLaMA-13B / A100 환경에서 요청 속도(Request/s)를 높여가며 측정한 처리량. vLLM이 HuggingFace Transformers와 TGI를 큰 폭으로 앞서며, 특히 요청이 몰리는 구간에서 차이가 벌어집니다. (https://blog.vllm.ai)
다만 이 성능이 공짜로 얻어지는 것은 아닙니다. 초기 vLLM(v0) 기준으로, PagedAttention 커널 자체는 FasterTransformer의 fused attention 커널보다 20 ~ 26% 느렸습니다. 블록 테이블 접근과 비연속 메모리 접근에서 오버헤드가 발생하기 때문입니다. vLLM v1에서는 FlashAttention-2/3 기반으로 커널이 재작성되어 이 격차가 크게 줄었습니다. 그러나 메모리 활용도가 높아져 더 큰 배치를 동시에 처리할 수 있게 되고, 종단(end-to-end) 처리량은 커널 단위 손해를 상쇄하고도 큰 폭으로 앞서게 됩니다.
What Became the Next Standard (2026)
이 글의 초고를 작성할 시점에 다음 후보로 거론되던 기법들은 1년 사이에 일부는 프로덕션 표준에 가까워졌고, 일부는 그렇게 되지 못했습니다.
Prefill-Decode Disaggregation
이 중 가장 분명하게 자리 잡은 기법입니다. Compute-bound인 Prefill 단계와 Memory-bound인 Decode 단계의 자원 요구가 서로 달라, 같은 GPU에 묶어두면 양쪽 모두에서 자원 활용이 비효율적이 됩니다. Prefill 인스턴스(cuda:0)에서 KV를 계산한 뒤, NIXL 같은 RDMA 백엔드를 통해 Decode 인스턴스(cuda:1)로 전송하면 각 단계가 자기에게 맞는 자원만 쓸 수 있습니다.
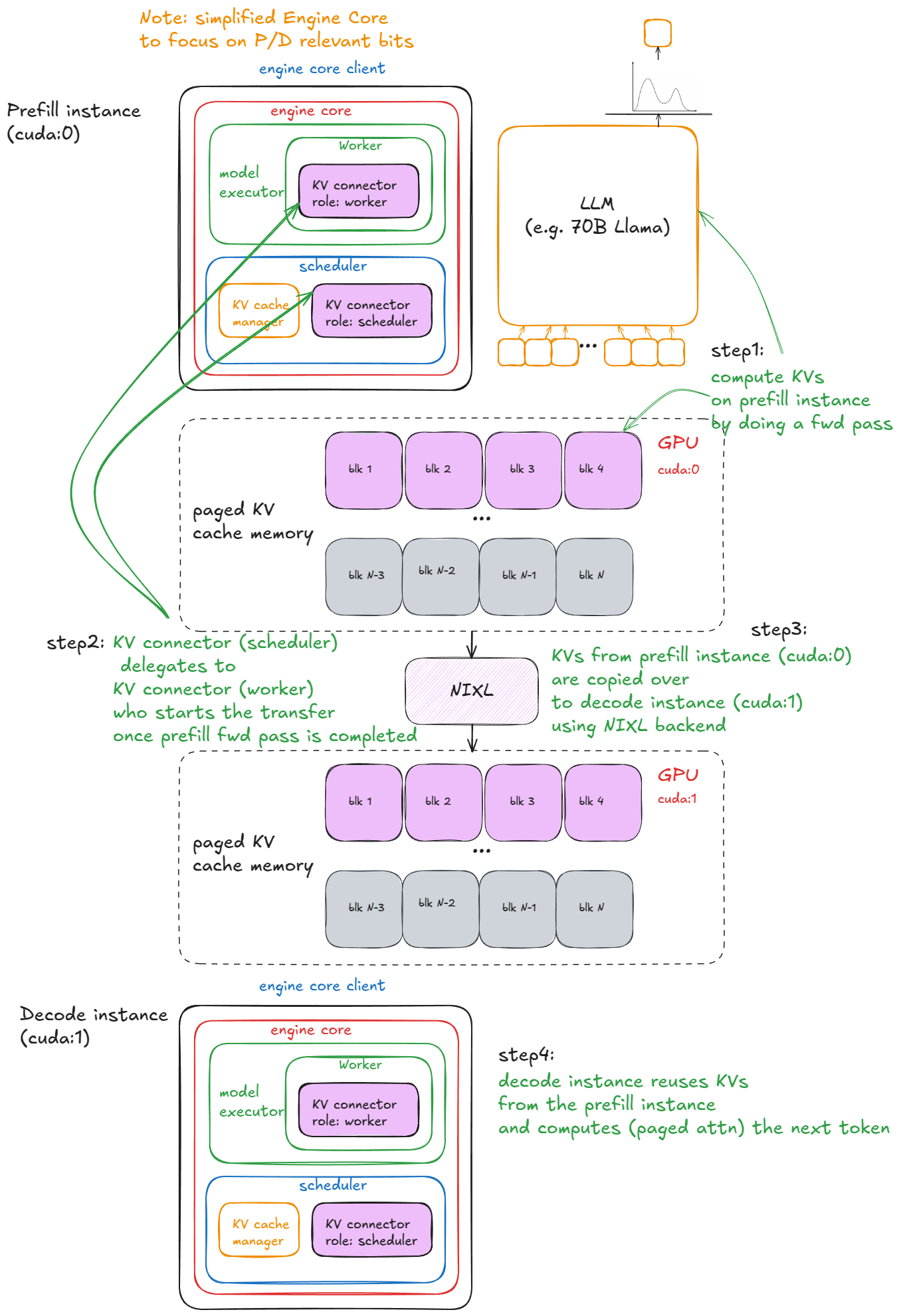 Prefill 인스턴스에서 KV를 계산(step 1)한 뒤, KV connector가 NIXL 백엔드를 통해 Decode 인스턴스로 KV 블록을 전송(step 2~3)합니다. Decode 인스턴스는 전달받은 KV로 paged attention을 수행해 다음 토큰을 생성(step 4)합니다. (https://vllm.ai/blog/anatomy-of-vllm)
Prefill 인스턴스에서 KV를 계산(step 1)한 뒤, KV connector가 NIXL 백엔드를 통해 Decode 인스턴스로 KV 블록을 전송(step 2~3)합니다. Decode 인스턴스는 전달받은 KV로 paged attention을 수행해 다음 토큰을 생성(step 4)합니다. (https://vllm.ai/blog/anatomy-of-vllm)
UCSD Hao AI Lab의 회고에 따르면 2025년 말 기준으로 NVIDIA Dynamo, llm-d, Ray Serve LLM, SGLang, vLLM, LMCache, Mooncake 등 다수의 프로덕션급 서빙 프레임워크가 disaggregation을 기반으로 동작합니다. Meta, LinkedIn, Mistral, Hugging Face가 이미 프로덕션에 도입했고, 보고된 효과는 워크로드에 따라 처리량 70% 향상과 TTFT 90% 단축 수준입니다.
다만 P-D Disaggregation은 여러 GPU 인스턴스와 그 사이의 KV 전송 인프라가 필요합니다. 단일 GPU 환경에서는 같은 문제를 다른 방식으로 푸는 Chunked Prefill이 대안이 됩니다. 긴 프롬프트의 prefill을 한 번에 처리하지 않고 토큰 단위 chunk로 잘라서, 매 step마다 decode 토큰과 함께 배치에 끼워 넣는 방식입니다. Prefill이 GPU를 독점하지 않으므로 decode 요청의 지연이 줄어들고, 별도 인프라 없이 단일 엔진 안에서 동작합니다. vLLM v1과 SGLang 모두 기본으로 활성화되어 있습니다.
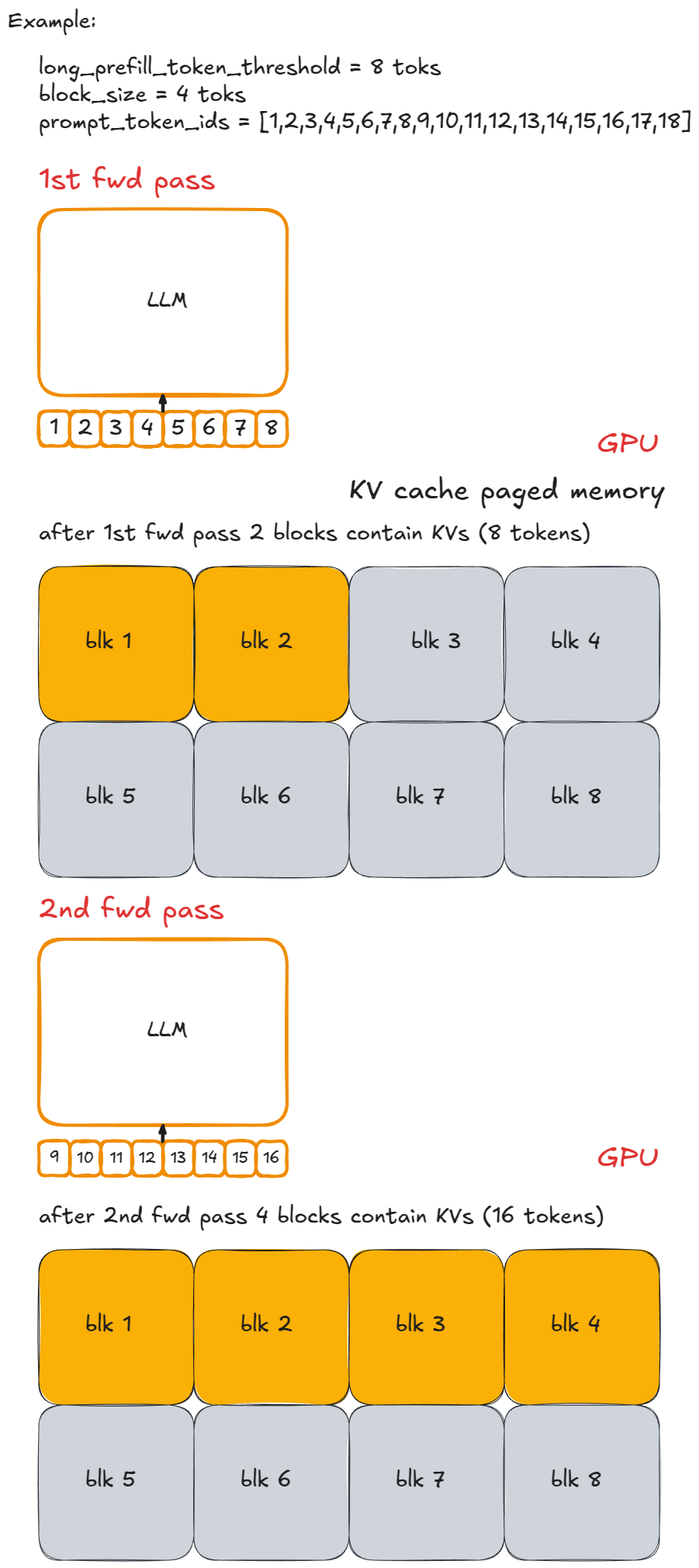 긴 프롬프트를 chunk 단위로 나누어 여러 step에 걸쳐 처리합니다. 한 step 안에서 prefill chunk와 decode 토큰이 함께 배치됩니다. (https://vllm.ai/blog/anatomy-of-vllm)
긴 프롬프트를 chunk 단위로 나누어 여러 step에 걸쳐 처리합니다. 한 step 안에서 prefill chunk와 decode 토큰이 함께 배치됩니다. (https://vllm.ai/blog/anatomy-of-vllm)
NVIDIA Dynamo
2026년 3월 정식 출시된 NVIDIA Dynamo 1.0은 vLLM/SGLang/TensorRT-LLM 같은 엔진 위에 올라가는 오케스트레이션 레이어입니다. AWS, Azure, GCP, OCI 같은 하이퍼스케일러와 Perplexity, Cursor, Baseten, ByteDance, PayPal, Pinterest 등이 채택했습니다. 핵심 컴포넌트는 다음과 같습니다.
- KVBM (KV Block Manager): GPU HBM → CPU RAM → SSD → 네트워크 스토리지로 KV Cache 계층 오프로딩
- NIXL: RDMA 기반 GPU-to-GPU KV 전송 라이브러리
- Grove: Kubernetes 위의 hierarchical gang scheduling
- LLM-aware Routing: 동일 prefix 요청을 같은 노드로 라우팅해 KV 재계산 회피
NVFP4 / MXFP4 Quantization
Blackwell B200/B300이 FP4를 하드웨어 네이티브로 지원하면서 4비트 양자화가 프로덕션 영역에 들어왔습니다. NVFP4는 MXFP4를 확장한 것으로, 블록 크기를 32에서 16으로 줄이고 two-level scaling(per-block E4M3 + per-tensor FP32)을 도입해 FP8 대비 2 ~ 3배의 산술 처리량과 약 1.8배의 메모리 감소를 제공합니다. NVIDIA가 nvidia/Llama-3.3-70B-Instruct-NVFP4, nvidia/DeepSeek-R1-NVFP4 같은 공식 체크포인트를 배포하고, vLLM/TensorRT-LLM이 네이티브로 디코딩합니다.
Speculative Decoding (EAGLE-3, MTP)
2025 ~ 2026년 사이에 주요 서빙 프레임워크의 기본 옵션 중 하나로 자리 잡았습니다. vLLM, SGLang, TensorRT-LLM 모두 네이티브로 지원하며, 프로덕션 벤치마크는 낮은-중간 동시성 구간에서 2.0 ~ 6.5배의 처리량 향상을 보고합니다. DeepSeek-V3에 내장된 MTP(Multi-Token Prediction)는 80% 이상의 acceptance rate 조건에서 약 1.8배의 가속이 보고되었습니다.
위 기법들이 자리를 잡는 동안, 비슷한 시기에 제안되었지만 채택이 이루어지지 않은 기법들도 있습니다.
- vAttention: PagedAttention의 블록 테이블 오버헤드를 OS 레벨 가상 메모리로 대체하는 접근입니다. 설계 자체는 깔끔하지만, vLLM v1의 prefix caching + LMCache 조합이 먼저 자리 잡으면서 주류가 되지는 못했습니다
- Mamba-Transformer 하이브리드: Attention의 $O(N)$ KV Cache 비용을 SSM(State Space Model)의 고정 크기 상태로 대체하려는 시도입니다. Jamba(AI21), Nemotron-H(NVIDIA) 같은 모델들이 등장했지만, 프런티어 모델 다수는 여전히 Transformer-MoE 스택을 채택하고 있습니다.
- Expert Offloading: MoE의 비활성 전문가를 CPU/SSD에 내려놓고 필요할 때만 GPU로 올리는 방식입니다. 단일 GPU 시나리오에서 주로 의미가 있고, 프로덕션은 EP(Expert Parallelism)로 다중 GPU에 분산하는 방향으로 정착했습니다.
Conclusion
이전 글의 GQA와 FlashAttention이 Attention 측 비용을 줄였다면, 이 글에서 다룬 MoE와 PagedAttention은 그 다음에 남는 두 병목 FFN 연산량과 KV Cache 메모리 단편화을 각각 공략합니다.
MoE는 모델 아키텍처 안에서, PagedAttention은 서빙 시스템 안에서 작동하며, 현대 프로덕션 스택은 이 기법들을 함께 쌓아 올립니다. 2026년 현재 그 위에 Prefill-Decode Disaggregation, NVIDIA Dynamo, NVFP4 양자화, Speculative Decoding이 새로운 표준으로 자리 잡고 있습니다.
Comments