24 min to read
Kubespray HA Cluster: From Deployment to Disaster Recovery - 1
Cloudnet@ K8S Deploy — Week5
Node Lifecycle Management
Kubernetes 클러스터는 워크로드 증가에 따라 노드를 동적으로 추가하거나, 유지보수 또는 비용 절감을 위해 노드를 제거해야 하는 상황이 빈번하게 발생합니다.
이를 위해 Kubespray는 초기 클러스터 배포뿐만 아니라 노드 추가(scale.yml)와 제거(remove-node.yml)를 위한 전용 Playbook을 제공하며, 이들은 기존 클러스터의 가용성을 보장하면서 노드를 안전하게 추가하거나 제거하는 메커니즘을 내장하고 있습니다.
Scale Playbook Architecture
Kubespray의 scale.yml은 초기 클러스터 배포에 사용하는 cluster.yml과 유사한 구조를 가지지만, 기존 클러스터를 건드리지 않고 새 노드만 추가하도록 최적화되어 있습니다.
두 Playbook의 가장 큰 차이는 etcd 클러스터 설정 방식과 대상 호스트 범위입니다.
# /root/kubespray/playbooks/scale.yml
- name: Install etcd
vars:
etcd_cluster_setup: false
etcd_events_cluster_setup: false
import_playbook: install_etcd.yml
etcd_cluster_setup:false는 기존 etcd 클러스터를 변경하지 않음을 의미합니다. 새 노드가 etcd 멤버로 추가되어야 하는 경우에만 kubeadm join을 통해 개별적으로 추가되며, 기존 etcd 멤버는 재시작되지 않습니다.
scale.yml에는 kubernetes/control-plane Role이 포함되어 있지 않으므로, API Server, Controller Manager, Scheduler의 설정이 변경되지 않으며, 이는 다음을 의미합니다.
- API Server Certificate 재생성 없음
- kube-apiserver, kube-controller-manager, kube-scheduler Static Pod 재시작 없음
- kubeadm-config.yaml 변경 없음
따라서 기존 Control Plane 노드는 노드 추가 작업에 전혀 영향을 받지 않습니다.
- name: Download images to ansible host cache via first kube_control_plane node
hosts: kube_control_plane[0]
roles:
- { role: download, when: "not skip_downloads and download_run_once and not download_localhost" }
download_run_once:true로 설정하면, Kubernetes 바이너리와 컨테이너 이미지를 첫 번째 Control Plane 노드에서만 다운로드한 후 Ansible 캐시에 저장하고, 이를 새 노드로 배포합니다.
- name: Upload control plane certs and retrieve encryption key
hosts: kube_control_plane | first
environment: "{{ proxy_disable_env }}"
gather_facts: false
tags: kubeadm
roles:
- { role: kubespray_defaults }
tasks:
- name: Upload control plane certificates
command: >-
{{ bin_dir }}/kubeadm init phase
--config {{ kube_config_dir }}/kubeadm-config.yaml
upload-certs
--upload-certs
environment: "{{ proxy_disable_env }}"
register: kubeadm_upload_cert
changed_when: false
- name: Set fact 'kubeadm_certificate_key' for later use
set_fact:
kubeadm_certificate_key: "{{ kubeadm_upload_cert.stdout_lines[-1] | trim }}"
when: kubeadm_certificate_key is not defined
새 Control Plane 노드의 조인을 위해 kubeadm으로 Control Plane 인증서를 업로드하고, 필요한 certificate_key를 추출하여 이후 단계에서 재사용합니다.
- name: Target only workers to get kubelet installed and checking in on any new nodes(engine)
hosts: kube_node
gather_facts: false
any_errors_fatal: "{{ any_errors_fatal | default(true) }}"
environment: "{{ proxy_disable_env }}"
roles:
- { role: kubespray_defaults }
- { role: kubernetes/preinstall, tags: preinstall }
- { role: container-engine, tags: "container-engine", when: deploy_container_engine }
- { role: download, tags: download, when: "not skip_downloads" }
- role: etcd
tags: etcd
vars:
etcd_cluster_setup: false
when:
- etcd_deployment_type != "kubeadm"
- kube_network_plugin in ["calico", "flannel", "canal", "cilium"] or cilium_deploy_additionally | default(false) | bool
- kube_network_plugin != "calico" or calico_datastore == "etcd"
Worker Node에 etcd Role이 적용되는 경우(Calico가 etcd를 직접 사용하는 경우)에도, etcd_cluster_setup:false로 인해 기존 etcd 멤버는 변경되지 않습니다.
Add Worker Node
새 노드를 [kube_node] 그룹에 추가합니다.
cat << EOF > /root/kubespray/inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
EOF
추가하였다면, Ansible 연결을 통해 확인할 수 있습니다.
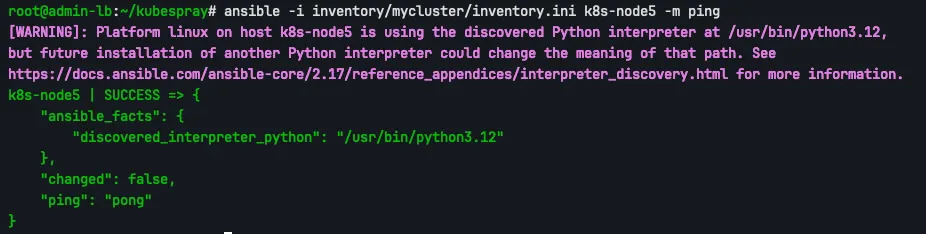 ansible -i inventory/mycluster/inventory.ini k8s-node5 -m ping
ansible -i inventory/mycluster/inventory.ini k8s-node5 -m ping
실제 Playbook을 수행하여 클러스터에 Join시킵니다.
# --limit 옵션으로 k8s-node5만 대상으로 지정
ANSIBLE_FORCE_COLOR=true ansible-playbook -i inventory/mycluster/inventory.ini -v scale.yml \
--limit=k8s-node5 \
-e kube_version="1.32.9" | tee kubespray_add_worker_node.log
 kubectl get node -o wide
kubectl get node -o wide
node4에만 배포되어있던 Pod의 Scale을 조정하여 node5에도 배포되는지 확인할 수 있습니다.
kubectl scale deployment webpod --replicas 2
kubectl scale deployment webpod --replicas 1
 kubectl get pod -o wide
kubectl get pod -o wide
Remove Worker Node
노드를 클러스터에서 제거할 때에는 실행 중인 Pod의 안전한 이동, etcd 클러스터의 과반수 멤버 유지, 그리고 해당 노드에 남아 있는 Kubernetes 관련 로컬 설정 및 상태의 완전한 정리가 순차적으로 수행되어야 합니다. Kubespray의 remove-node.yml 플레이북은 이러한 안전 메커니즘을 내장하고 있으며, 사용자의 명시적인 확인 없이는 노드를 삭제하지 않도록 설계되어 있습니다.
- name: Confirm node removal
hosts: "{{ node | default('this_is_unreachable') }}"
tasks:
- name: Confirm Execution
pause:
prompt: "Are you sure you want to delete nodes state? Type 'yes' to delete nodes."
register: pause_result
run_once: true
when:
- not (skip_confirmation | default(false) | bool)
- name: Fail if user does not confirm deletion
fail:
msg: "Delete nodes confirmation failed"
when: pause_result.user_input | default('yes') != 'yes'
실제로 노드가 삭제되기 전 사용자에게 최종 확인을 받습니다. Playbook이 일시 정지되며, 사용자가 yes를 입력해야만 계속 진행됩니다. 자동화 스크립트에서는 -e skip_confirmation=true 옵션으로 이 단계를 건너뛸 수 있습니다.
Currently cannot remove first control plane node or first etcd node
다만 파일에는 위의 주석과 같이 첫 번째 Control Plane 노드나 첫 번째 etcd 노드는 이 Playbook으로 제거할 수 없습니다고 명시되어 있습니다.
노드 제거의 핵심 단계는 Drain입니다. Drain은 다음 작업을 수행합니다.
- Cordon: 노드를 SchedulingDisabled 상태로 설정하여 새 Pod가 스케줄링되지 않도록 합니다.
- Eviction: 실행 중인 모든 Pod를 다른 노드로 이동 (DaemonSet 제외)
- Graceful Termination: 각 Pod에 terminationGracePeriodSeconds 시간을 주어 정상 종료
Drain 명령어는 내부적으로 Eviction API를 사용하며, 이는 PDB(PodDisruptionBudget) 정책을 준수합니다. 만약 PDB가 Pod 제거를 차단하면, Drain은 실패하고 재시도를 반복합니다.
cat <<EOF | kubectl apply -f -
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: webpod
namespace: default
spec:
maxUnavailable: 0
selector:
matchLabels:
app: webpod
EOF
- maxUnavailable: 0 설정은 단 하나의 Pod도 동시에 종료될 수 없음을 의미하며, 이는 노드 Drain을 완전히 차단합니다.
즉, Kubespray의 Drain 태스크는 실패 시 재시도하지만, PDB 정책이 변경되지 않는 한 계속 실패하게 됩니다. 따라서 노드를 제거하기 위해서는 정의한 PDB정책을 삭제해야 합니다.
kubectl delete pdb webpod
Playbook 코드를 보면 reset_nodes 변수가 여러 곳에서 사용되며, 기본값은 True입니다.
# /root/kubespray/playbooks/remove_node.yml
- name: Reset node
hosts: "{{ node | default('this_is_unreachable') }}"
gather_facts: false
environment: "{{ proxy_disable_env }}"
pre_tasks:
- name: Gather information about installed services
service_facts:
when: reset_nodes | default(True) | bool
roles:
- { role: kubespray_defaults, when: reset_nodes | default(True) | bool }
- { role: remove_node/pre_remove, tags: pre-remove }
- role: remove-node/remove-etcd-node
when: "'etcd' in group_names"
- { role: reset, tags: reset, when: reset_nodes | default(True) | bool }
# Currently cannot remove first control plane node or first etcd node
- name: Post node removal
hosts: "{{ node | default('this_is_unreachable') }}"
gather_facts: false
environment: "{{ proxy_disable_env }}"
roles:
- { role: kubespray_defaults, when: reset_nodes | default(True) | bool }
- { role: remove-node/post-remove, tags: post-remove }
reset_nodes 변수는 클러스터에서 노드를 제거할 때, 해당 노드의 로컬 Kubernetes 구성과 상태를 실제로 초기화할지 여부를 제어합니다.
- true: 노드를 클러스터에서 제거함과 동시에, 해당 노드에 남아 있는 Kubernetes 관련 구성 요소와 런타임 상태를 완전히 초기화합니다.
- false: 노드를 클러스터 멤버십에서만 제거하고, 해당 노드의 로컬 Kubernetes 구성과 상태는 유지합니다. 실습을 위해서는 노드를 제거하지만 다시 추가할 예정이기 때문에 false로 바꾸어서 실행시킵니다.
# 클러스터에서 제거 (설정 유지)
ansible-playbook -i inventory/mycluster/inventory.ini -v remove-node.yml -e node=k8s-node5 -e reset_nodes=false
 kubectl get node -o wide
kubectl get node -o wide
제거가 되었다면 이후 실습을 진행하기 위해 다시 노드를 join합니다.
ANSIBLE_FORCE_COLOR=true ansible-playbook -i inventory/mycluster/inventory.ini -v scale.yml --limit=k8s-node5 -e kube_version="1.32.9" | tee kubespray_add_worker_node.log
 kubectl get node -o wide
kubectl get node -o wide
Adding/replacing a node
Control Plane(Etcd Master)
Kubernetes 클러스터에서 첫 번째 Control Plane 노드를 교체하는 작업은 일반적인 노드 교체와 다른 접근이 필요합니다.
첫 번째 Control Plane 노드는 클러스터 초기화 시 CA 인증서, kubeadm-config ConfigMap, 관리자 kubeconfig 등 핵심 구성요소의 원본을 보관하는 역할을 하기 때문입니다.
Kubespray는 inventory 파일의 kube_control_plane 그룹에서 첫 번째로 나열된 노드를 first_kube_control_plane 변수로 인식합니다. 이 노드는 클러스터 부트스트랩 단계에서 다음 세 가지 핵심 역할을 수행합니다:
-
클러스터의 모든 인증서에 서명하는 CA 인증서(Certificate Authority)를 최초로 생성하고 저장
-
kubeadm init실행 시, 관리자 kubeconfig(admin.conf)를 생성 및 보관 -
kubeadm init실행 시, 사용된 클러스터 설정을 kubeadm-config ConfigMap으로 생성하여, controlPlaneEndpoint 및 etcd endpoint 정보를 저장합니다.
이전에 설명했던 것처럼 Kubespray의 remove-node.yml은 첫 번째 Control Plane 노드 제거를 명시적으로 차단합니다. 즉 first_kube_control_plane 변수가 할당된 노드에 대한 삭제 요청을 거부합니다.
따라서 첫 번째 Control Plane 노드를 교체하려면 다른 노드에게 first_kube_control_plane 역할을 먼저 위임한 후 기존 노드를 제거해야 합니다. 이를 위해 대상 노드를 첫 번째 위치로 이동시키고 기존의 첫 번째 노드를 하위로 배치합니다.
# 인벤토리 파일 백업
cp inventory/mycluster/inventory.ini inventory/mycluster/inventory.ini.backup
# 첫 번째 노드를 다른 위치로 이동
cat << EOF > inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
EOF
inventory 재정렬 후 upgrade-cluster.yml playbook을 실행하면 Kubespray는 새로운 first_kube_control_plane을 기준으로 클러스터 구성을 재구성합니다. 이 playbook은 upgrade를 목적으로 설계되었지만, Control Plane 구성 동기화 작업도 수행하므로 역할 위임 시나리오에서 활용할 수 있습니다.
ansible-playbook -i inventory/mycluster/inventory.ini -v upgrade-cluster.yml -e kube_version="1.32.9" | tee kubespray_upgrade.log
upgrade-cluster.yml이 수행하는 주요 작업은 etcd endpoint 목록에서 k8s-node2를 첫 번째로 배치하고, 모든 Control Plane 노드의 kube-apiserver, kube-controller-manager, kube-scheduler 설정이 새로운 endpoint를 참조하도록 업데이트됩니다.
External Load Balancer를 사용하는 환경에서는 controlPlaneEndpoint가 변경되지 않으며, 오직 etcd endpoint 목록의 순서만 재정렬됩니다.
 kubectl get cm kubeadm-config -n kube-system -o jsonpath=’{.data.ClusterConfiguration}’ | grep -A 5 “endpoints:”
kubectl get cm kubeadm-config -n kube-system -o jsonpath=’{.data.ClusterConfiguration}’ | grep -A 5 “endpoints:”
upgrade-cluster.yml 실행으로 역할 위임이 완료되었으므로, 이제 기존 첫 번째 노드(k8s-node1)는 일반 Control Plane 노드로 취급됩니다. 이 상태에서 remove-node.yml을 실행하면 차단 없이 제거가 가능합니다.
ansible-playbook -i inventory/mycluster/inventory.ini remove-node.yml -e node=k8s-node1
 kubectl get node -o wide
kubectl get node -o wide
kubeadm-config나 etcd endpoints 등은 여전히 이전 k8s-node1을 가리킬 수 있습니다.
기존 첫 번째 노드(k8s-node1)를 Inventory에서 제거하고, kubeadm-config나 etcd endpoints에 남아있을 수 있는 k8s-node1 내용을 정리합니다.
cat << EOF > inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
EOF
etcd 클러스터는 quorum을 유지하기 위해 홀수로 구성되어야 합니다. 따라서 임시로 etcd 검증을 우회합니다.
ansible-playbook -i inventory/mycluster/inventory.ini upgrade-cluster.yml \
-e kube_version="1.32.9" \
-e ignore_assert_errors=true
완료된 후에 이제 새로운 노드(k8s-node6)를 Control Plane에 추가할 수 있습니다.
이를 위해 기존에 생성되어 있던 VM을 내리고 다시 업데이트합니다.
vagrant destroy -f k8s-node1 후에, 아래와 같이 Vagrantfile을 업데이트합니다.
# Base Image https://portal.cloud.hashicorp.com/vagrant/discover/bento/rockylinux-10.0
BOX_IMAGE = "bento/rockylinux-10.0" # "bento/rockylinux-9"
BOX_VERSION = "202510.26.0"
N = 6 # max number of Node
Vagrant.configure("2") do |config|
# Nodes
(2..N).each do |i|
config.vm.define "k8s-node#{i}" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Kubespray-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "k8s-node#{i}"
vb.cpus = 4
vb.memory = 2048
vb.linked_clone = true
end
subconfig.vm.host_name = "k8s-node#{i}"
subconfig.vm.network "private_network", ip: "192.168.10.1#{i}"
subconfig.vm.network "forwarded_port", guest: 22, host: "6000#{i}", auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "init_cfg.sh", args: N.to_s
end
end
# Admin & LoadBalancer Node
config.vm.define "admin-lb" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Kubespray-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "admin-lb"
vb.cpus = 2
vb.memory = 1024
vb.linked_clone = true
end
subconfig.vm.host_name = "admin-lb"
subconfig.vm.network "private_network", ip: "192.168.10.10"
subconfig.vm.network "forwarded_port", guest: 22, host: "60000", auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "admin-lb.sh", args: N.to_s
end
end
# k8s-node6 생성
vagrant up k8s-node6
VM이 구동되었다면 admin-lb 내부에서 일부 파일을 수정합니다.
# host 추가
echo "192.168.10.16 k8s-node6" >> /etc/hosts
# ssh 설정
sshpass -p 'qwe123' ssh-copy-id -o StrictHostKeyChecking=no root@192.168.10.16
sshpass -p 'qwe123' ssh -o StrictHostKeyChecking=no root@k8s-node6
# HAProxy 설정 변경
sudo sed -i 's/192.168.10.11/192.168.10.16/g' /etc/haproxy/haproxy.cfg
sudo sed -i 's/node1/node6/g' /etc/haproxy/haproxy.cfg
# HAProxy service 재시작
sudo systemctl restart haproxy
inventory 파일에서 k8s-node6을 kube_control_plane 그룹으로 배치합니다.
cat << EOF > inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
k8s-node6 ansible_host=192.168.10.16 ip=192.168.10.16 etcd_member_name=etcd1
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14
k8s-node5 ansible_host=192.168.10.15 ip=192.168.10.15
EOF
이제 새 노드를 기존 클러스터에 join시키기 위해 cluster.yml을 실행합니다.
ansible-playbook -i inventory/mycluster/inventory.ini cluster.yml -e kube_version="1.32.9"
scale.yml이 아니라 cluster.yml로 실행시키는 이유는 scale.yml이 Control Plane/etcd 노드를 위해서 설계되지 않았으며, 또한 공식 문서에서도 아래와 같이 명시하고 있습니다.
“Append the new host to the inventory and run cluster.yml. You can NOT use scale.yml for that.”
Control Plane이 추가되었는지 확인합니다.
 kubectl get node -o wide
kubectl get node -o wide
Recover Control Plane/Etcd
Kubernetes Control Plane 노드 장애는 클러스터의 가용성에 치명적인 영향을 미치며, 이러한 상황에서 신속한 복구는 운영의 핵심 요구사항입니다. Kubespray의 recover-control-plane.yml playbook은 etcd quorum 상실, Control Plane 노드 장애, etcd database corruption 등 다양한 장애 시나리오에서 복구 프로세스를 자동화하도록 설계되었습니다.
이 playbook은 단순히 노드를 재시작하는 것이 아니라, etcd cluster 재구성, broken 멤버 제거, 인증서 재발급, API Server manifest 업데이트 등 일련의 복잡한 작업을 순차적으로 수행합니다. 특히 이 과정은 최소 하나의 기능성 노드가 존재해야만 수행 가능하며, 전체 클러스터를 재배포하지 않고도 손상된 구성요소만을 대상으로 복구를 수행한다는 점에서 업그레이드와는 명확히 구분됩니다.
Scenario
kubespray의 control plane 복구 문서를 기반으로 실제 장애 상황 시나리오를 구성하겠습니다. 위의 실습과 환경 자체는 동일하나 k8s-node6이 k8s-node1으로 변경되었습니다.
# 현재 etcd member 확인
ssh k8s-node2 << 'EOF'
ETCDCTL_API=3 etcdctl \
--endpoints=https://k8s-node1:2379,https://k8s-node2:2379,https://k8s-node3:2379 \
--cacert=/etc/ssl/etcd/ssl/ca.pem \
--cert=/etc/ssl/etcd/ssl/admin-k8s-node2.pem \
--key=/etc/ssl/etcd/ssl/admin-k8s-node2-key.pem \
endpoint health -w table
EOF
# control plane pods 확인
kubectl get pods -n kube-system | grep k8s-node1
etcd member health check
 check running static pods in k8s-node1
check running static pods in k8s-node1
k8s-node1의 Control Plane과 etcd에 대해 아래 명령어를 실행함으로써 장애를 발생시킵니다.
# Kubelet 중단
ssh k8s-node1 << 'EOF'
sudo systemctl stop kubelet
sudo systemctl disable kubelet
EOF
# etcd 중단 및 데이터 삭제
ssh k8s-node1 << 'EOF'
sudo systemctl stop etcd
sudo systemctl disable etcd
sudo rm -rf /var/lib/etcd/member
sudo rm -rf /etc/ssl/etcd/ssl/member-k8s-node1*
sudo rm -rf /etc/ssl/etcd/ssl/node-k8s-node1*
sudo rm -rf /etc/ssl/etcd/ssl/admin-k8s-node1*
EOF
# control plane 컨테이너 종료
ssh k8s-node1 << 'EOF'
sudo systemctl stop containerd
EOF
k8s-node1 etcd의 health 상태가 false로 바뀐 것을 확인할 수 있습니다.
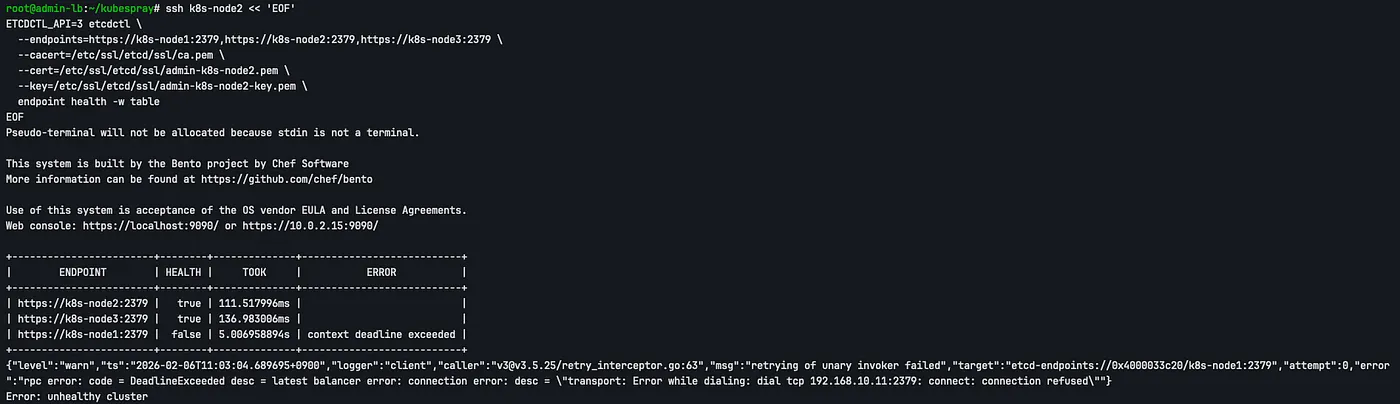 check etcd health in k8s-node1
check etcd health in k8s-node1
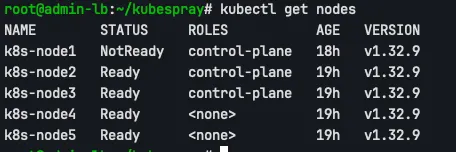 check NotReady status in k8s-node1
check NotReady status in k8s-node1
복구 작업을 시작하기 전에 사용자가 장애 노드를 inventory에 추가해야 합니다. Kubespray는 기본 inventory에 broken_etcd와 broken_kube_control_plane 그룹을 포함하고 있지 않으므로, 복구 대상 노드를 명시적으로 선정해야 합니다.
# /root/kubespray/inventory/mycluster/inventory.ini
[kube_control_plane]
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
[etcd:children]
kube_control_plane
# 사용자가 추가한 그룹 (장애 노드 포함)
[broken_etcd]
k8s-node1
[broken_kube_control_plane]
k8s-node1
broken_etcd 그룹은 etcd 멤버로 동작하는 Control Plane 노드를 포함하며, broken_kube_control_plane 그룹은 Control Plane 역할을 수행하는 노드를 포함합니다. Kubespray HA 구성에서는 모든 Control Plane 노드가 etcd 멤버로도 동작하므로, 두 그룹은 중복될 수 있습니다.
Recover etcd
# /root/kubespray/playbooks/recover_control_plane.yml
---
- name: Common tasks for every playbooks
import_playbook: boilerplate.yml
- name: Recover etcd
hosts: etcd[0]
environment: "{{ proxy_disable_env }}"
roles:
- { role: kubespray_defaults}
- role: recover_control_plane/etcd
when: etcd_deployment_type != "kubeadm"
Kubespray는 etcd를 배포하는 세 가지 방법을 지원하며, 이는 etcd_deployment_type 변수로 제어됩니다. 이 변수는 group_vars/all/etcd.yml에서 설정 가능하며, 기본값은 host입니다.
- host: systemd service로 etcd를 실행. 실습 환경과 대부분의 프로덕션 환경에서 사용
- docker: Docker container로 etcd 실행. container_manager: docker일 때만 사용 가능
- kubeadm: kubeadm이 관리하는 static pod로 etcd 실행, experimental 기능
kubeadm인 경우, recover_control_plane/etcd_role은 실행되지 않습니다. kubeadm이 관리하는 etcd는 kubeadm의 복구 메커니즘(kubeadm reset, kubeadm init)을 사용해야 합니다.
Recover etcd play가 etcd[0](첫 번째 etcd 노드)에서 실행되며, 다음 순서로 복구 작업을 수행합니다.
# /root/kubespray/extra_playbooks/roles/recover_control_plane/etcd/tasks/main.yml
- name: Set healthy fact
set_fact:
healthy: "{{ etcd_endpoint_health.stderr is match('Error: unhealthy cluster') }}"
when:
- groups['broken_etcd']
- name: Set has_quorum fact
set_fact:
has_quorum: "{{ etcd_endpoint_health.stdout_lines | select('match', '.*is healthy.*') | list | length >= etcd_endpoint_health.stderr_lines | select('match', '.*is unhealthy.*') | list | length }}"
when:
- groups['broken_etcd']
- name: Recover lost etcd quorum
include_tasks: recover_lost_quorum.yml
when:
- groups['broken_etcd']
- not has_quorum
- name: Remove broken cluster members
command: "{{ bin_dir }}/etcdctl member remove {{ item[1].replace(' ', '').split(',')[0] }}"
environment:
ETCDCTL_API: "3"
ETCDCTL_ENDPOINTS: "{{ etcd_access_addresses }}"
ETCDCTL_CERT: "{{ etcd_cert_dir }}/admin-{{ inventory_hostname }}.pem"
ETCDCTL_KEY: "{{ etcd_cert_dir }}/admin-{{ inventory_hostname }}-key.pem"
ETCDCTL_CACERT: "{{ etcd_cert_dir }}/ca.pem"
with_nested:
- "{{ groups['broken_etcd'] }}"
- "{{ member_list.stdout_lines }}"
when:
- groups['broken_etcd']
- not healthy
- has_quorum
- hostvars[item[0]]['etcd_member_name'] == item[1].replace(' ', '').split(',')[2]
- etcd cluster health 확인: 사용자가 inventory에 broken_etcd 그룹을 추가했는지 확인합니다. 이 그룹이 존재하지 않으면 etcd 복구 작업은 실행되지 않습니다.
- quorum 상태 판단: etcd 클러스터의 상태를 health, healthy endpoint 수가 unhealthy endpoint 수보다 크거나 같은지 판단하여 has_quorum fact를 저장합니다.
- quorum 손실 시, snapshot 복구: quorum이 손실된 경우에만 snapshot 복구를 수행합니다.
- quorum이 유지된 경우에만 broken 멤버를 제거합니다.
현재는 k8s-node1에서만 장애가 발생하여서 quorum이 유지되고 있기 때문에 snapshot이 복구되지 않고 broken 멤버 제거 후에 인증서를 재생성하고, etcd 재시작 및 클러스터에 다시 Join됩니다.
Recover control plane
- name: Recover control plane
hosts: kube_control_plane[0]
environment: "{{ proxy_disable_env }}"
roles:
- { role: kubespray_defaults}
- { role: recover_control_plane/control-plane }
Recover control plane play도 kube_control_plane[0](첫 번째 Control Plane 노드)에서 실행됩니다.
# /root/kubespray/extra_playbooks/roles/recover_control_plane/control-plane/tasks/main.yml
- name: Wait for apiserver
command: "{{ kubectl }} get nodes"
environment:
KUBECONFIG: "{{ ansible_env.HOME | default('/root') }}/.kube/config"
register: apiserver_is_ready
until: apiserver_is_ready.rc == 0
retries: 6
delay: 10
changed_when: false
when: groups['broken_kube_control_plane']
- name: Delete broken kube_control_plane nodes from cluster
command: "{{ kubectl }} delete node {{ item }}"
environment:
KUBECONFIG: "{{ ansible_env.HOME | default('/root') }}/.kube/config"
with_items: "{{ groups['broken_kube_control_plane'] }}"
register: delete_broken_kube_control_plane_nodes
failed_when: false
when: groups['broken_kube_control_plane']
사용자가 inventory에 broken_kube_control_plane 그룹을 추가했는지 확인한 후에, 그룹 내의 노드를 순회하며 kubectl delete node 명령어를 실행합니다.
# /root/kubespray/playbooks/recover_control_plane.yml
- name: Apply whole cluster install
import_playbook: cluster.yml
이후 cluster.yml을 통해 새로운 노드를 클러스터에 onboarding하고 전체 구성요소의 정합성을 검증합니다. 이 play는 etcd 복구와 node 삭제 후에 실행되므로, 클러스터의 상태를 재동기화합니다.
실제 장애를 해결하기 위해 recover_control_plane.yml을 실행합니다.
ansible-playbook -i inventory/mycluster/inventory.ini -v playbooks/recover_control_plane.yml --limit etcd,kube_control_plane
이후 정상적으로 etcd와 Control Plane의 static pods가 구동되는 것을 확인할 수 있습니다.
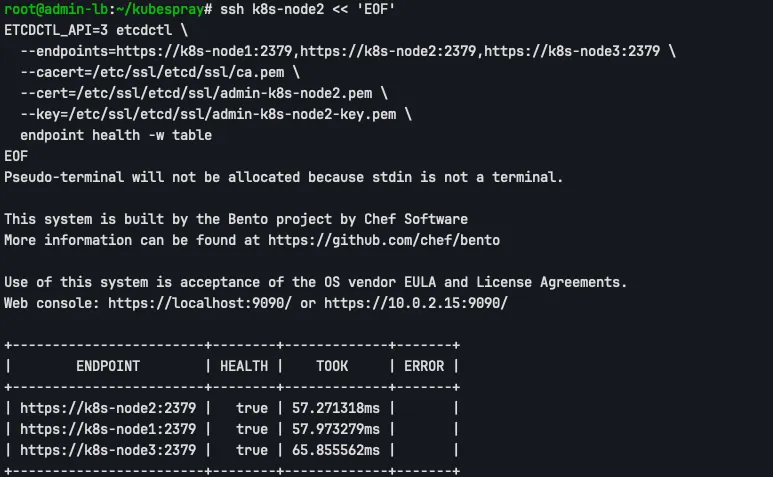 check etcd health in k8s-node1
check etcd health in k8s-node1
 kubectl get pods -n kube-system | grep k8s-node1
kubectl get pods -n kube-system | grep k8s-node1
Comments