Overview
오토스케일링은 워크로드 변동에 따라 컴퓨팅 리소스를 탄력적으로 관리하는 메커니즘입니다. 수동 운영 시 발생하는 자원 낭비와 가용성 저하 문제를 자동화로 해결하는 데 목적이 있습니다.
Kubernetes는 이를 Pod과 Node 두 계층으로 나누어 처리합니다. 부하 발생 시 Pod 확장이 우선적으로 수행되며, 기존 Node에 더 이상 Pod을 배치할 수 없는 시점에 Node 확장이 뒤따르는 유기적인 구조를 가집니다.
| Layer | Tool |
|---|---|
| Pod | HPA, VPA, KEDA |
| Node | Cluster Autoscaler, Karpenter, EKS Auto Mode |
Pod Scaling
Pod 스케일링은 수평, 수직 두 방향으로 이루어집니다. Horizontal Scaling은 replica 수를 늘려 처리 용량을 확보하며 Stateless 워크로드에 적합합니다. Vertical Scaling은 replica 수는 그대로 두고 각 Pod의 CPU/Memory resource request를 늘리며, 노드 인스턴스 타입의 최대 사양이 상한입니다.
HPA(Horizontal Pod Autoscaler)는 메트릭을 기반으로 Deployment의 replica 수를 자동 조정합니다. kube-controller-manager 내부에서 15초 간격으로 동작하며, 현재 메트릭 값과 목표값의 비율로 필요한 replica 수를 계산합니다. CPU/Memory 외에 Custom, External 메트릭도 지원합니다.
VPA(Vertical Pod Autoscaler)는 Pod의 실제 리소스 사용량을 분석해 resources.requests를 자동 조정합니다. Kubernetes 내장 기능이 아니라 별도 add-on으로 설치해야 합니다. 추천값을 적용할 때는 기존 Pod을 evict하고 새 Pod으로 교체합니다.
KEDA(Kubernetes Event-Driven Autoscaling)는 SQS 큐 길이, Kafka consumer lag 같은 외부 이벤트를 트리거로 Pod을 스케일링합니다. 내부적으로 HPA를 생성하고 관리하므로 기존 Kubernetes 스케줄러와의 통합은 그대로 유지됩니다.
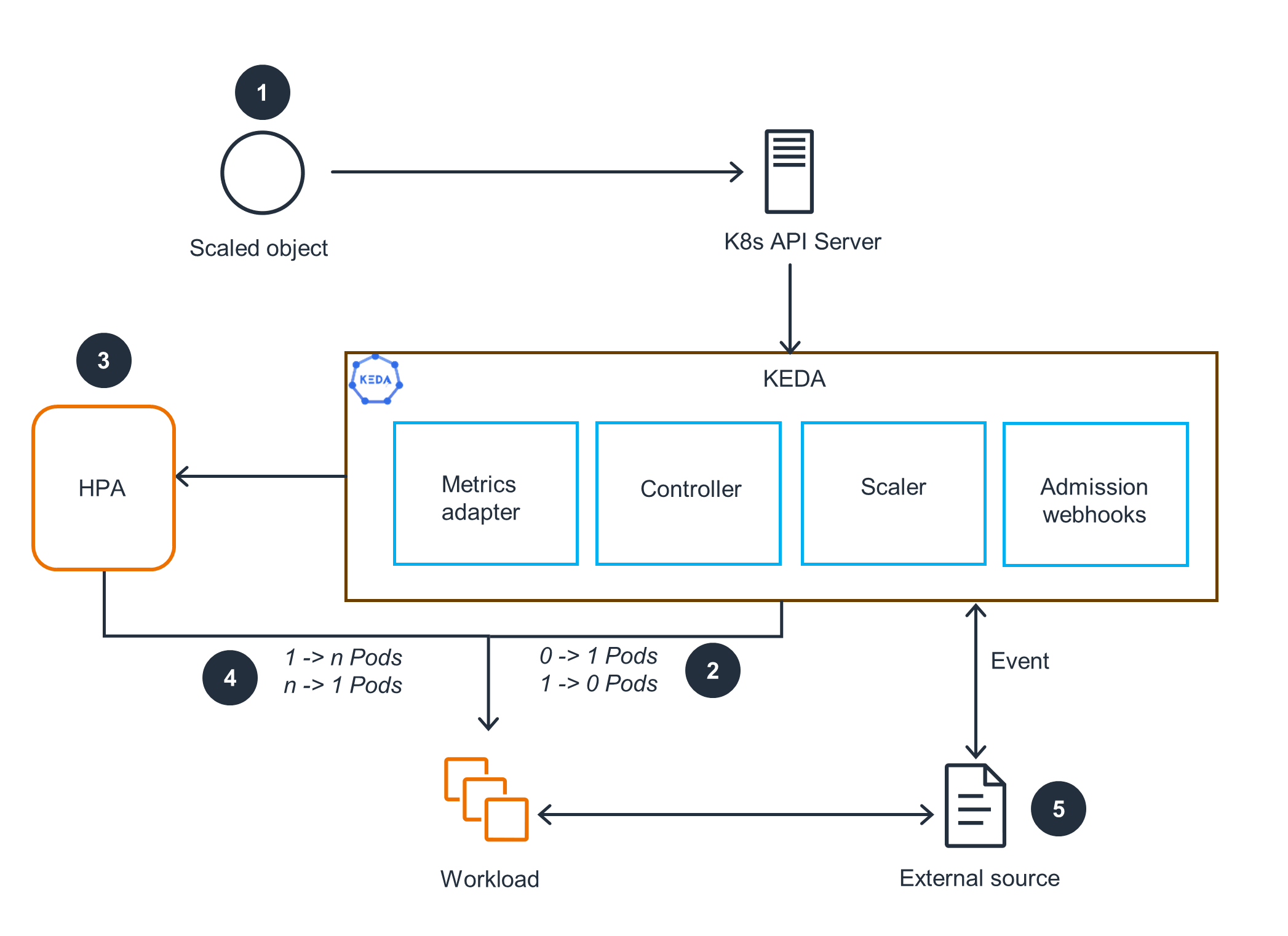
Node Scaling
노드 스케일링은 Pending 또는 Unschedulable 상태의 Pod이 발생했을 때 새 노드를 프로비저닝하고, 유휴 노드를 종료합니다. EKS에서는 데이터 플레인 컴퓨팅 옵션에 따라 선택 가능한 방식이 제한됩니다.
Pending Pod이 발생하면 ASG(Auto Scaling Group)의 DesiredCapacity를 조정해 EC2 인스턴스를 추가하고, 유휴 노드를 제거합니다. ASG 기반 EKS 노드 그룹에서 동작하며 AWS Auto Scaling 정책과 함께 사용됩니다.
Unschedulable Pod의 resource request를 분석해 EC2 Fleet API로 적합한 인스턴스 타입을 선택하고 1분 이내에 직접 프로비저닝합니다. ASG를 거치지 않고 EC2를 직접 제어하므로 CAS보다 빠릅니다.
노드 프로비저닝과 관리를 EKS에 완전히 위임합니다.
EKS Auto Scaling Summary
EKS에서 사용하는 주요 오토스케일링 도구를 트리거, 동작, 대상 기준으로 비교합니다.
| Trigger | Action | Target | |
|---|---|---|---|
| HPA | Pod 메트릭 초과 | 신규 Pod Provisioning | Pod Scale Out |
| VPA | Pod 자원 부족 | Pod 교체(자동/수동) | Pod Scale Up |
| CAS | Pending Pod 존재 | 신규 노드 Provisioning | Node Scale Out |
| Karpenter | Unschedulable Pod 감지 | EC2 Fleet으로 노드 생성 | Node Scale Up/Out |
Scaling Theory
Kubernetes 컨트롤 플레인에 가해지는 부하는 클러스터 크기보다 단위 시간당 오브젝트가 변경되는 속도에 비례합니다. 오토스케일링 전략을 설계할 때는 노드 수나 Pod 수 같은 절대값이 아니라 변화율(churn rate)을 기준으로 판단해야 합니다.1
Churn Rate
5,000개 노드에 고정된 Pod이 배치된 클러스터보다, 1,000개 노드에서 1분 내 10,000개 단기 Job이 반복적으로 생성되고 삭제되는 클러스터가 API 서버에 훨씬 높은 부하를 줍니다. 확장성 문제를 진단할 때는 절대 노드 수보다 5분 간격 QPS를 먼저 확인해야 합니다.
Kubelet, Scheduler, Controller Manager는 각각 QPS 기반 보호 메커니즘을 가지고 있습니다. 한 컴포넌트의 병목을 해소하면 downstream 컴포넌트로 부하가 전파될 수 있으므로, 변경 후 upstream과 downstream 양쪽을 모니터링해야 합니다.
Pods Per Node
kubelet의 기본 상한은 110 pods/node이지만, 워크로드 복잡도에 따라 실제 한계는 달라집니다. PLEG(Pod Lifecycle Event Generator)는 kubelet이 컨테이너 런타임의 상태 변화를 감지하는 루프로, 이 루프의 처리 시간이 노드 과부하의 핵심 지표입니다. kubelet_pleg_relist_duration_seconds 메트릭이 지속적으로 높으면 해당 노드의 Pod 수를 줄이거나 에러 조건을 해결하여 재시도 부하를 낮춰야 합니다.
110 pods/node는 설정 상한일 뿐이며, 워크로드에 따라 그 이전에 노드가 과부하될 수 있습니다. PLEG 메트릭 기반으로 노드별 실제 한계를 판단합니다.
Error and Retry Pressure
에러가 발생한 오브젝트는 Kube Controller Manager가 반복적으로 reconcile을 시도합니다. 재시도마다 API 서버에 요청이 발생하므로, 에러가 누적되면 정상 요청까지 처리 지연이 발생합니다.
Resolve errors before scaling
대규모 스케일 아웃이나 클러스터 업그레이드 전에 기존 에러 상태의 오브젝트를 먼저 정리해야 합니다. 에러가 누적된 상태에서 부하를 추가하면 문제 원인 분석이 어려워집니다.
Control Plane Scalability
API Priority and Fairness (APF)
API 서버가 동시에 처리할 수 있는 요청 수에는 상한이 있습니다. 이 상한을 넘으면 API 서버는 HTTP 429(Too Many Requests)를 반환합니다. APF는 이 제한된 용량을 요청 유형별로 나누어, 특정 클라이언트의 대량 요청이 다른 요청을 밀어내지 않도록 보호하는 메커니즘입니다.2
동작 흐름은 다음과 같습니다.
- API 서버에 요청이 도착하면 FlowSchema가 요청의 속성(사용자, API 그룹, 네임스페이스 등)을 보고 어떤 priority level에 속하는지 분류합니다.
- 해당 priority level에 여유 용량이 있으면 즉시 처리합니다.
- 여유가 없으면 큐에 대기합니다. 대기 중 용량이 확보되면 처리되고, 타임아웃되거나 큐가 가득 차면 429를 반환합니다.
각 priority level이 사용할 수 있는 동시 요청 수는 PriorityLevelConfiguration에서 비율로 정의됩니다. API 서버의 전체 용량이 늘어나면 각 level의 용량도 같은 비율로 함께 늘어납니다. EKS는 클러스터 규모에 따라 API 서버의 총 용량을 자동으로 확장하지만, 구체적인 확장 기준이나 각 level의 seat 수는 공개되어 있지 않습니다.
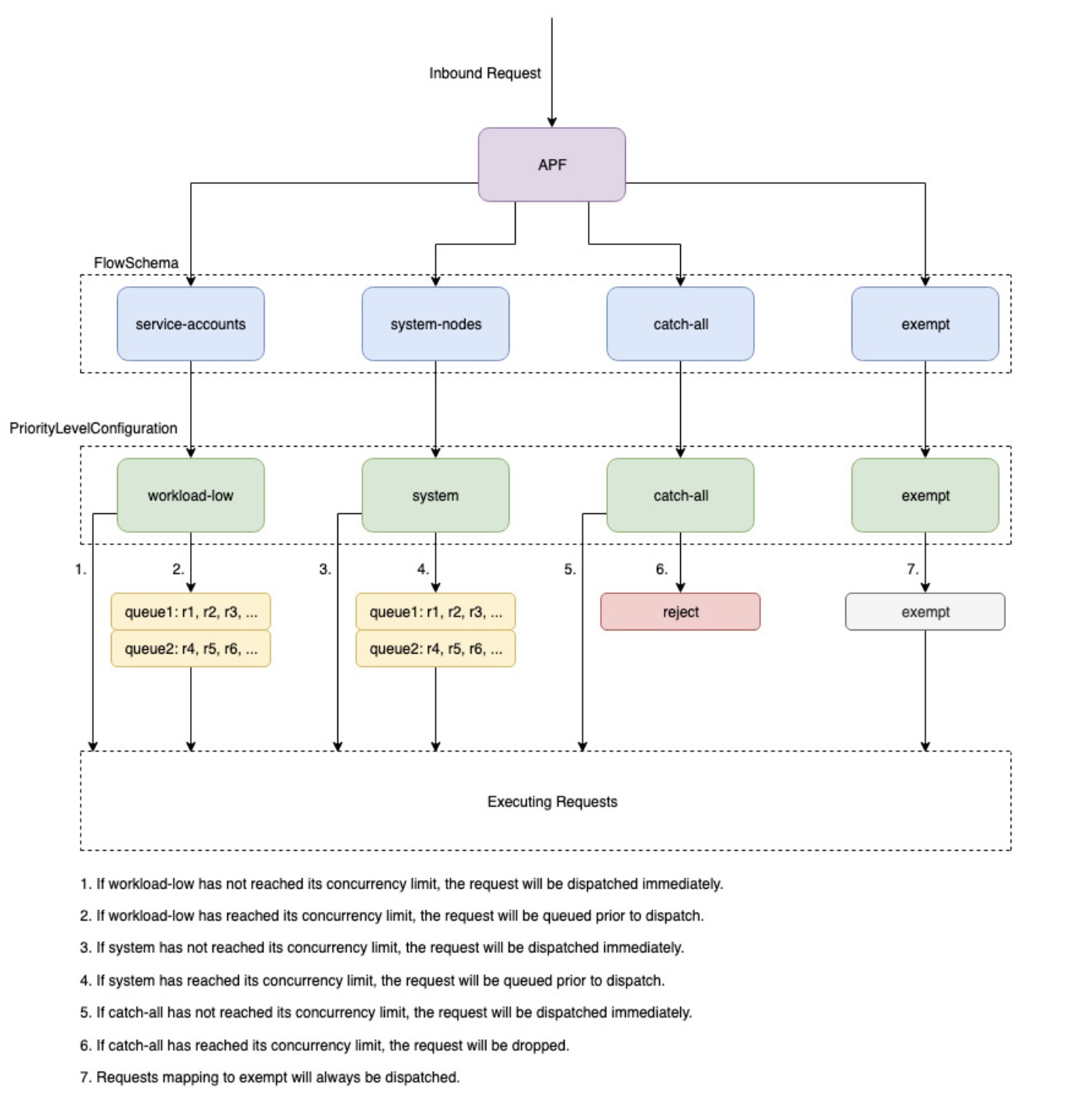 Source: AWS EKS Best Practices — Scale Control Plane
Source: AWS EKS Best Practices — Scale Control Plane
EKS의 FlowSchema와 PriorityLevelConfiguration 구성은 Kubernetes 버전에 따라 달라질 수 있으며, EKS는 Kubernetes 기본 구성에 자체 FlowSchema(eks-exempt, eks-workload-high)를 추가합니다. 요청이 도착하면 API 서버는 Precedence가 낮은 FlowSchema부터 순서대로 매칭을 시도하고, 매칭된 FlowSchema의 priority level로 요청을 분류합니다.
Optimize API server calls
kubectl 사용 시 --cache-dir로 클라이언트 캐시를 활성화하고, --disable-compression=true를 kubeconfig에 설정하면 API 서버의 CPU 오버헤드를 줄일 수 있습니다.
AWS Service Quotas
오토스케일링은 EC2, VPC, ELB 등 여러 AWS 서비스를 사용하므로, 서비스 할당량이 스케일링의 실질적 상한이 됩니다. 기본 할당량은 대부분 낮게 설정되어 있어, 프로덕션 환경에서는 사전에 상향 요청이 필요합니다.3
| Service | Quota | Default | Impact |
|---|---|---|---|
| EC2 On-Demand vCPU | L-1216C47A | 5 | 워커 노드 확장 직접 제한 |
| EC2 Spot vCPU | L-34B43A08 | 5 | Spot 노드 확장 직접 제한 |
| VPC ENI per region | L-DF5E4CA3 | 5,000 | 노드 수 상한 |
| ALB targets per group | L-7E6692B2 | 1,000 | 서비스 Pod 수 제한 |
| NLB targets per group | L-EEF1AD04 | 3,000 | 서비스 Pod 수 제한 |
| NLB targets per AZ | L-B211E961 | 500 | 멀티 AZ 서비스 제한 |
| IAM Roles per account | L-FE177D64 | 1,000 | 클러스터 및 IRSA 역할 수 제한 |
EC2 API Rate Limiting
대규모 스케일 아웃 시 AssignPrivateIpAddresses, CreateNetworkInterface 등 EC2 mutating API에 throttling이 발생할 수 있습니다. 클러스터 크기를 한 번에 10% 이상 늘리는 급격한 스케일링은 지양하고, 필요 시 rate limit 상향을 요청합니다.