4 min to read
ScaNN, Efficient Vector Similarity Search 리뷰
Announcing ScaNN: Efficient Vector Similarity Search
quries들에 대하여 제목, 저자 또는 기타 쉽게 인덱싱할 수 있는 기준으로 정확한 매칭시키기 위해 대규모 문학 작품 데이터 집합을 검색한다고 가정합니다. 이러한 작업은 SQL과 같은 언어를 사용하는 관계형 데이터베이스에 매우 적합합니다. 그러나 “Civil War poem,”같은 추상적인 query에 대해서는 단순히 공통 단어 수와 같은 유사성 지표로만으로는 한계점이 있습니다.
예를 들어, science fiction이라는 query는 earth science와 공통되는 단어를 가지고 있기 때문에 실제 더 관련성이 높은 future와는 매칭되지 않습니다.
머신 러닝(ML)은 언어의 의미를 이해하도록 발전되어왔으며, 따라서 이러한 추상적인 queries에 대해서도 적절하게 답변할 수 있습니다. 최신 ML 모델들은 텍스트 및 이미지와 같은 입력을 임베딩 즉, 고차원 벡터로 변환하여 더 유사한 입력이 서로 더 가깝게 뭉치도록 훈련할 수 있습니다.
따라서 주어진 query에 대해 임베딩을 계산하고, query와 가장 가까운 임베딩값을 가지는 문학 작품을 찾을 수 있습니다. 이러한 방식으로 ML은 추상적이고 이전에는 특정하기 어려웠던 작업을 수학적 작업으로 변환했습니다. 그러나 계산상의 과제가 남아 있습니다. 주어진 query 임베딩에서 가장 가까운 데이터셋 임베딩을 어떻게 신속하게 찾을 수 있을까요? 임베딩의 세트는 완전 탐색을 하기에는 너무 큰 경우가 많고, 높은 차원 때문에 가지치기가 어렵습니다.
ICML 2020 논문인 Accelerating Large-Scale Inference with Anisotropic Vector Quantization에서는 데이터 세트 벡터를 압축하여 빠른 근사 거리 계산을 가능하게 하는 방법에 초점을 맞추어 이 문제를 해결하고 이전 작업에 비해 정확도를 크게 높이는 새로운 압축 기술을 제안합니다. 이 기술은 vector similarity search library(ScaNN)에서 사용 가능하며, ann-benchmarks.com에서 측정한 바에 따르면 다른 벡터 유사성 검색 라이브러리를 2배 이상 능가할 수 있습니다.
The Importance of Vector Similarity Search
임베딩 기반 검색은 단순한 색인화를 가능하게 하는 것을 넘어서 의미적인 이해를 기반으로 query에 응답하는 데 효과적인 기술입니다. 머신러닝 모델들은 query와 database 항목들을 공통 벡터 임베딩 공간에 매핑하도록 훈련되어 임베딩 사이의 거리가 의미를 가지도록, 즉 유사한 항목이 서로 더 가깝게 됩니다.
이 접근법으로 query에 응답하려면 시스템은 먼저 query를 임베딩 공간에 매핑해야 합니다. 그런 다음 모든 database 임베딩 중에서 query에 가장 가까운 것을 찾아야 합니다.이것은 nearest neighbor search 문제입니다. query-database 임베딩 유사도를 정의하는 가장 일반적인 방법 중 하나는 inner product 입니다. 이러한 nearest neighbor search 유형들은 maximum inner-product search(MIPS)로 알려져 있습니다.
database 사이즈는 쉽게 수백만, 심지어 수십억이 될 수 있기 때문에 MIPS는 종종 추론 속도에 대한 계산 병목현상이 발생하고 완전탐색은 비현실적입니다. 이를 위해서는 brute-force 탐색에 비해 상당한 속도 향상을 높일 수 있지만 정확도가 떨어지는(trade-off) approximate MIPS 알고리즘을 사용하여야 합니다.
A New Quantization Approach for MIPS
Several state-of-the-art solutions for MIPS은 database items를 압축하여 내적을 근사함으로써, brute-force으로 계산하는 데 걸리는 시간보다 훨씬 짧은 시간에 계산할 수 있도록 합니다. 이 압축은 일반적으로 learned quantization를 사용하여 수행됩니다. 여기서 벡터의 codebook은 database에서 학습되며 database 요소를 근사시켜 표현합니다.
이전의 vector quantization는 각각의 vector $x$와 quantized 형태인 $\tilde{x}_{i}$ 사이의 평균 거리를 최소화하는 것이 목적이었습니다. 이는 유용하지만 nearest-neighbor search의 정확도를 최적화하는 것은 아닙니다.
따라서 논문의 핵심 아이디어는 평균 거리를 더 높이도록 하는 인코딩이 실제로 더 나은 MIPS 정확도를 가져올 수 있다는 것입니다.
우리는 두개의 database 임베딩 $x_1$, $x_2$를 가지고 있으며, 각각을 두 개의 중심점($c_1$ or $c_2$) 중 하나로 quantize해야 한다고 가정해봅시다.
우리의 목표는 $\left\langle q, x_i\right\rangle $ 의 내적과 $\left\langle q, x_{i}\right\rangle $ 의 내적이 가능한 유사하도록 $x_{i}$를 $\tilde{x}_{i}$ 로 quantize시키는 것입니다.
이는 $\tilde{x}_{i}$ 의 $q$에 대한 투영 크기를 $x_i$의 $q$에 대한 투영과 가능한 비슷하게 만드는 것으로 시각화할 수 있습니다
quantization에 대한 전통적인 접근법(left)에서는, 각 $x_i$에 대해 가장 가까운 중심점을 선택하기 때문에 두 지점간의 상대적인 순위가 부정확합니다.
\(\left\langle q, x_{1}\right\rangle\)가 $\left\langle q, x_{2}\right\rangle$ 보다 작음에도 불구하고,
\(\left\langle q, \tilde{x}_{1}\right\rangle\)는 $\left\langle q, \tilde{x}_{2}\right\rangle$ 보다 큰 것으로 나타납니다.
만약 $x_1$을 $c_1$에 할당하고 $x_2$를 $c_2$에 할당하게 되면 우리는 올바른 순위을 얻을 수 있습니다.
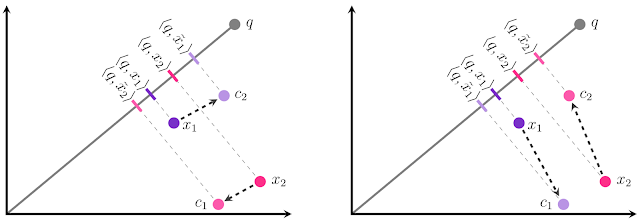
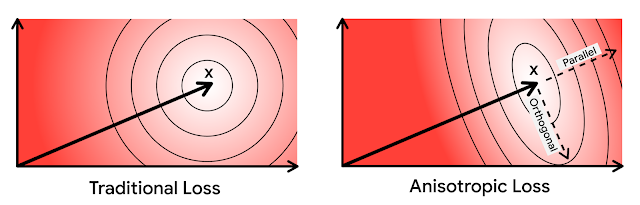
이는 크기만큼이나 방향도 중요한 것으로 나타났습니다. $x_1$이 $c_2$보다 $c_1$과 멀리 떨어져있을지라도, $c_1$과 $x_1$사이의 offset은 $x_1$과 전체적으로 방향이 거의 직교하게 됩니다. 반면, $c_2$와의 offset은 평행합니다.($x_2$의 경우 동일한 상황이 적용되지만 뒤집힘)
평행하는 방향에서의 에러는 high inner products에 대해서 불균형적으로 영향을 미치기 때문에 MIPS 문제에서 위험합니다. 이를 위해 직관적으로 원래 벡터와 평행하는 quantization error에는 크게 penalty를 부여합니다. 이는 loss함수의 방향에 의존하기 때문에 anisotropic vector quantization 기법이라 합니다. 이 기법은 high inner products에 대한 높은 정확도를 위해 lower inner products에 대한 quantization error를 증가시키게 됩니다.
기본적으로 두 벡터간의 방향이 orthogonal하다면 내적은 0이 되므로, 즉 0에 가까운 내적을 가지는 경우 벡터들에 대한 quantization error를 증가시킬지라도, 방향이 parallel 한 경우 즉 -1, 1에 가까운 내적을 가지는 벡터들에 대한 quantize를 더 잘 수행할려고 한다고 이해할 수 있다.
Anisotropic Vector Quantization in ScaNN
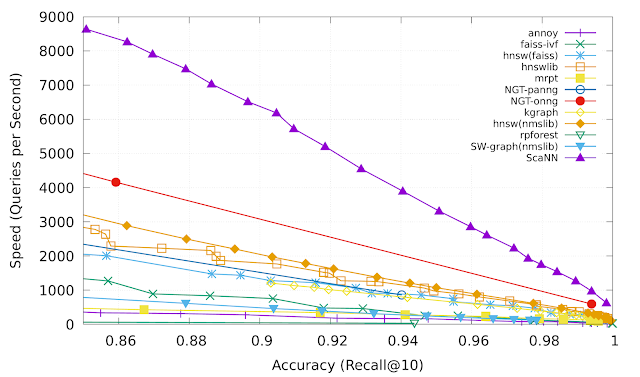
Anisotropic vector quantization를 통해 ScaNN은 top-K MIPS 결과에 대해서 내적을 더 잘 추정할 수 있으므로 더 높은 정확도를 달성할 수 있습니다. ann-benchmarks.com으로부터 glove-100-angular benchmark에서 ScaNN은 세심하게 조정된 다른 11개의 벡터 유사성 검색 라이브러리를 능가하여 특정 정확도에 대해 초당 약 2배 더 많은 query를 처리했습니다.
Conclusion
벡터 quantization 목표를 MIPS의 목표에 맞게 수정함으로써, 임베딩 기반 검색 성능의 핵심 지표인 nearest neighbor search 벤치마크에서 state-of-the-art performance 성능을 달성합니다. anisotropic vector quantization는 중요한 기술이지만, compression distortion과 같은 중간 목표가 아닌 검색 정확도 향상이라는 최종 목표를 위해 알고리즘을 최적화함으로써 달성할 수 있는 성능의 한 예로 볼 수 있습니다.
Comments