15 min to read
Attention Mechanism Optimization for Efficient LLM Inference
Introduction
대규모 언어 모델(LLM)이 널리 보급되면서, 추론(Inference) 효율성은 실제 서비스 배포에서 가장 중요한 기술적 과제 중 하나가 되었습니다. 특히 Self-Attention 메커니즘은 트랜스포머 아키텍처의 핵심이지만, 동시에 메모리 대역폭과 용량 측면에서 주요 병목 지점이 됩니다. 본 글에서는 LLM 추론 시 발생하는 메모리 병목 문제를 분석하고, 이를 해결하기 위한 Multi-Query Attention(MQA), Grouped-Query Attention(GQA), 그리고 FlashAttention과 같은 최적화 기법들을 정리해보겠습니다.
MoE(Mixture of Experts)와 PagedAttention(vLLM)은 각각 모델 아키텍처와 메모리 관리 차원의 최적화로, Attention 메커니즘 자체의 최적화와는 성격이 다릅니다. 이들은 별도의 글에서 다루겠습니다.
본론에 들어가기 전에, 먼저 이 모든 최적화의 대상인 Self-Attention이 어떻게 동작하는지 간략히 짚어보겠습니다.
Background: Scaled Dot-Product Attention
Transformer의 핵심 연산인 Scaled Dot-Product Attention은 다음 수식으로 정의됩니다.
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]여기서 $Q$(Query), $K$(Key), $V$(Value)는 입력 토큰들의 임베딩을 각각의 가중치 행렬 $W_Q$, $W_K$, $W_V$로 선형 변환한 결과입니다. 분모의 $\sqrt{d_k}$는 단순한 상수가 아니라 학습 안정성에 필수적인 스케일링 팩터입니다. 내적 값의 분산은 벡터 차원 $d_k$에 비례하여 커지는데, 스케일링 없이 큰 값이 softmax에 들어가면 gradient가 극도로 작아지는(vanishing gradient) 문제가 발생합니다.
Multi-Head Attention(MHA)은 이 연산을 $h$개의 독립적인 헤드로 병렬 수행합니다. 각 헤드는 서로 다른 $W_Q^i$, $W_K^i$, $W_V^i$를 가지며, 입력의 서로 다른 관계 패턴(문법적 구조, 의미적 유사성, 시간적 순서 등)을 포착합니다.
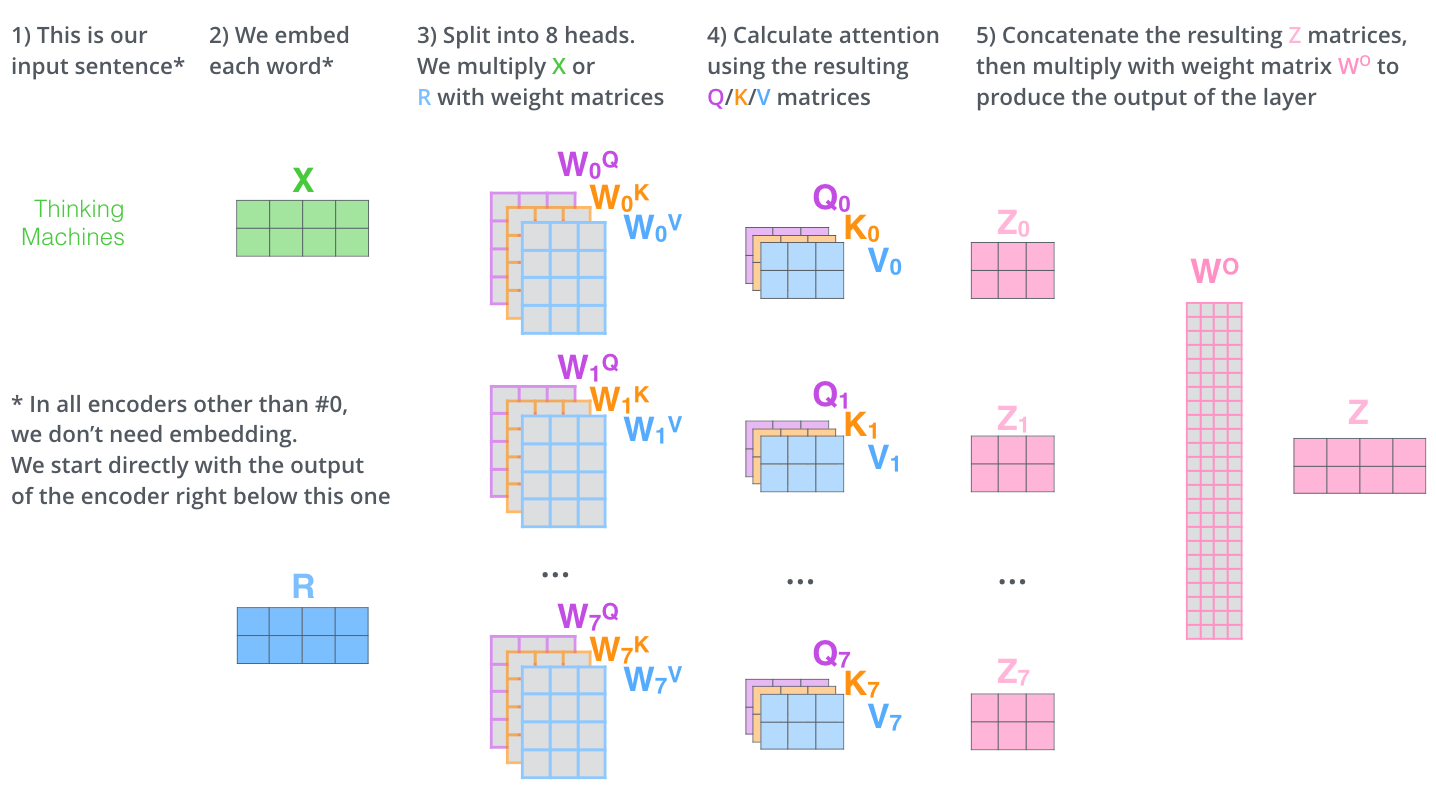 https://jalammar.github.io/illustrated-transformer/
https://jalammar.github.io/illustrated-transformer/
Role of KV Cache
LLM이 텍스트를 생성할 때, 각 토큰의 $K$와 $V$는 한 번 계산되면 이후 모든 토큰의 attention 계산에 재사용됩니다.
입력 문장이 “I love AI”라고 가정해 봅시다. 각 토큰은 자신의 $Q$를 통해 다른 모든 토큰의 $K$와 attention 점수를 계산하고, 이를 가중치로 $V$를 가중 합산합니다.
“I”의 관점에서 Attention 계산:
- $Q_{I}K_{I}^{T}$ (자기 자신 확인)
- $Q_{I}K_{love}^{T}$ (“love”의 $K$ 사용)
- $Q_{I}K_{AI}^{T}$ (“AI”의 $K$ 사용)
이때 중요한 점은 각 토큰의 $K$와 $V$가 한 번만 계산되고 다른 토큰들의 attention 계산 시 재사용된다는 것입니다.
이 재사용 특성 덕분에, 이미 계산한 $K$와 $V$를 GPU 메모리에 캐싱해두면 중복 계산을 피할 수 있습니다. 이것이 KV Cache입니다. KV Cache는 추론 속도를 크게 높여주지만, 시퀀스가 길어지고 배치 크기가 커질수록 GPU 메모리를 빠르게 소진하게 되므로 Trade-off 측면이 있습니다.
Two Phases of Inference
LLM 추론은 두 가지 단계로 나뉩니다.
Prefill
Prefill 단계에서는 입력 프롬프트의 모든 토큰을 한 번에 처리합니다. 예를 들어 “Translate to French: Hello”라는 5개 토큰이 주어지면, 5개 토큰의 $K$, $V$를 동시에 계산하여 KV Cache에 저장합니다. 이 단계는 주로 대규모 행렬 연산(GEMM, General Matrix Multiplication)으로 구성되며, GPU에서 Compute-bound를 보이는 구간입니다.
- Input: “Translate to French: Hello” (5 tokens)
- Process: 5개 토큰의 $K, V$를 동시에 계산 (병렬 연산)
Token 1$\rightarrow$ $K_1, V_1$Token 2$\rightarrow$ $K_2, V_2$...Token 5$\rightarrow$ $K_5, V_5$
Decode
Decode 단계에서는 토큰을 하나씩 순차적으로 생성합니다. 새 토큰의 $Q_{new}$를 생성하고, KV Cache에 저장된 모든 $K$, $V$와 attention을 계산하여 다음 토큰을 예측한 뒤, 새 토큰의 $K$, $V$를 다시 Cache에 추가합니다. 이 과정이 반복되면서 Cache는 점점 커져갑니다. 이 단계가 추론 시간의 대부분을 차지하며, 바로 여기서 메모리 병목이 발생합니다.
Step 1: 첫 번째 단어 생성
- Query: 마지막 토큰(“Hello”) 또는 Start 토큰에서 $Q_{new}$ 생성
- Attention: $Q_{new}$와 [Cache: $K_1 \dots K_5$] 연산
- Result: “Bon” 생성 ($Token_6$)
- Update: “Bon”의 $K_6, V_6$를 계산하여 Cache에 추가(Append)
Step 2: 두 번째 단어 생성
- Query: 방금 만든 “Bon”에서 $Q_{new}$ 생성
- Attention: $Q_{new}$와 [Cache: $K_1 \dots K_6$] 연산 (범위가 늘어남)
- Result: “jour” 생성 ($Token_7$)
- Update: “jour”의 $K_7, V_7$를 계산하여 Cache에 추가
Step 3 … N:
- 이 과정을 반복하며 Cache는 계속 커집니다. ($K_{1\dots N}, V_{1\dots N}$)
Why Decode is Memory-bound
이 차이를 정량적으로 이해하려면 Arithmetic Intensity(연산 강도) 개념이 필요합니다.
\[\text{Arithmetic Intensity} = \frac{\text{연산량 (FLOPs)}}{\text{메모리 접근량 (Bytes)}}\]Prefill의 행렬 간 연산이며, 아래와 같이 계산됩니다.
\[S = QK^T, \quad Q \in \mathbb{R}^{N \times d}, \quad K^T \in \mathbb{R}^{d \times N} \;\Rightarrow\; S \in \mathbb{R}^{N \times N}\] \[S_{ij} = \sum_{k=1}^{d} Q_{ik} K_{jk}\]원소 하나는 길이 $d$ 내적이므로
\[\text{FLOPs } S_{ij} \approx 2d\]출력 원소가 $N^2$개이므로
\[\text{FLOPs} \approx N^2 \cdot 2d = 2N^2 d\]입력으로 읽는 요소 수는
\[Q: Nd, \quad K: Nd \;\Rightarrow\; 2Nd \text{ elements}\]dtype 크기가 $\text{sizeof(dtype)}$ bytes이면
\[\text{Bytes read} = 2Nd \cdot \text{sizeof(dtype)}\]FP16의 경우 element당 2 bytes이므로 $\text{Bytes read} = 4Nd$
따라서 Arithmetic Intensity는
\[\text{Arithmetic_Intensity}_{\text{prefill}} = \frac{2N^2 d}{2Nd \cdot \text{sizeof(dtype)}} = \frac{N}{\text{sizeof(dtype)}} = O(N)\]즉 $N$이 커질수록 연산강도가 선형 증가하므로 Prefill 단계는 Compute-bound 특성을 가집니다.
Decode 단계에서는 현재 토큰의 query 벡터 \(q \in \mathbb{R}^{1 \times d}\)와 캐시된 \(K^T \in \mathbb{R}^{d \times N}\) 를 곱합니다. 결과는 \(s \in \mathbb{R}^{1 \times N}\)이며, 각 원소는 \(s_j = \sum_{k=1}^{d} q_k K_{jk}\)로 계산됩니다.
원소 하나는 길이 $d$ 내적이므로
\[\text{FLOPs } s_j \approx 2d\]출력 원소는 $N$개이므로
\[\text{FLOPs} \approx 2Nd\]입력으로 읽는 데이터는
\[q: d,\quad K: Nd \;\Rightarrow\; Nd + d \approx Nd \text{ elements}\]따라서 메모리 읽기 바이트 수는
\[\text{Bytes read} = Nd \cdot \text{sizeof(dtype)}\]Arithmetic Intensity는
\[\text{Arithmetic_Intensity}_{\text{decode}} = \frac{2Nd}{Nd \cdot \text{sizeof(dtype)}} = \frac{2}{\text{sizeof(dtype)}} = O(1)\]즉, 시퀀스 길이 $N$이 증가해도 연산강도는 상수 수준에 머뭅니다. 따라서 Decode 단계는 메모리 대역폭에 의해 제한되는 Memory-bound 특성을 갖습니다.
GPU Memory Hierarchy and Memory Wall
이 문제를 더 깊이 이해하려면 GPU의 메모리 계층 구조를 알아야 합니다.
- HBM (High Bandwidth Memory): GPU의 메인 메모리입니다 (예: A100 80GB, H100 80GB). 용량은 크지만 연산 유닛과의 대역폭이 상대적으로 제한됩니다.
- SRAM: GPU 칩 내부 Streaming Multiprocessor에 위치한 작은 메모리입니다 (약 20MB). 용량은 극히 작지만 HBM보다 약 10배 이상 빠릅니다.
Decode 단계에서 매 토큰 생성마다, HBM에 저장된 거대한 KV Cache 전체를 연산 유닛 가까이로 읽어와야 합니다. 행렬 곱셈 자체는 빠르지만, 데이터를 불러오는 시간이 병목이 되어 GPU의 실제 연산 활용률이 극히 낮아집니다. 이것을 Memory Wall 문제라고 합니다.
Actual KV Cache Size: Why It Matters
KV Cache가 실제로 얼마나 큰지 계산해보면 문제를 실감할 수 있습니다. 전통적인 Dense Transformer 기반의 가상 120B 모델을 가정하겠습니다.
| 구성 요소 | 값 |
|---|---|
| Parameters | 120B |
| Layers | 80 |
| Attention Heads | 64 |
| Head Dimension | 128 |
토큰 1개당 KV Cache 크기 (FP16):
\[\underbrace{2}_{\text{K와 V}} \times \underbrace{2}_{\text{FP16 bytes}} \times \underbrace{80}_{\text{layers}} \times \underbrace{64}_{\text{heads}} \times \underbrace{128}_{\text{head dim}} = 2{,}621{,}440 \text{ Bytes} \approx 2.5 \text{ MB/token}\]128명의 동시 사용자가 각각 2,048 토큰을 사용하면:
\[128 \times 2{,}048 \times 2.5 \text{ MB} \approx 640 \text{ GB}\]모델 가중치 자체가 $120\text{B} \times 2\text{ bytes} = 240\text{ GB}$인데, KV Cache만 640 GB라서 — KV Cache가 모델 가중치의 2.7배에 달합니다. 즉 120B모델을 기반으로 서비스를 운영하기 위해서는 H100 80GB 기준으로 총 880 GB이면 약 11대가 필요하게 됩니다.
핵심은 MHA에서 KV Cache 크기가 헤드 수에 정비례한다는 점입니다. 64개 헤드 각각이 독립적인 $K$, $V$를 저장하기 때문입니다. 이를 해결하고자 나온 기법이 MQA와 GQA입니다.
Multi-Query Attention (MQA)
2019년 Noam Shazeer가 제안한 Multi-Query Attention(MQA)에서는 Key/Value를 헤드마다 따로 둘 필요가 있는지에 대해 설계 자체를 재검토합니다.
Attention의 동작을 두 단계로 분해해 보겠습니다.
- “어디를 볼 것인가” — $Q$와 $K$의 내적으로 각 위치의 중요도를 계산합니다.
- “무엇을 가져올 것인가” — 계산된 가중치로 $V$를 가중 합산하여 정보를 추출합니다.
여기서 “어디를 볼지”를 결정하는 것은 전적으로 Query입니다. 같은 $K$, $V$ 저장소가 주어져도, 서로 다른 Query는 서로 다른 위치에 집중하여 서로 다른 정보를 추출할 수 있습니다.
이를 바탕으로 MQA는 Query만 헤드별로 유지하고, Key와 Value는 모든 헤드가 하나를 공유하도록 설계합니다.
Comparison
MHA와 MQA의 텐서 구조를 비교하면 차이가 명확합니다.
MHA (h=8 heads):
Q: [batch, seq, h, d_k] ← 헤드마다 독립
K: [batch, seq, h, d_k] ← 헤드마다 독립
V: [batch, seq, h, d_k] ← 헤드마다 독립
MQA (h=8 heads):
Q: [batch, seq, h, d_k] ← 헤드마다 독립 (유지)
K: [batch, seq, 1, d_k] ← 전체 공유 → broadcast
V: [batch, seq, 1, d_k] ← 전체 공유 → broadcast
Forward pass에서 공유된 $K$, $V$는 각 Query 헤드에 broadcast되어 연산됩니다. KV Cache 크기는 정확히 헤드 수($h$)배만큼 감소합니다.
\[\text{KV Cache} = \frac{\text{MQA}}{\text{MHA}} = \frac{1}{h}\]앞선 120B 모델 예시에서 $h = 64$이므로, KV Cache가 640 GB에서 10 GB로 줄어듭니다.
Limitations
MQA의 표현력 감소는 태스크 복잡도에 따라 다르게 나타납니다. 번역처럼 비교적 단순한 태스크에서는 품질 저하가 미미하지만, 복잡한 추론이 필요한 태스크에서는 2~3%의 성능 하락이 관찰되었습니다. 여러 헤드가 주어-동사 관계, 대명사 참조, 시간적 순서 등 서로 다른 종류의 정보를 동시에 포착해야 할 때, 하나의 KV 저장소로는 각 헤드가 담당하던 정보가 희석될 수 있기 때문입니다.
또한, MQA는 학습된 가중치 구조 자체가 MHA와 다르므로, 기존 MHA 모델에 추론 시점에서 단순히 K, V 가중치를 합치는 방식으로 전환할 수는 없습니다. 처음부터 MQA 구조로 학습하거나, 후술할 GQA의 uptraining 기법이 필요합니다.
Grouped-Query Attention (GQA)
Balance Between MHA and MQA
MQA가 극단적으로 하나의 KV 헤드만 사용한다면, GQA는 Query 헤드들을 그룹으로 묶어 각 그룹이 하나의 KV 쌍을 공유하는 절충안입니다. 2023년 Ainslie 등이 발표한 GQA 논문에서는 이를 일반화된 프레임워크로 정리했습니다.
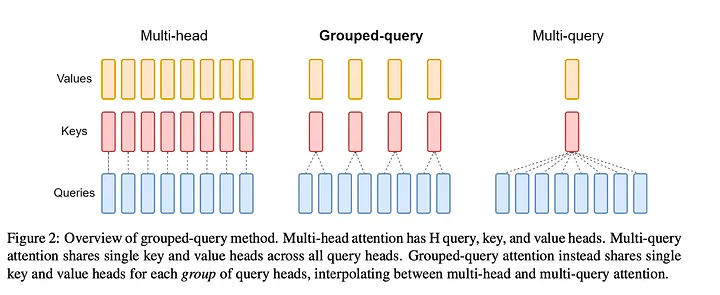 https://arxiv.org/pdf/2305.13245
https://arxiv.org/pdf/2305.13245
아래에서 $G = 1$이면 MQA, $G = h$이면 MHA와 동일합니다. 즉 GQA는 MQA와 MHA를 양 끝으로 하는 연속적인 스펙트럼입니다.
MHA (G=h): Q₁→KV₁ Q₂→KV₂ Q₃→KV₃ Q₄→KV₄ Q₅→KV₅ Q₆→KV₆ Q₇→KV₇ Q₈→KV₈
GQA (G=2): Q₁→KV₁ Q₂→KV₁ Q₃→KV₁ Q₄→KV₁ Q₅→KV₂ Q₆→KV₂ Q₇→KV₂ Q₈→KV₂
MQA (G=1): Q₁→KV₁ Q₂→KV₁ Q₃→KV₁ Q₄→KV₁ Q₅→KV₁ Q₆→KV₁ Q₇→KV₁ Q₈→KV₁
Uptraining
GQA 논문의 중요한 기여 중 하나는 이미 MHA로 학습된 체크포인트를 GQA로 전환하는 uptraining 기법입니다. 각 그룹에 속하는 기존 KV 헤드들의 가중치를 평균(mean pooling)하여 그룹의 초기 KV 가중치를 만든 뒤, 원래 학습량의 약 5%만 추가 학습하면 성능이 상당 부분 회복되는 것으로 논문에서 말하고 있습니다. 이 덕분에 처음부터 다시 학습할 필요 없이 기존 모델을 효율적으로 전환할 수 있습니다.
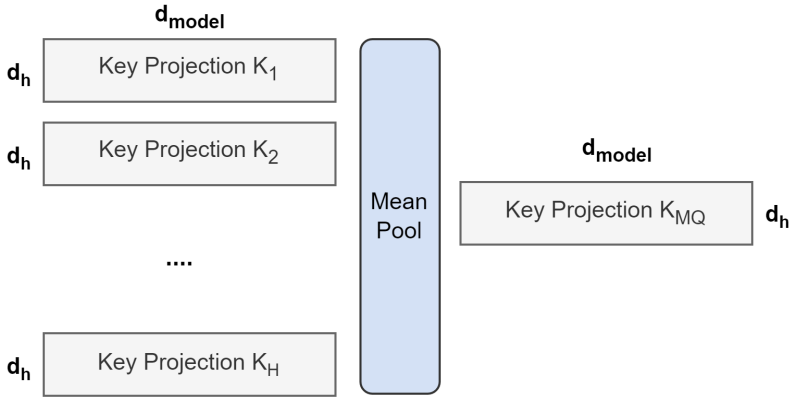 https://arxiv.org/pdf/2305.13245
https://arxiv.org/pdf/2305.13245
Trend
최근 LLM들은 추론 효율을 위해 GQA를 표준처럼 채택하고 있습니다.
| 모델 | Query 헤드 $H$ | KV 헤드 $H_{kv}$ | KV Cache 절감 $\approx H/H_{kv}$ |
|---|---|---|---|
| LLaMA 3.1 8B | 32 | 8 | 4배 |
| LLaMA 3.1 70B | 64 | 8 | 8배 |
| gpt-oss-120b | 64 | 8 | 8배 |
| Qwen 3.5-27B | 24 | 4 | 6배 |
| Qwen 3.5-35B-A3B (MoE) | 16 | 2 | 8배 |
FlashAttention
MQA/GQA가 저장해야 할 KV Cache의 총량을 줄였다면, FlashAttention은 완전히 다른 축을 공략합니다. KV Cache 크기와 무관하게, 데이터가 GPU 메모리 계층 사이를 오가는 횟수(IO)를 줄여 연산 속도를 높이는 접근법입니다. 학습과 추론 모두에 적용됩니다.
GPU가 실제로 계산을 수행하려면, 데이터를 HBM에서 SRAM으로 가져와야 합니다. 계산 자체는 빠르지만, 이 데이터 이동에 시간이 걸립니다. 이는 앞서 다룬 Memory Wall 문제입니다.
Kernel Fusion
GPU 커널(Kernel)은 GPU에서 실행되는 하나의 작업 단위입니다. 일반적인 PyTorch 코드에서 torch.matmul(Q, K.T), torch.softmax(S), torch.matmul(P, V)는 각각 별도의 커널로 실행됩니다. 각 커널은 독립적으로 HBM에서 데이터를 읽고, 결과를 HBM에 씁니다.
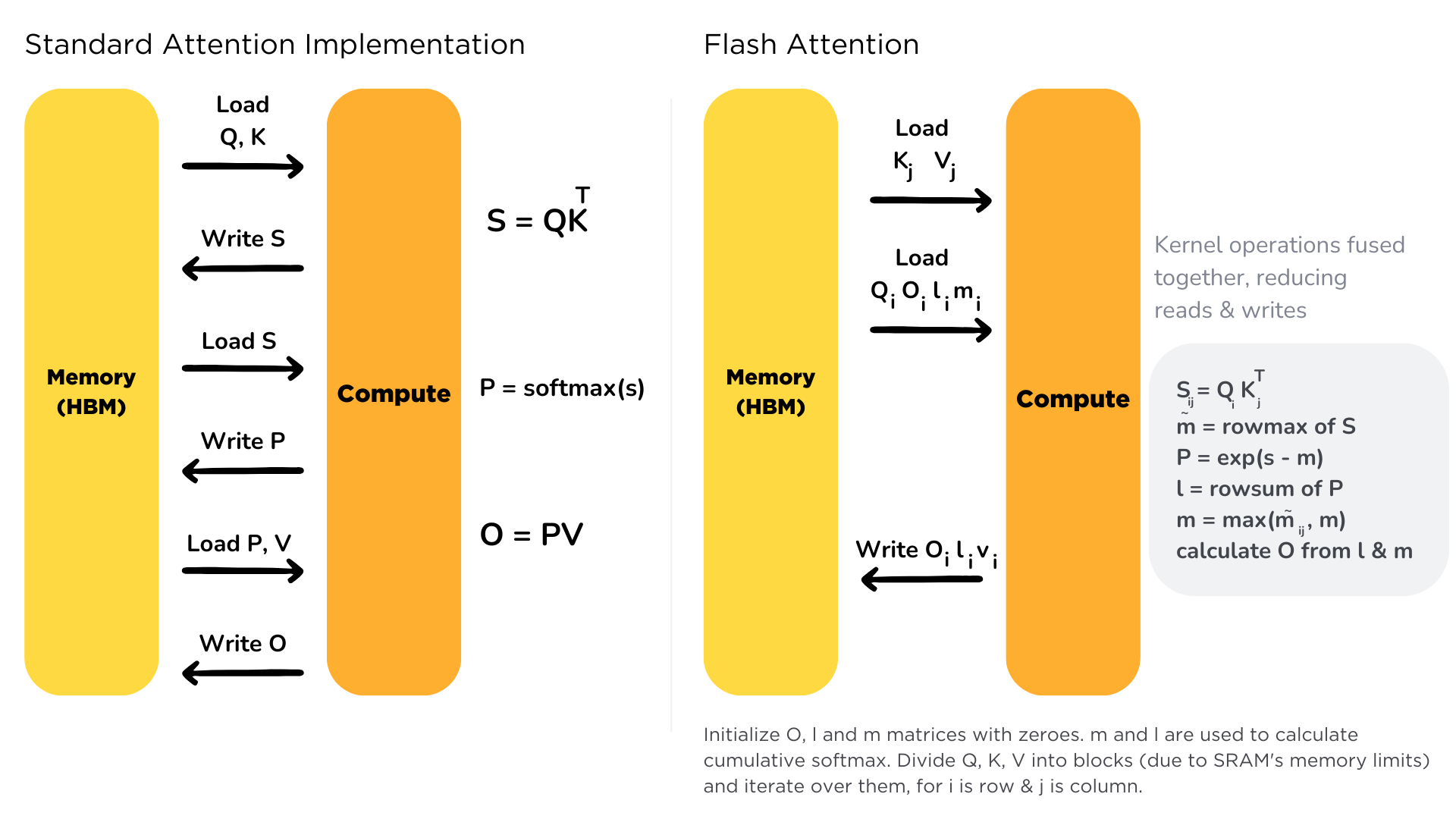
| Stage | Kernel | Memory I/O |
|---|---|---|
| Step 1 | Kernel 1 | Load $Q, K$ from HBM |
| Step 1 | Kernel 1 | Compute $S = QK^T / \sqrt{d_k}$ |
| Step 1 | Kernel 1 | Write $S$ to HBM |
| Step 2 | Kernel 2 | Load $S$ from HBM |
| Step 2 | Kernel 2 | Compute $P = \text{softmax}(S)$ |
| Step 2 | Kernel 2 | Write $P$ to HBM |
| Step 3 | Kernel 3 | Load $P, V$ from HBM |
| Step 3 | Kernel 3 | Compute $O = PV$ |
| Step 3 | Kernel 3 | Write $O$ to HBM |
Attention 구현에서는 다음 세 단계를 순차적으로 수행합니다.
- $S = QK^T / \sqrt{d_k}$ 계산 → $N \times N$ 행렬 $S$를 HBM에 저장
- HBM에서 $S$를 다시 읽어 $P = \text{softmax}(S)$ 계산 → $N \times N$ 행렬 $P$를 HBM에 저장
- HBM에서 $P$를 다시 읽어 $O = PV$ 계산
각 연산이 끝날 때마다 결과를 HBM에 저장(Write)하고, 다음 연산이 시작될 때 다시 불러오는(Load) 과정이 반복됩니다.
문제는 중간 결과물인 $S$와 $P$가 $N \times N$ 크기의 거대한 행렬이라는 점입니다. 시퀀스 길이 $N = 4096$이면 이 행렬만 약 64MB(FP32 기준)에 달하며, SRAM(약 20MB)에 담을 수 없어 HBM에 쓰고 다시 읽어야 합니다. Softmax, Masking 등은 element-wise 연산(Arithmetic Intensity ≈ 1)이므로, 행렬 곱셈으로 확보한 높은 연산 효율을 이 HBM 왕복에서 모두 낭비하게 됩니다.
Kernel fusion은 이 중간 단계의 write/load를 줄이기 위해, 여러 연산을 더 적은 수의 커널로 합쳐 중간 텐서를 HBM에 저장하지 않고 SRAM에서 연산되도록 최적화하였습니다.
HBM에 저장하지 않는다는 것은 VRAM 메모리를 점유하지 않는다는 뜻이기도 합니다. 덕분에 Kernel Fusion이 잘 적용된 모델은 같은 하드웨어에서도 더 큰 배치 사이즈(Batch Size)나 더 긴 시퀀스 길이를 감당할 수 있게 됩니다.
Tiling
FlashAttention은 바로 이 Kernel Fusion을 Attention 연산 전체에 적용합니다. \(N \times N\) 행렬을 HBM에 생성하지 않고, 대신 \(Q\), \(K\), \(V\)를 SRAM에 들어갈 만큼의 작은 블록(타일)으로 분할합니다. 그리고 MatMul → Softmax → MatMul을 하나의 커널 안에서 블록 단위로 한꺼번에 수행합니다.
직관적으로는 다음과 같습니다.
- HBM → SRAM으로 \(K_j, V_j\) 타일을 가져온 뒤,
- SRAM에서 \(Q_i\) 타일과 곱해 \(S_{ij}=Q_iK_j^T/\sqrt{d_k}\) 를 만들고,
- 곧바로 softmax를 적용한 가중치로 \(V_j\)를 곱해 \(O_i\)에 누적합니다.
즉, \(S\)나 \(P\) 같은 \(N \times N\) 중간 행렬을 HBM에 저장하지 않고, SRAM에서 생성된 즉시 다음 연산의 입력으로 소비되고 사라집니다. 그래서 HBM 왕복(write/load)이 크게 줄어듭니다.
그런데 여기서 한 가지 난제가 생깁니다. Softmax는 특정 행의 모든 원소를 고려하여 확률 값을 계산합니다.
\[P_{i,j} = \text{softmax}(S_{i,j}) = \frac{\exp(S_{i,j})}{\sum_{t=1}^{N} \exp(S_{i,t})}\]위 수식에서 볼 수 있듯이, 분모에는 해당 행의 전체 열($t=1$부터 $N$까지)에 대한 지수 합이 필요합니다. 하지만 Tiling 방식은 데이터를 작은 블록 단위로 순회하기 때문에 다음과 같은 난관에 봉착합니다.
- 최댓값의 불확실성: 지수 함수($\exp$)의 수치적 안정성을 위해 보통 입력값에서 최댓값을 빼주는 과정이 필요한데, 아직 보지 않은 타일에 더 큰 값이 있을지 알 수 없습니다.
- 분모의 미완성: 모든 타일을 다 읽기 전까지는 분모인 $\sum \exp(S_{i,t})$ 값을 확정할 수 없으므로, 개별 원소의 최종 확률값을 미리 계산할 수 없습니다.
이 문제를 해결하는 기법이 바로 Online Softmax입니다. 데이터를 한꺼번에 보지 않고 타일 단위로 순회하면서도, 최종적으로는 전체를 계산한 것과 수학적으로 동일한 결과를 산출합니다.
Online-Softmax
Standard Softmax는 전체 데이터를 다 본 뒤에 최댓값($m$)과 분모 합($L$)을 구하지만, Online Softmax는 데이터를 순차적으로 읽으면서 이 값들을 실시간으로 업데이트합니다.
전체 값 $x$에 대해 Softmax 분모는 수치적 안정성을 위해 최댓값 $m$을 빼서 다음과 같이 계산합니다.
\[Z = e^{m} \sum_{j} e^{x_j - m}\]데이터를 블록 $B_1, B_2, \dots$ 단위로 읽는다고 가정할 때, $i$번째 블록까지의 상태를 관리합니다.
- $m^{(i)}$: $i$번째 블록까지의 최댓값 (Local Max)
- $d^{(i)}$: $i$번째 블록까지의 보정된 지수 합 (Running Sum)
새로운 블록 $B_{new}$가 들어오면 다음과 같이 값을 갱신합니다:
-
최댓값 갱신:
$m^{(new)} = \max(m^{(old)}, \max(B_{new}))$ -
분모(지수 합) 보정 및 합산:
\[d^{(new)} = d^{(old)} \times \exp(m^{(old)} - m^{(new)}) + \sum \exp(B_{new} - m^{(new)})\]
새로운 최댓값 $m^{(new)}$에 맞춰 기존의 합($d^{(old)}$)을 보정하고 새로운 데이터를 더합니다. -
결과값 보정:
출력 결과(Attention Output) 역시 새로운 분모 비율에 맞춰 실시간으로 보정합니다.
Example
한 행의 Score가 $[1, 2, 5, 3]$일 때, Block 1: $[1, 2]$ 과, Block 2: $[5, 3]$라고 가정합니다.
일반적인 Softmax 연산은 아래와 같이 이뤄집니다.
- 최댓값 확인: $m = 5$
- 지수 합 계산 ($Z’$): \(Z' = \sum e^{x-m} = e^{1-5} + e^{2-5} + e^{5-5} + e^{3-5}\)
- 수치 계산:
- $e^{-4} \approx 0.0183$
- $e^{-3} \approx 0.0498$
- $e^{0} = 1$
- $e^{-2} \approx 0.1353$
결과적으로 $Z’ = 0.0183 + 0.0498 + 1 + 0.1353 = \mathbf{1.2034}$ 이 됩니다.
이와 대비하여 Online-Softmax의 경우, Block들을 순회해가면서 최대값을 갱신하여 지수합을 계산합니다.
- Block 1 최댓값: $m^{(old)} = 2$
- Block 1 지수 합: \(d^{(old)} = e^{1-2} + e^{2-2} = 0.3679 + 1 = \mathbf{1.3679}\)
- Block 2 최댓값: $m^{(new)} = \max(2, 5) = 5$
- Block 2 지수 합: \(d^{(block2)} = e^{5-5} + e^{3-5} = 1 + 0.1353 = \mathbf{1.1353}\)
이후, 최대값 기준을 $2$에서 $5$로 바꾸면 모든 기존 항에 동일한 배율이 적용됩니다.
\[e^{x-5} = e^{x-2} \cdot e^{2-5}\]따라서 기존 합계에 $e^{2-5}$만 곱하면 즉시 보정됩니다.
- 보정 계수: $e^{2-5} = e^{-3} \approx 0.0498$
- 보정된 기존 합: $d^{(old)}_{\text{rescaled}} = 1.3679 \times 0.0498 = \mathbf{0.0681}$
$e^{1-5} + e^{2-5} = 0.0183 + 0.0498 = 0.0681$ 로 일치합니다.
이를 통해 누적된 값은 아래와 같이 업데이트 됩니다.
\[d^{(new)} = d^{(old)}_{\text{rescaled}} + d^{(block2)} = 0.0681 + 1.1353 = \mathbf{1.2034}\]Combination in Modern LLMs
이 글에서 다룬 기법들은 서로 배타적이지 않으며, 실제 프로덕션 환경에서는 함께 조합되어 사용됩니다. 대표적인 예로, OpenAI의 gpt-oss-120b는 모델 아키텍처 차원에서 다음 최적화를 결합합니다.
| 구성 요소 | 적용 기법 | 효과 |
|---|---|---|
| Attention | GQA ($H=64$, $H_{\mathrm{kv}}=8$) | KV cache 규모 $\approx H/H_{\mathrm{kv}}=8\times$ 절감 |
| FFN | MoE (experts $=128$, top-$k=4$) | 총 $\approx 116.8$B 중 토큰당 $\approx 5.1$B 활성화 |
서빙(추론) 단계에서는 위와 같은 모델 설계 최적화와 별개로, FlashAttention 커널이나 vLLM의 PagedAttention 같은 런타임/엔진 최적화를 선택적으로 적용해 HBM 트래픽과 KV cache 관리 비용을 추가로 낮출 수 있습니다.
Conclusion
LLM 추론에서 Attention 메커니즘의 메모리 병목은 단일 기법으로 해결되지 않습니다. 이 글에서 살펴본 핵심을 정리하면 다음과 같습니다:
| 기법 | 공략 지점 | 핵심 원리 | 주요 효과 |
|---|---|---|---|
| MQA | KV Cache 크기 | Key-Value를 전체 공유 | 메모리 $h$배 감소 |
| GQA | KV Cache 크기 | 그룹별 Key-Value 공유 | 품질 유지 + 상당한 메모리 절감 |
| FlashAttention | HBM IO 횟수 | Tiling + Online Softmax | 속도 2~3배 향상, 메모리 $O(N^2) \rightarrow O(N)$ |
다음 글에서는 이 글에서 다루지 않은 MoE(Mixture of Experts)를 통한 활성화 파라미터 최적화와, PagedAttention(vLLM)을 통한 KV Cache 메모리 관리 최적화를 다루겠습니다. 이 두 기법은 Attention 메커니즘 자체보다는 모델 아키텍처와 서빙 인프라 차원의 최적화에 해당하며, GQA와 FlashAttention과 결합했을 때 대규모 LLM의 효율적인 프로덕션 서빙이 완성됩니다.
Comments