Service Networking
앞서 Pod Networking에서 VPC CNI가 Pod마다 고유한 IP를 부여하고 그 IP로 직접 통신하는 방식을 살펴봤습니다. Pod은 재시작하면 새 IP를 받기 때문에, 클라이언트가 Pod IP를 직접 사용하면 Pod이 재시작될 때마다 연결이 끊깁니다.
Kubernetes는 이 문제를 Service로 해결합니다. Service는 고정된 ClusterIP를 제공하고, kube-proxy가 이 ClusterIP를 현재 실행 중인 Pod IP로 변환합니다. Pod 안에서 IP 대신 my-svc.my-ns 같은 이름으로 접근할 수 있는 것은 CoreDNS가 Service 이름을 ClusterIP로 변환해주기 때문입니다.
Service Discovery
ClusterIP는 실제 네트워크 인터페이스에 바인딩되지 않는 가상 주소입니다. kube-proxy가 이 가상 IP를 실제 Pod IP로 변환하는 규칙을 모든 노드에 설치하고, ClusterIP를 목적지로 나가는 패킷은 살아있는 Pod IP 중 하나로 DNAT됩니다.
kube-proxy는 DaemonSet으로 모든 노드에서 실행되며, API 서버의 Service와 EndpointSlice 변경을 감지해 각 노드의 규칙을 갱신합니다. 모든 노드가 동일한 규칙을 가지므로 NodePort 트래픽은 어느 노드로 들어와도 목적지 Pod에 도달합니다.
SNAT 처리는 서비스 타입에 따라 달라집니다.
- ClusterIP: 클러스터 내부 트래픽만 처리하므로 SNAT가 불필요합니다.
- NodePort: 외부 클라이언트가
Node IP:Port로 요청하면 해당 노드에서 DNAT되어 Pod으로 전달됩니다. 이때 SNAT 없이 Pod이 클라이언트에 직접 응답하면, 클라이언트는 자신이 요청한 노드 IP가 아닌 Pod IP로부터 응답을 받아 패킷을 드롭합니다. 이를 방지하기 위해 출발지 IP를 노드 IP로 SNAT하여 리턴 패킷이 해당 노드를 거쳐 클라이언트에게 돌아가도록 합니다. 단,externalTrafficPolicy: Local로 설정하면 SNAT를 생략할 수 있으며, 이 경우 클라이언트의 실제 IP가 Pod까지 전달됩니다.
Proxy Modes
kube-proxy가 규칙을 구현하는 방식은 모드에 따라 다릅니다. EKS는 기본적으로 iptables를 사용합니다.
배경 지식이 있으면 아래 내용을 이해하기 좀 더 수월합니다.
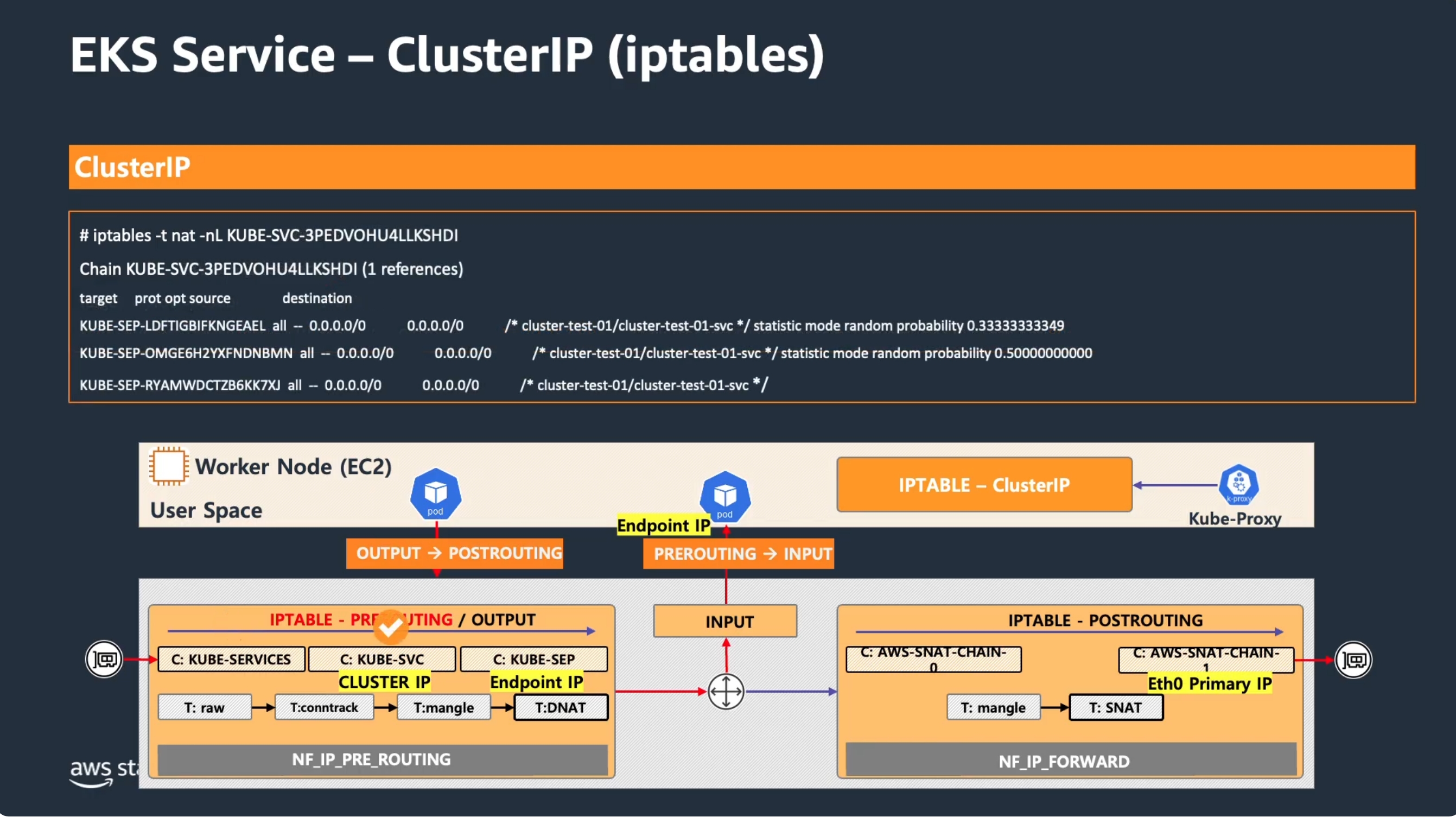
패킷이 ClusterIP를 향해 나가면 커널 netfilter의 PREROUTING 훅에서 nat 테이블의 세 체인을 순서대로 거칩니다.
KUBE-SERVICES— 목적지 ClusterIP가 어느 Service인지 식별KUBE-SVC-*— 해당 Service의 엔드포인트 중 하나를 확률 기반으로 선택 (로드밸런싱)KUBE-SEP-*(Service EndPoint) — 선택된 Pod IP로 DNAT
 Source: EKS Networking Deep Dive
Source: EKS Networking Deep Dive
실제 규칙을 확인하면 체인 계층 구조가 명확하게 보입니다.
# 1. PREROUTING → KUBE-SERVICES 진입
iptables -t nat -S PREROUTING
# -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
# 2. KUBE-SERVICES → ClusterIP:Port에 해당하는 Service 체인으로 분기
iptables -t nat -S KUBE-SERVICES
# -A KUBE-SERVICES -d 10.200.1.111/32 -p tcp --dport 9000 -j KUBE-SVC-GQ7VJ6DFEMRF2SE7
# 3. KUBE-SVC → 확률 기반 엔드포인트 선택 (Pod 3개 예시)
iptables -t nat -S KUBE-SVC-GQ7VJ6DFEMRF2SE7
# -A KUBE-SVC-... -m statistic --mode random --probability 0.33333 -j KUBE-SEP-A ← 1/3 확률
# -A KUBE-SVC-... -m statistic --mode random --probability 0.50000 -j KUBE-SEP-B ← 남은 2개 중 1/2
# -A KUBE-SVC-... -j KUBE-SEP-C ← 나머지
# 4. KUBE-SEP → 실제 Pod IP:Port로 DNAT
iptables -t nat -S KUBE-SEP-A
# -A KUBE-SEP-A -p tcp -j DNAT --to-destination 172.16.158.1:80
확률이 0.333 → 0.500 → 1.000으로 역산되는 이유는, 체인을 순서대로 평가할 때 각 Pod이 균등하게 1/3 확률을 받도록 계산하기 때문입니다.
DNAT 후 연결 정보는 커널의 conntrack(connection tracking)에 기록됩니다. 리턴 패킷은 별도 규칙 없이 conntrack이 자동으로 역변환(Pod IP → ClusterIP)해 클라이언트에게 전달합니다.
DNAT으로 목적지가 실제 Pod IP로 바뀐 패킷은 Pod-to-Pod Communication에서처럼 Policy Routing으로 전달됩니다. kube-proxy의 iptables 규칙이 ClusterIP를 Pod IP로 변환하고, VPC CNI의 Policy Routing이 그 Pod IP를 올바른 인터페이스로 내보내는 역할을 각자 맡습니다.
NodePort는 KUBE-SERVICES 뒤에 KUBE-NODEPORTS 체인이 추가되어 외부 트래픽을 받습니다.
Performance Tuning
Pod과 Service 수가 수만 개에 달하는 클러스터에서는 iptables 규칙도 수만 건이 됩니다. 이 규모에서 kube-proxy가 규칙을 자주 재작성하면 갱신 지연이 누적될 수 있습니다. 아래 두 파라미터로 조정합니다.
-
minSyncPeriod— iptables 규칙 재동기화 최소 간격으로 기본값1s권장됩니다.0s로 설정하면 Endpoint 변경마다 즉시 재작성합니다. 100개 Pod Deployment를 삭제하면 Pod 하나씩 종료될 때마다 100번 재작성이 발생하고, 수만 건의 규칙이 있는 클러스터에서 한 번 재작성에 수 초가 걸리면 kube-proxy가 계속 뒤처진 상태로 반복 재작성합니다.1s로 설정하면 1초 안에 발생한 변경을 한 번에 배치 처리해 재작성 횟수가 크게 줄어듭니다. -
syncPeriod— 외부 컴포넌트가 iptables 규칙을 변경했을 때 감지하는 주기로 기본값 사용을 권장합니다.
# 현재 설정 확인
kubectl describe cm -n kube-system kube-proxy-config | grep -A5 'iptables:'
# iptables:
# minSyncPeriod: 1s
# syncPeriod: 30s
iptables 이전 — userspace 모드
초기 userspace 모드에서는 kube-proxy가 직접 소켓을 열어 패킷을 받아 Pod으로 전달했습니다. 패킷마다 커널하고 유저스페이스 간 전환이 발생해 처리량이 낮았고, kube-proxy가 재시작되면 트래픽도 잠시 끊겼습니다. iptables 모드는 패킷 처리를 커널에 위임해 이 문제를 해결했습니다.
iptables와 동일한 netfilter subsystem을 사용하지만, 규칙 설치에 nftables API를 씁니다. 수만 개 Service 규모에서 규칙 처리와 업데이트 속도가 iptables보다 빠릅니다.

Kubernetes 1.29 Alpha → 1.31 Beta를 거쳐 1.33에서 GA가 되었습니다. EKS에서 전환하려면 kube-proxy ConfigMap의 mode를 nftables로 변경합니다.
IPVS 모드는 커널 로드밸런서와 hash table 기반 O(1) 조회로 대규모 클러스터에서 iptables보다 빠른 성능을 제공했습니다. 다만 Linux 배포판별 커널 모듈 지원이 달라 유지 관리가 어려웠고, nftables가 성능 격차를 좁히면서 v1.35에서 deprecated, v1.36에서 제거되었습니다.
위 세 모드가 모두 netfilter 계층에 의존하는 것과 달리, BPF 프로그램이 커널 XDP 훅에서 패킷을 직접 처리해 netfilter를 우회합니다. Cilium 같은 별도 CNI 플러그인에서 구현되며, EKS 기본 VPC CNI 환경에서는 사용하지 않습니다.
CoreDNS
Pod의 /etc/resolv.conf는 nameserver로 kube-dns Service의 ClusterIP를 가리킵니다. DNS 쿼리 자체도 위에서 설명한 kube-proxy DNAT을 거쳐 CoreDNS Pod에 도달합니다. kube-proxy가 정상 동작하지 않으면 ClusterIP 접근뿐 아니라 DNS 자체가 먼저 끊깁니다.
Corefile
Corefile은 CoreDNS의 설정 파일로, 플러그인을 선언하는 방식으로 DNS 동작을 정의합니다. EKS가 기본으로 배포하는 구성입니다.
.:53 {
errors # 에러 로깅
health { lameduck 5s } # /health 엔드포인트, 종료 전 5초 유예
ready # /ready 엔드포인트 — 요청 처리 준비 완료 시에만 트래픽 수신
kubernetes cluster.local in-addr.arpa ip6.arpa { # 클러스터 내부 DNS (cluster.local + 역방향 조회)
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153 # Prometheus 메트릭 노출
forward . /etc/resolv.conf # 클러스터 외부 쿼리는 노드의 업스트림 DNS로 포워딩
cache 30 # 응답 30초 캐시
loop # 포워딩 루프 감지
reload # Corefile 변경 시 자동 재로드
loadbalance # 다중 A 레코드를 라운드로빈으로 순서 변경
}
lameduck 5s는 CoreDNS Pod이 SIGTERM을 받은 뒤 실제 종료 전 5초간 DNS 쿼리에 정상 응답을 유지하는 Graceful Shutdown 메커니즘입니다. Pod이 삭제되면 Kubernetes는 SIGTERM 전송과 동시에 EndpointSlice에서 해당 Pod을 제거하고, kube-proxy는 이를 반영해 iptables를 갱신합니다. 이 갱신이 완료되기 전까지 일부 노드는 여전히 종료 중인 CoreDNS Pod으로 DNS 쿼리를 보낼 수 있는데, lameduck은 이 전환 구간 동안 CoreDNS가 계속 응답할 수 있도록 실제 프로세스 종료를 지연합니다.
iptables 탭의 Performance Tuning에서 다룬 것처럼, 대규모 클러스터에서 kube-proxy의 iptables 갱신은 수 초씩 지연될 수 있습니다. lameduck 시간이 이 갱신 지연보다 짧으면 CoreDNS가 종료된 후에도 일부 노드가 해당 Pod으로 DNS 쿼리를 보내는 구간이 생깁니다.
Tip
Pod 수가 많은 클러스터는 lameduck 30s로 늘리는 것을 권장합니다.
lameduck이 Pod 하나의 종료 구간을 안전하게 만든다면, PDB(Pod Disruption Budget)는 여러 CoreDNS Pod이 동시에 꺼지는 상황 자체를 막습니다. EKS managed add-on(v1.9.3-eksbuild.6 이상)은 PDB를 기본 적용해 노드 드레인 시 CoreDNS Pod이 동시에 종료되지 않도록 보호합니다. 클러스터에 이미 커스텀 PDB가 있으면 add-on 업그레이드가 실패할 수 있으며, 이때는 기존 PDB를 삭제하거나 충돌 해결 옵션으로 덮어쓰기를 선택해야 합니다.1